
In baking, the “first proof” is that critical moment when you let the dough rise as a single mass before shaping it into loaves. If the yeast doesn’t perform here, you don’t get bread; you get a brick.
On February 6, a coalition of the world’s most formidable mathematical minds—including Fields Medalist Martin Hairer, MacArthur Fellow Daniel Spielman, and Stanford’s Mohammed Abouzaid—dropped a bombshell on arXiv. Their paper, titled First Proof: Assessing AI on Research-Level Mathematics, isn’t just another benchmark. It’s a physical wall. While the industry was busy popping champagne over high scores on standard math contests, these researchers quietly pitted GPT-5.2 Pro and Gemini 3.0 Deepthink against ten original, unpublished research problems.
The result? The silicon giants hit a ceiling. A hard one.
This isn’t about solving an IMO (International Mathematical Olympiad) problem where ten thousand similar permutations exist in the training data. This is about research—the messy, undefined, and brutal process of figuring out the question before you even find the answer. And it might just be the most important reality check for the “Superintelligence” narrative in 2026.
The “First Proof” Experiment: No More Scraped Data
We’ve seen a flood of math benchmarks lately. FrontierMath promised “expert-level” problems, and RealMath tried to stay fresh by scraping arXiv for brand-new papers. But First Proof does something fundamentally different and, frankly, more elegant.
The authors didn’t just scrape problems from the web. They reached into their own active research “discard piles” and current projects. They selected ten questions that arose naturally in their own work, were subsequently solved by them (usually with proofs of under five pages), but had never been shared publicly, posted to the internet, or discussed in talks.
The Contamination Kill-Switch
This is the “Data Contamination” nuclear option.
The Problem: When Claude Opus 4.6 or GPT-5.2 Pro aces a math test, there’s always a nagging doubt. Did it reason through the problem, or did it simply encounter a similar structure during its trillion-token training pre-pass? It’s often pattern-matching masquerading as logic.
The Solution: First Proof questions physically did not exist on the public internet until the paper went live.
If an AI solves these, it’s not retrieving. It’s thinking.
Inside the 10 “Unsolvable” Questions
The diversity of these questions is a testament to the bench’s depth. We’re not just looking at high-school algebra here. The list spans the bleeding edge of modern mathematics:
- Stochastic Analysis: (Question 1) Investigating the equivalence of $\Phi^4_3$ measures on a 3D unit torus.
- Representation Theory: (Question 2) Concerning generic irreducible admissible representations of $GL_n(F)$ and Rankin–Selberg integrals.
- Algebraic Combinatorics: (Question 3) Building Markov chains for interpolation Macdonald polynomials.
- Spectral Graph Theory: (Question 6) Defining $\epsilon$-light subsets in Laplacian matrices.
- Symplectic Geometry: (Question 8) Lagrangian smoothings of polyhedral surfaces in $\mathbb{R}^4$.
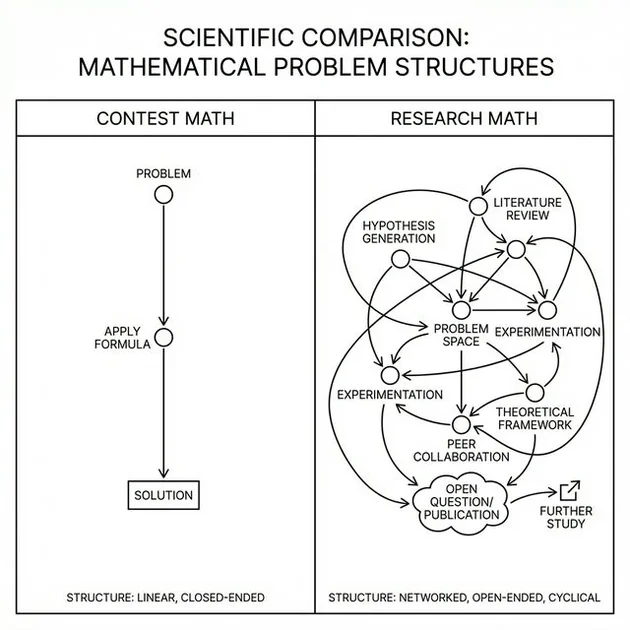
The gap between Contest Math (well-defined, high data availability) and Research Math (novel, zero data availability) is where current AI fails.
When the authors ran preliminary tests on GPT-5.2 Pro and Gemini 3.0 Deepthink, the results were underwhelming. When given a single shot to produce an answer, the systems failed to solve the majority of the questions. Even with the massive reasoning chains we saw in the Gemini 3.0 Deepthink leaks, the sheer novelty of these problems created a barrier that search-based reasoning couldn’t leap.
The Encryption Twist: February 13 is Judgment Day
Here’s where it gets interesting for the practitioners. The authors didn’t just say “AI failed.” They’ve gamified the evaluation.
The answers to the ten questions are currently encrypted and hosted at 1stproof.org. The private key to unlock them won’t be released until February 13, 2026.
This creates a high-stakes, “live fire” window. Right now, as you read this, every AI lab from San Francisco to Beijing has three days to point their best models at these questions. There is no training data. There is no “hidden” answer to find. It is a pure test of logic.
As we saw with the Shannon AI hacker, the “Proof by Exploitation” (or in this case, Proof by Proof) is the only metric that matters. If an agentic swarm can crack Question 7 about fundamental groups before the 13th, the world changes.
The Feb 13th reveal depends on a successful decryption of the solutions set, a “live fire” test for reasoning agents.
What This Means For You
If you’re a developer or a business leader, First Proof is a necessary cold shower regarding the limits of LLM reasoning.
Reasoning vs. Retrieval
We often confuse “fluency” with “intelligence.” When Gemini 3 Flash processes a million tokens, it feels omniscient. But First Proof exposes the cliff. Current models are excellent at Interpolation (finding the path between two known points) but struggle with Extrapolation (creating the path into the void).
The 5-Page Proof Constraint
The authors specifically selected problems with proofs under five pages. This wasn’t to be nice; it was to stay within the effective reasoning window of current models. If an AI can’t maintain a rigorous logical chain for five pages without “context drift,” it cannot function as a standalone researcher. This mirrors the struggles we see in agentic coding swarms—once the project exceeds a certain level of interdependent complexity, the “hallucination tax” becomes too high to pay.
The Bottom Line
First Proof isn’t just a paper; it’s a manifesto. It argues that for AI to truly reach “Expert-Level,” it must move beyond solving puzzles that have been solved before. It must learn to navigate the unknown.
By using unpublished, proprietary problems from active researchers, this group has effectively reset the clock on the “AI is smarter than us at math” narrative. We aren’t there yet. The dough is in the bowl, the yeast is active, but the bake is a long way off.
Watch the clock. February 13 will tell us exactly how high the dough has risen.
FAQ
What is the “First Proof” mathematics benchmark?
It is a set of 10 research-level math problems created by top mathematicians that have never been published online, designed to test AI reasoning without data contamination.
Who created the First Proof benchmark?
The benchmark was developed by a team of researchers from Stanford, Columbia, EPFL, Yale, UC Berkeley, and other leading institutions, including Fields Medalist Martin Hairer.
Did GPT-5.2 and Gemini 3 solve the questions?
In preliminary one-shot tests, the best available systems (GPT-5.2 Pro and Gemini 3.0 Deepthink) failed to solve the majority of the questions correctly.
When will the official answers be released?
The answers are currently encrypted and will be decrypted for the public on February 13, 2026, at 1stproof.org.
Why is this better than previous benchmarks?
Unlike FrontierMath or RealMath, First Proof uses problems that were never online, eliminating the possibility that the model’s training data included the solutions.



