

ChatGPT confidently told a lawyer about six non-existent court cases. Google’s Bard claimed the James Webb Telescope took the first picture of an exoplanet (it didn’t). Claude once invented an entire programming framework that sounded perfect but didn’t exist.
These aren’t bugs. They’re features of how Large Language Models fundamentally work. See our deep dive into AI vs. LLM for why this distinction matters.
Hallucinations are LLMs making up plausible-sounding information that’s factually wrong. And despite billions in investment, no company has solved this problem.
But here’s what they’re not telling you: Hallucinations aren’t accidents. They’re mathematical inevitabilities baked into the architecture of every LLM.
Let me show you exactly why.
The Root Cause: Next-Token Prediction is Guessing
Every LLM, from GPT-4 to Claude to Gemini, works the same way: Predict the next word.
That’s it. That’s the entire mechanism.
How Next-Token Prediction Works
Here’s the process for generating a single token:
- Input: “The capital of France is”
- Model processes the input through billions of parameters
- Generates logits (raw scores) for every possible next word in its vocabulary (~50,000 words)
- Applies softmax function to convert logits into probabilities
- Samples from the probability distribution
- Outputs the selected token: “Paris”
Sounds straightforward. But step 5 is where hallucinations are born.
The Softmax Function: Turning Scores into Probabilities
Before an LLM picks a word, it calculates a “logit” (raw score) for every possible token. These could be any number, positive or negative.
The softmax function converts these into probabilities:
P(token_i) = exp(logit_i / temperature) / Σ exp(logit_j / temperature)
What this means:
– All probabilities sum to 1.0
– Higher logits become higher probabilities
What this means:
– All probabilities sum to 1.0
– Higher logits become higher probabilities
– Temperature controls the sharpness of the distribution
And temperature is where things get interesting.
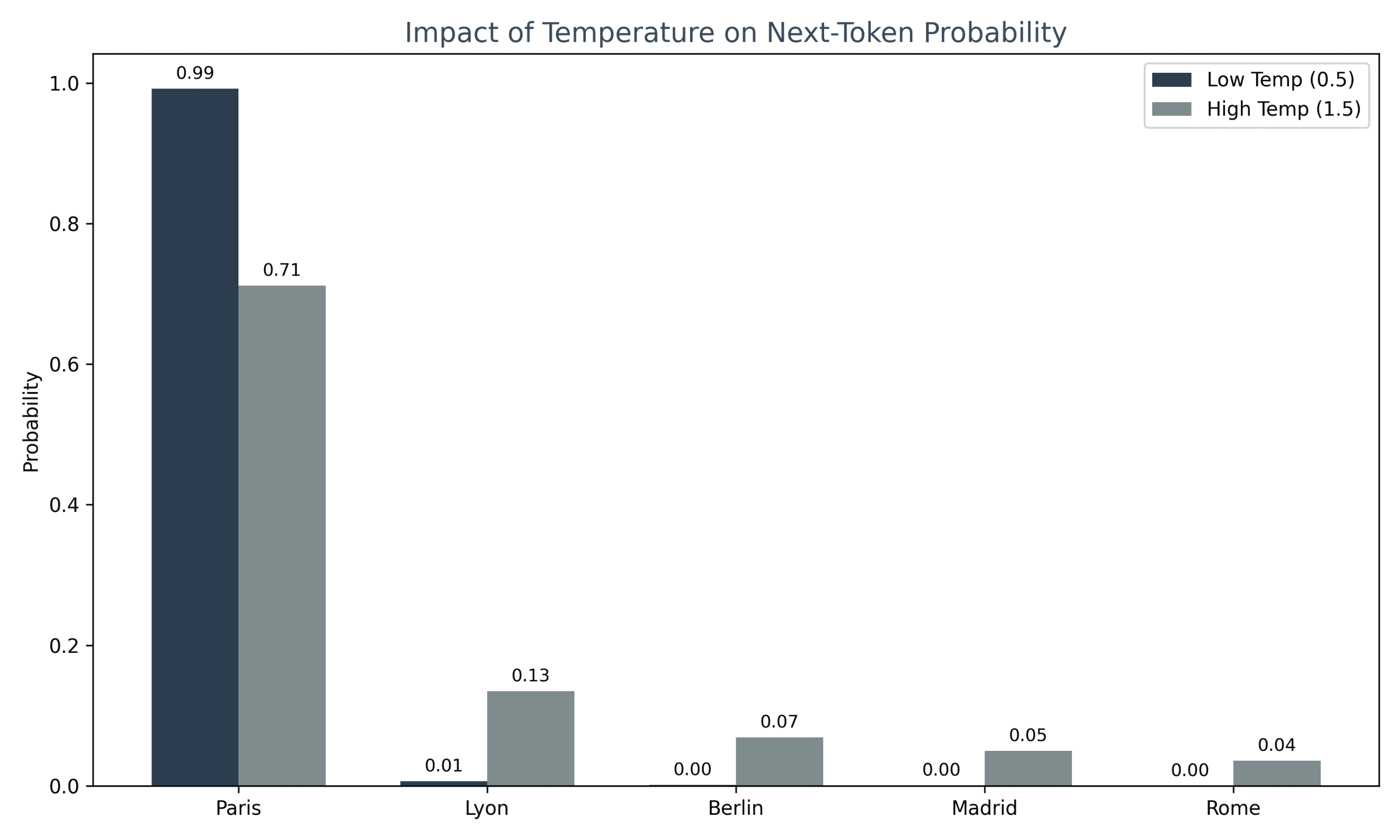
Temperature: The Hallucination Dial
Temperature = 0.0 (Deterministic)
– Model always picks the highest-probability token
– Repetitive, boring output
– Still hallucinates if the most likely token is wrong
Temperature = 0.7 (Balanced)
– Introduces randomness
– More creative outputs
– Moderate hallucination risk
Temperature = 1.5 (Creative)
– Flattens probability distribution
– Frequently samples low-probability tokens
– High hallucination risk (random, incoherent outputs)
The problem: Even at temperature 0, if the training data contains errors or the model learned incorrect patterns, it will confidently output the wrong answer.
Why This Causes Hallucinations
LLMs don’t “know” anything. They’re pattern-matching machines.
When you ask: “Who won the 2025 Nobel Prize in Physics?”
The model:
1. Recognizes the pattern “Nobel Prize in Physics”
2. Retrieves similar patterns from training data
3. Generates the most statistically plausible continuation
If the model’s knowledge cutoff is 2024, it has zero information about 2025. But it doesn’t say “I don’t know.” Instead, it:
- Samples from probability distributions based on past Nobel winners
- Invents a plausible name
- Confidently states it as fact
This is a hallucination.
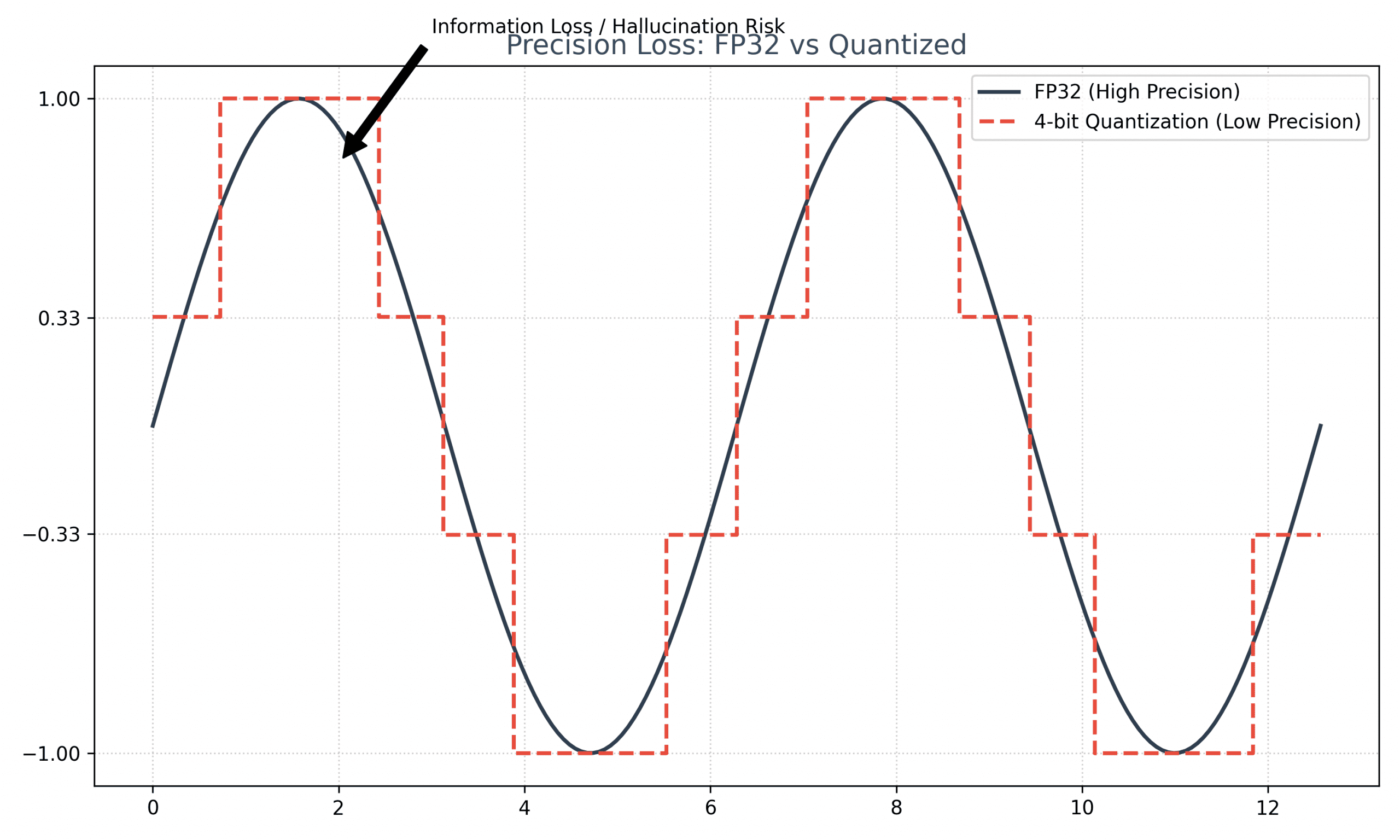
Quantization Makes It Worse
Quantization compresses models by reducing numerical precision. Instead of 32-bit floating-point numbers (FP32), you use 8-bit or 4-bit integers.
The trade-off:
Smaller models (70B parameters: 336 GB → 42 GB with 4-bit quantization)
Faster inference (optimized hardware for low-precision math)
More hallucinations
How Quantization Precision Loss Works
When you reduce precision, you lose information about the probability distribution.
Example: Softmax output for “The capital of France is…”
| Token | FP32 Probability | 8-bit Probability | 4-bit Probability |
|---|---|---|---|
| Paris | 0.89 | 0.88 | 0.85 |
| Lyon | 0.05 | 0.06 | 0.08 |
| Berlin | 0.02 | 0.02 | 0.04 |
| (random) | 0.04 | 0.04 | 0.03 |
Notice the differences:
8-bit: Minimal degradation (Paris still 88% likely)
4-bit: Significant shift (Lyon now 8%, Berlin 4%)
With 4-bit quantization, the model is 3x more likely to pick an incorrect token due to probability distortion. This is the hidden cost of the AI chip efficiency wars where compute speed often overrides factual precision.
Research Findings
- 8-bit quantization: <5% accuracy degradation, minimal hallucination increase
- 4-bit quantization: 10-15% accuracy drop, significant hallucination increase
- TruthfulQA benchmark: TruthfulQA shows that quantized models struggle with tasks designed to catch mimicking human falsehoods.
Why companies still use 4-bit:
Cost: Running Llama 3.1 70B on a single GPU vs. 8 GPUs
Speed: 2-3x faster inference
Deployment: Fits on consumer hardware
The economics favor hallucinations.
Fundamental Constraints LLMs Can’t Escape
Even perfect quantization and infinite compute won’t eliminate hallucinations. Here’s why:
1. Knowledge Cutoff Dates (Parametric Memory)
LLMs store “knowledge” in their weights (parametric memory). This gets frozen at training time.
GPT-4 knowledge cutoff: December 2023
Claude 3.5 Sonnet: August 2024
When you ask about events after the cutoff:
The model doesn’t know it doesn’t know
It fills in gaps with statistically plausible guesses
Result: “Temporal hallucinations”
Why not just retrain constantly?
Training GPT-4 cost ~$100M and months of compute
Retraining weekly is economically impossible
Solution: External tools (web search, RAG)
2. No Real-World Grounding
Humans learn by interacting with the physical world. LLMs learn from text.
Consequences:
LLMs don’t understand causality (just correlation)
No concept of physical constraints (“A car can fit in a shoebox” sounds plausible statistically)
Cannot verify facts (no perception, no experience)
3. Temporal Reasoning
LLMs struggle with:
Event ordering (“Did Einstein discover relativity before or after WWII?”)
Duration (“How long does it take to fly to Mars?”)
Trends over time (“Is climate change accelerating?”)
They conflate past and present facts, leading to anachronistic hallucinations.
How Companies Are Fighting Back
Despite these constraints, OpenAI, Anthropic, and Google have made progress. Here’s what actually works:
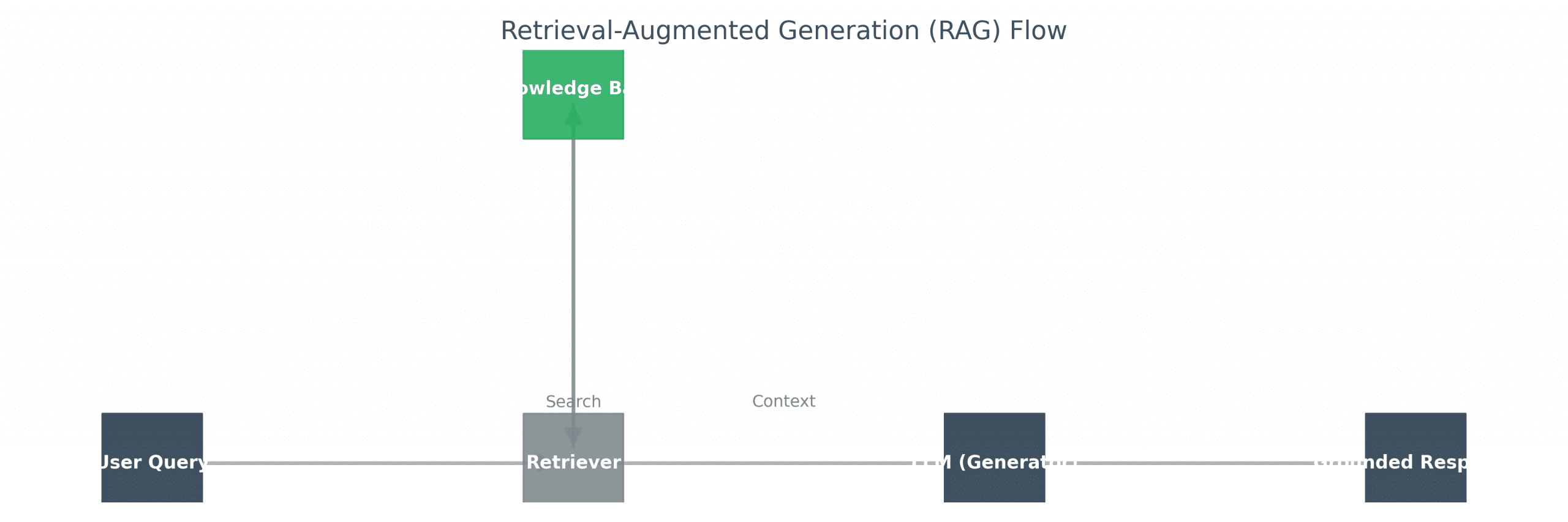
1. Retrieval-Augmented Generation (RAG)
How it works:
1. User query: “What is the latest NVIDIA stock price?”
2. RAG system searches external database (e.g., financial API)
3. Retrieved data: “NVIDIA (NVDA): $875 as of Feb 1, 2026”
4. LLM generates response grounded in retrieved data
Why it reduces hallucinations:
– Facts come from external, verified sources
– Model doesn’t rely on parametric memory
– Can cite sources (transparency)
Limitations:
– Retrieval quality matters (garbage in, garbage out)
– Slow (adds latency for database lookups)
– Can’t help with reasoning errors
2. Reinforcement Learning from Human Feedback (RLHF)
How it works:
1. Model generates multiple responses to a prompt
2. Human labelers rank them by factual accuracy
3. Reward model learns to predict human preferences
4. LLM is fine-tuned to maximize reward (using PPO algorithm)
Why it reduces hallucinations:
- Explicitly penalizes confident but incorrect answers
- Rewards expressions of uncertainty (“I’m not sure, but…”)
- Trains model to prefer factual correctness over plausibility
Anthropic’s success:
Constitutional AI: A Constitutional AI approach reportedly achieves an 85% reduction in harmful hallucinations.
Breakthrough: Models learn to refuse answering when uncertain (instead of guessing), a behavior now seen in the latest state-of-the-art LLMs.
OpenAI’s challenge:
GPT-4 still hallucinates ~15% on complex queries
Standard RLHF inadvertently rewards confident guessing
Research focus: Penalizing confident errors more than uncertainty
3. Chain-of-Thought (CoT) Reasoning
How it works:
1. Prompt: “Let’s think step-by-step…”
2. Model generates intermediate reasoning steps
3. Each step is verified before proceeding to the next
4. Final answer is based on validated reasoning chain
Why it reduces hallucinations:
Forces deliberate processing (not just pattern matching)
Errors are caught at intermediate steps (before propagating)
Facilitating human oversight: Step-by-step logic enables auditing. OpenAI’s process supervision research suggests that rewarding correct steps rather than just the final answer (outcome supervision) is the next frontier in reducing complex hallucinations.
Advanced variants:
Chain-of-Verification (CoVe): Generate answer → Create verification questions → Re-answer → Adjust final output
Self-Consistency Sampling: Generate 10 answers → Pick most common one (voting reduces random errors)
Example:
Without CoT:
Q: “What is 47 × 83?”
A: “3,901” (Hallucination)
With CoT:
Q: “What is 47 × 83? Let’s think step-by-step.”
A: “47 × 80 = 3,760. 47 × 3 = 141. 3,760 + 141 = 3,901.” (Correct)
4. Calibrated Uncertainty (Teaching Models to Say “I Don’t Know”)
This is the 2025-2026 frontier.
The problem: LLMs are trained to always provide an answer (maximizes user engagement).
The solution: Reward models that:
Give partial credit for saying “I don’t know”
Heavily penalize confident but wrong answers
Encourage conditional statements (“Based on my training data up to 2024…”)
Anthropic’s discovery (2025):
Identified internal “refusal circuits” in Claude models
These circuits activate when the model lacks knowledge
By amplifying these circuits, the model refuses ~40% more often (and hallucinates less)
Google Vertex (2025):
Flags uncertain responses in real-time
Confidence scores displayed to users
Threshold settings (reject low-confidence outputs)
5. Self-Correction (The “O1” Strategy)
The latest evolution in hallucination reduction is Real-time Self-Correction. Models like OpenAI’s O1 (and newer reasoning models) use an internal “thought” cycle before outputting.
How it works:
The model generates a hidden “scratchpad” of its reasoning.
It “looks back” at previous steps to see if they contradict known facts.
f it catches a hallucination in the scratchpad, it reroutes its prediction before the user ever sees it.
Result: Substantially lower hallucination rates in math and logic, though it can still “hallucinate its own correction” in rare cases.
The Uncomfortable Truth
Hallucinations will never be fully eliminated. Here’s why:
- Next-token prediction is inherently probabilistic (sampling introduces randomness)
- Training data contains errors (LLMs learn misinformation too)
- Knowledge is always outdated (parametric memory has cutoff dates)
- No grounding in reality (text-only training)
The best we can do:
- Reduce frequency (from 30% to <5% with RAG + RLHF + CoT)
- Flag uncertainty (let users know when the model is guessing)
- Provide sources (RAG enables citation)
The Bottom Line
LLMs hallucinate because:
Next-token prediction samples from probability distributions (not fact databases)
Quantization distorts probabilities (4-bit is 3x worse than 8-bit)
Fundamental constraints (knowledge cutoff, no real-world experience, poor temporal reasoning)
The fixes that work:
RAG grounds responses in external, verified data
RLHF teaches models to prefer factual accuracy and express uncertainty
CoT enables step-by-step verification of reasoning
What companies are doing (2025-2026):
Anthropic: 85% hallucination reduction via Constitutional AI
OpenAI: Working on penalizing confident errors
Google: Real-time uncertainty flagging (Vertex)
The hard truth: Hallucinations are a feature, not a bug, of how LLMs work. The goal isn’t elimination – it’s risk management.
And until we fundamentally rethink how AI learns (beyond text prediction), hallucinations are here to stay.
FAQ
Can hallucinations ever be completely eliminated?
No. Hallucinations are inherent to next-token prediction with probabilistic sampling. Even at temperature 0 (deterministic), if the training data contains errors or the model learned incorrect patterns, it will output wrong answers confidently. The best achievable goal is <5% hallucination rate with RAG + RLHF + CoT combined.
Why does 4-bit quantization increase hallucinations so much?
4-bit quantization reduces numerical precision, distorting the softmax probability distribution. This causes the model to assign higher probabilities to incorrect tokens. Research shows 4-bit models hallucinate ~3x more frequently than 8-bit models on factual accuracy benchmarks like TruthfulQA. The trade-off: 4-bit models are cheaper to run and faster, so economics favor accepting higher hallucination rates.
What is the knowledge cutoff problem?
LLMs store knowledge in their weights (parametric memory) during training. This knowledge is frozen at a specific date (e.g., GPT-4’s cutoff is December 2023). When asked about events after the cutoff, the model has zero information but doesn’t admit ignorance. Instead, it generates statistically plausible guesses based on patterns from training data, resulting in “temporal hallucinations.”
How does RAG actually reduce hallucinations?
RAG (Retrieval-Augmented Generation) retrieves factual information from external databases before generating a response. Instead of relying on outdated parametric memory, the LLM grounds its answer in real-time, verified data. This dramatically reduces hallucinations for factual queries. However, RAG doesn’t help with reasoning errors and adds latency due to database lookups.
Why can’t we just retrain models constantly to avoid knowledge cutoffs?
Training a frontier LLM like GPT-4 costs ~$100 million and requires months of compute time. Retraining weekly or daily is economically impossible. Instead, companies use external tools (web search, RAG, function calling) to augment parametric memory with real-time data without retraining.
What’s the difference between RLHF and Constitutional AI?
RLHF (Reinforcement Learning from Human Feedback) uses human rankings to train a reward model that guides LLM fine-tuning. Constitutional AI (Anthropic’s variant) adds an extra step: the model critiques its own outputs against a “constitution” of principles (e.g., “Be factual, not harmful”) before final selection. This self-critique loop achieved an 85% reduction in hallucinations.
Does Chain-of-Thought (CoT) actually work, or is it just longer outputs?
CoT works by forcing the model to generate intermediate reasoning steps, which are easier to verify than final answers. Research shows CoT reduces hallucinations by ~30-40% on complex reasoning tasks (math, logic). However, it doesn’t help with simple factual queries and adds token costs (longer outputs = higher API fees).



