

There’s a dangerous myth spreading: People think AI = ChatGPT. Wrong. Dead wrong.
If you believe artificial intelligence is just a chatbot that writes emails, you’re missing 99% of the picture. LLMs (Large Language Models like GPT) are ONE type of AI. A recent one. A powerful one. But saying “AI is LLM” is like saying “vehicles are Teslas.” It’s not just incomplete—it’s misleading.
So what IS AI, really? How did we get here? And why are companies scrambling to scale these systems at astronomical costs?
Let me show you exactly where LLMs fit in the broader AI ecosystem—and why the confusion matters.
The 30-Second History: From Rules to Patterns
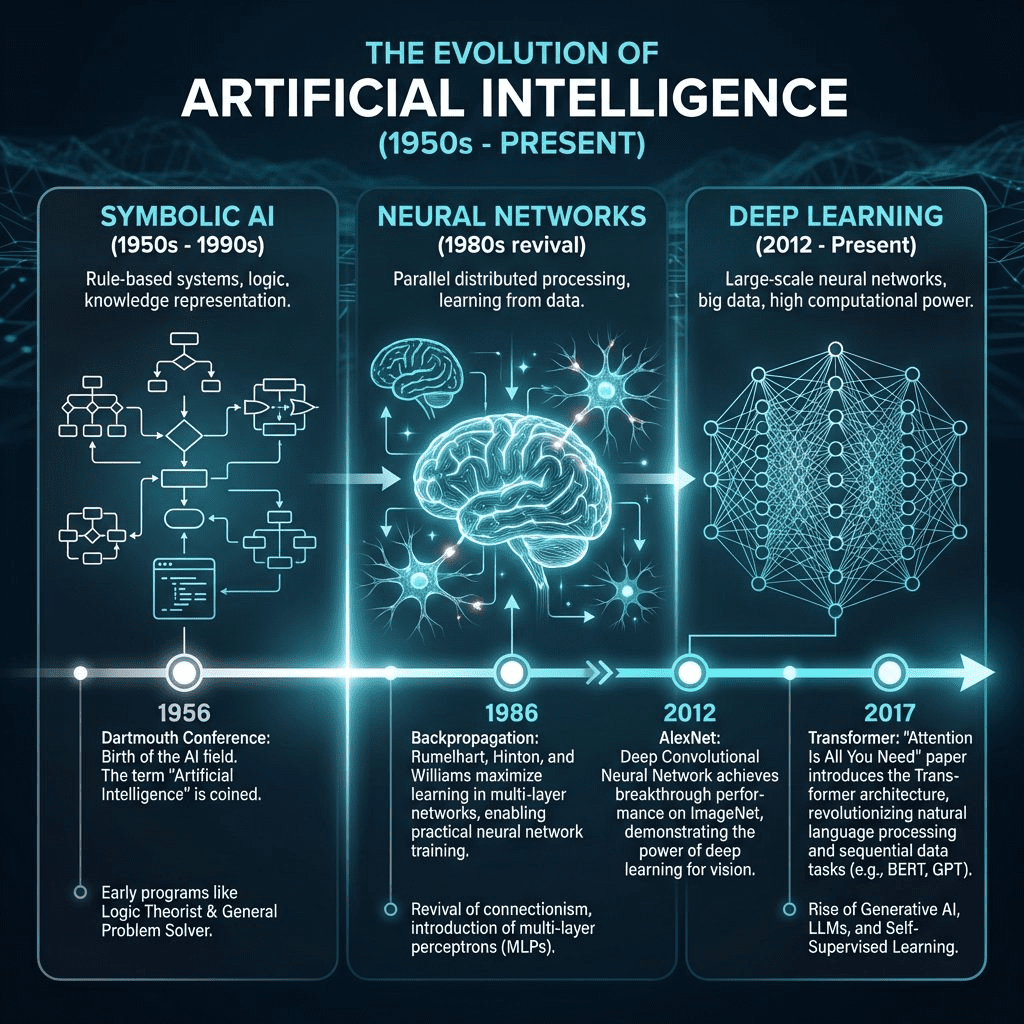
Think of AI’s evolution in three sentences:
1950s-1990s: We tried programming intelligence with explicit rules. “If patient has fever AND cough, then likely flu.” It worked for narrow tasks but failed at anything fuzzy like recognizing faces.
1980s-2012: Neural networks emerged—inspired by the brain. But they were too slow and shallow until GPUs and massive datasets unlocked deep learning in 2012 (AlexNet’s ImageNet win).
2017-Today: Google invented the Transformer architecture. It processes entire sentences in parallel using “self-attention.” This unlocked LLMs.
That’s it. That’s the journey.
Now, let’s dig into what makes LLMs tick.
What is an LLM, Really? The Prediction Machine
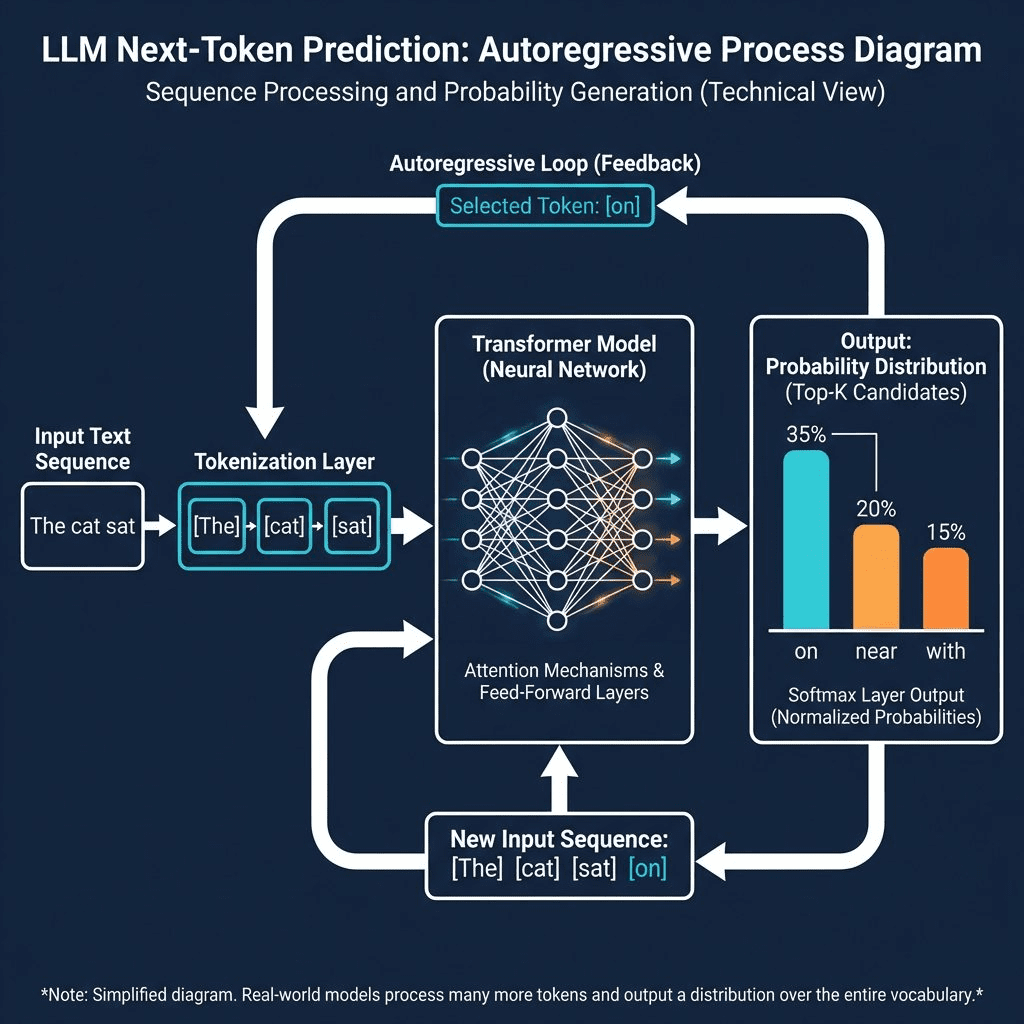
Here’s the mechanic under the hood. No fluff.
The Core Loop: Next-Token Prediction
An LLM does ONE thing obsessively well: predict the next word (token).
Imagine you type: "The cat sat on the ___"
The model:
1. Tokenizes your text into chunks: ["The", "cat", "sat", "on", "the"]
2. Calculates probabilities for EVERY word in its vocabulary:
- – “mat” → 35%
- – “floor” → 20%
- – “couch” → 15%
- – “moon” → 0.001% (technically possible!)
3. Picks the most likely token (or samples from the distribution)
4. Loops → Now predict the next token after ["The", "cat", "sat", "on", "the", "mat"]
Repeat until it hits a stop condition.
That’s the entire engine. Text in. Probability calculation. Text out. Loop.
Why “Autoregressive” Matters
LLMs are autoregressive—they can only look backward. Each token depends ONLY on what came before.
This is why ChatGPT can’t go back and fix a mistake in sentence 1 after generating sentence 10. It’s a one-way street. The model doesn’t “think ahead” or plan—it reacts to its own output, one token at a time.
Want revision capabilities? You need external systems—like multi-agent loops or chain-of-thought prompting.
What Makes It “Large”?
Parameters. Billions of them.
- GPT-3: 175 billion parameters
- Claude 3.5 Sonnet: ~200B+ (estimated)
- Llama 3.1: 405 billion
These are numerical weights learned during training. They encode grammar, facts, reasoning patterns, and even some emergent behaviors like chain-of-thought.
The Transformer’s self-attention mechanism is the key. It lets models understand that “it” in sentence 10 refers to “the company” from sentence 2—capturing long-range dependencies that older RNNs couldn’t handle.
How AI is Different from “Just LLM”
LLMs are ONE branch. Here are the others you need to know.
Computer Vision (CV): Teaching Machines to See
What it does: Processes pixels, identifies objects, understands spatial relationships.
Not next-token prediction—it’s “What objects exist in this image and where?”
CV uses deep learning (often CNNs) but the task is fundamentally different from language. It’s about spatial relationships, edges, textures, and object boundaries
Applications:
- Autonomous Vehicles: Tesla’s FSD, Waymo’s robotaxis.
- Medical Imaging: Detecting tumors in MRI scans.
- Security: Facial recognition at airports.
CV doesn’t predict the next word. It predicts: “Given these pixels, what objects exist and where?”
Architecture: Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs)
CV doesn’t care about language. It cares about edges, textures, and object boundaries.
Robotics: AI in the Physical World
What it does: Moves, manipulates, balances in 3D space.
AI is the brain. Robotics is the body. But here’s the nuance: which brain?
LLM “Brain” vs. RL “Brain”
Modern robots can use two different types of AI for decision-making:
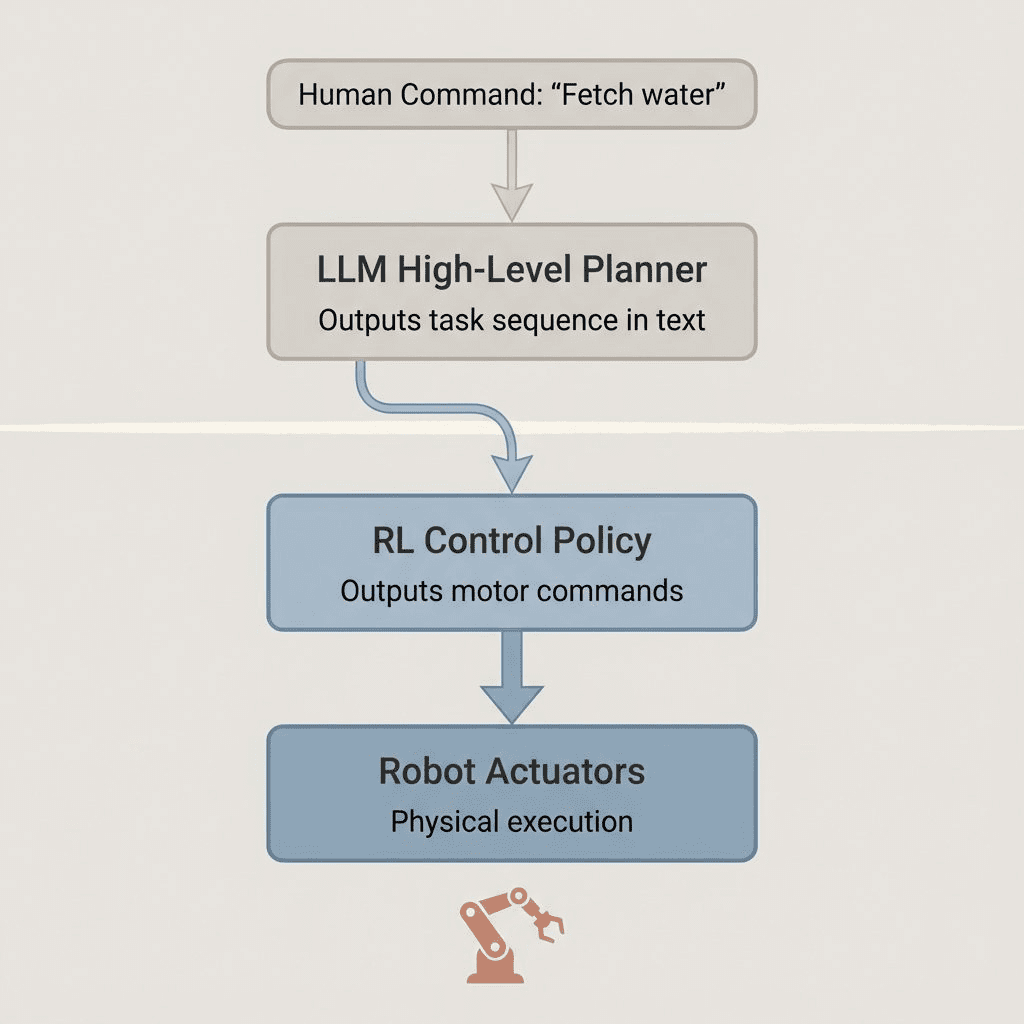
1. LLM for High-Level Planning
- Input: Natural language command (“Fetch me a glass of water”)
- Output: High-level plan (sequence of sub-tasks: “locate glass → navigate to kitchen → grasp glass → fill water → return”)
- Role: Understands human intent, breaks down complex goals, reasons about objects
LLMs excel at semantic reasoning—knowing that a “glass” is usually in a kitchen cabinet, not the bathroom. They provide the strategic layer.
2. RL/Control Policies for Low-Level Execution
- Input: Sensor data (joint angles, camera feed, force readings)
- Output: Motor commands (torque values, joint velocities, gripper pressure)
- Role: Physical execution—how to actually move the arm, balance, avoid obstacles
A control policy is a learned mapping from “current robot state” → “action to take.” This is where Reinforcement Learning shines.
Why Boston Dynamics Doesn’t Use LLMs for Backflips
Boston Dynamics’ Atlas backflipping isn’t language-based reasoning. It’s:
- RL-trained policies: Millions of simulated trials learning “if tilted 30° backward, apply X torque to hip joints”
- Classical control theory: PID controllers, trajectory optimization
- Real-time sensor fusion: IMU data, joint encoders
LLMs can’t replace this. They’re too slow (hundreds of milliseconds for inference) and don’t map directly to continuous motor control. Backflips require sub-10ms reaction loops.
The future? Hybrid systems. LLM plans the task (“clean the room”), RL executes the motions (vacuum trajectories, object manipulation).
Reinforcement Learning (RL): Learning by Reward
What it does: Learns optimal behavior through trial and error.
An agent takes actions → Gets rewards for good outcomes, penalties for bad → Learns over millions of trials.
Key difference from LLMs: LLMs learn from static text (supervised, predicting next tokens). RL learns from interaction and delayed feedback in dynamic environments.
How AlphaGo Combined Neural Networks + RL
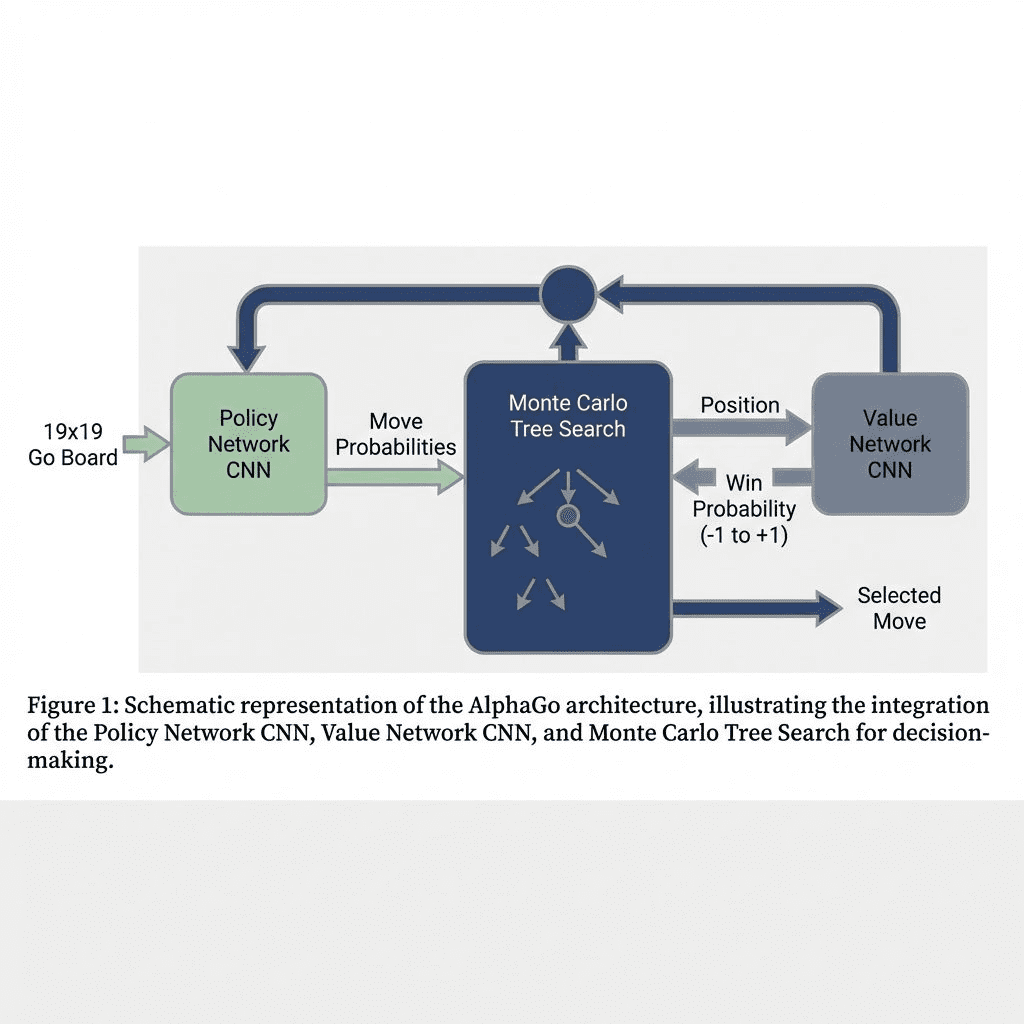
AlphaGo does use neural networks—but NOT the same way as LLMs. Here’s the architecture:
1. Policy Network (CNN)
- Input: Current Go board state (19×19 grid)
- Output: Probability distribution over all legal moves
- Training: First, supervised learning on 30 million human expert games. Then, refined via self-play RL.
- Purpose: Suggests which moves are promising (narrows search space)
2. Value Network (CNN)
- Input: Current board position
- Output: Single number (-1 to +1): “How likely am I to win from here?”
- Training: Pure self-play RL—AlphaGo played millions of games against itself
- Purpose: Evaluates positions without simulating to endgame
3. Monte Carlo Tree Search (MCTS)
- Classical search algorithm that builds a decision tree
- Uses policy network to prioritize which moves to explore
- Uses value network to evaluate leaf nodes
- Balances exploration (trying new moves) vs. exploitation (doubling down on good moves)
The Magic: Policy network says “try these moves first.” Value network says “this position is winning.” MCTS combines both to look 50+ moves ahead.
AlphaZero’s Evolution: From Dual Networks to Single ResNet
AlphaZero (2017) simplified this:
- Single deep Residual Network (20-40 ResNet blocks, 256 channels)
- Two heads: Policy head (move probabilities) + Value head (win prediction)
- Zero human data: Learned purely from self-play, starting from random moves
- Generalized: Same architecture mastered Go, Chess, and Shogi
This is fundamentally different from LLMs:
- LLMs: Next-token prediction on fixed text corpus
- RL: Sequential decision-making with delayed rewards, learned through interaction
Applications beyond games:
- Robotics control (quadruped walking, manipulation)
- Recommendation systems (YouTube, TikTok)
- Autonomous navigation (drones, warehouse robots)
Natural Language Processing (NLP): The Umbrella
NLP is the field. LLMs are a tool within it.
Other NLP tasks:
- Sentiment analysis: Is this review positive or negative?
- Named entity recognition: Extract “Google” and “California” from text
- Speech recognition: Audio → Text (Whisper, AssemblyAI)
- Machine translation: English → Spanish
You can solve NLP WITHOUT LLMs—using older techniques like TF-IDF or smaller BERT models. LLMs are just the current state-of-the-art.
Computational AI: Optimization & Generative Design
Here’s a category most people forget: AI that optimizes designs through simulation.
No pattern recognition. No text prediction. Pure computational problem-solving.
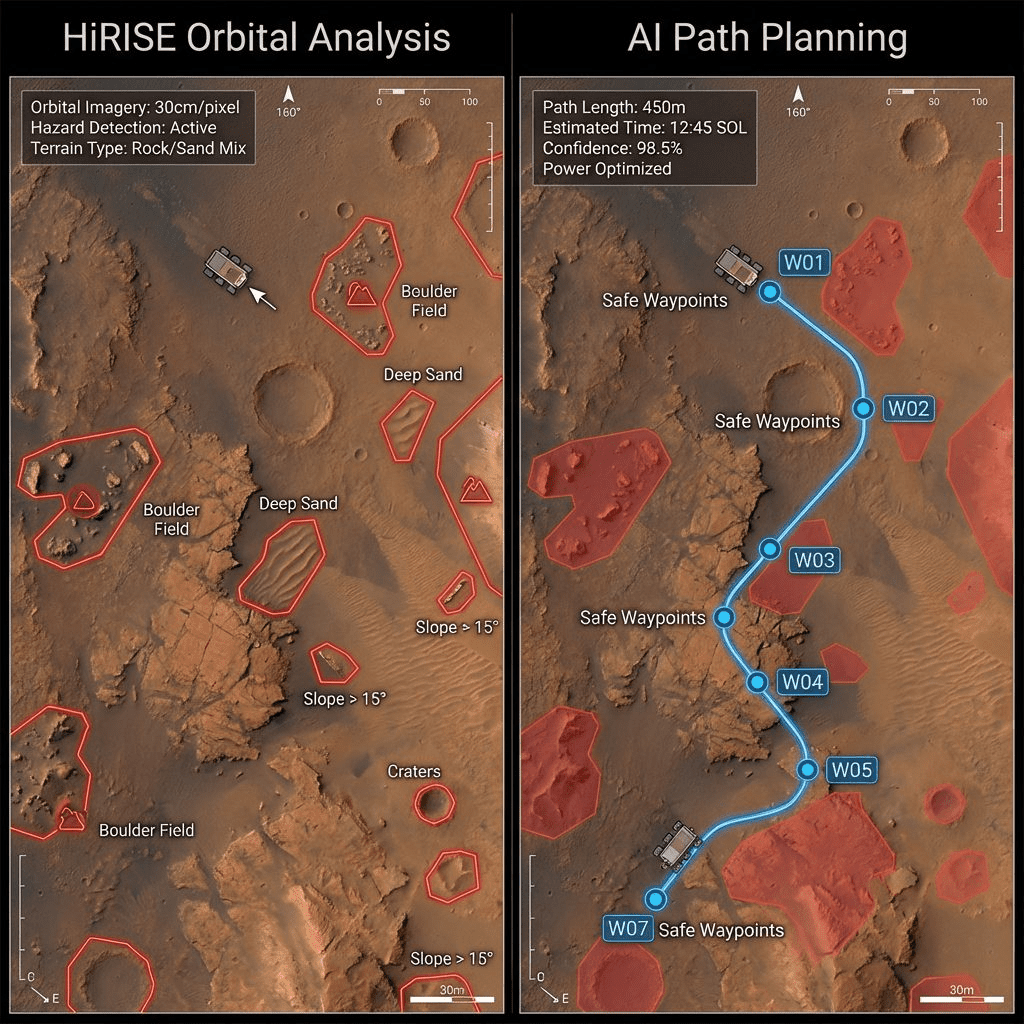
NASA’s Mars Rover: AI-Planned Routes
In December 2025, NASA’s Perseverance rover executed autonomously planned routes using generative AI.
The system:
1. Analyzes orbital imagery from Mars Reconnaissance Orbiter (HiRISE camera)
2. Identifies hazards: boulder fields, sand ripples, rocky outcrops
3. Generates continuous paths with waypoints
4. Validates in a “digital twin” (virtual rover simulation)
5. Sends commands to Mars
Impact: Halved route planning time (from hours to minutes). The rover now drives itself over 90% of the time using Enhanced Autonomous Navigation (ENav), scanning 50 feet ahead and navigating around obstacles automatically.
This isn’t an LLM. It’s vision-capable AI trained on terrain-slope data and hazard classification.
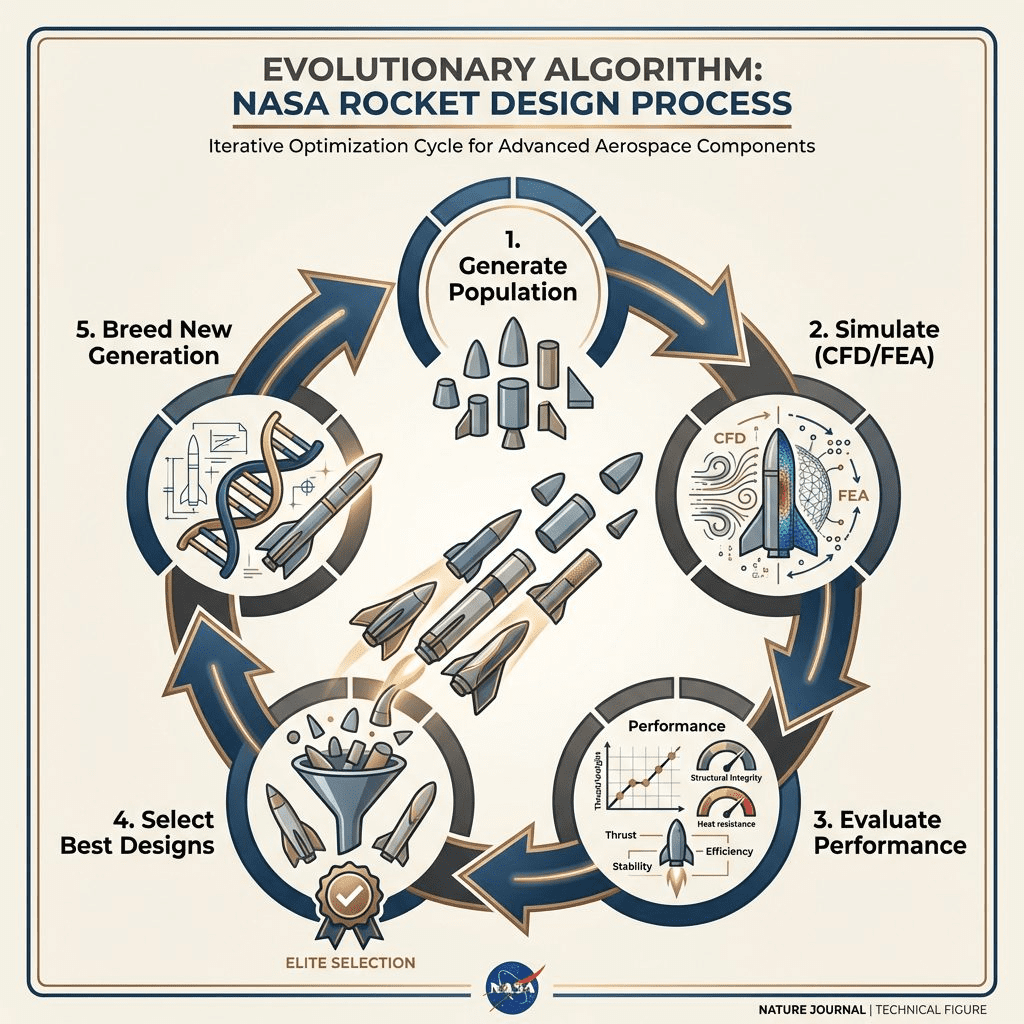
NASA’s Rocket Engines: Evolved Structures
NASA uses evolutionary algorithms to design rocket engine components.
Example: The “Evolved Optical Bench” for Mars missions.
- Challenge: Integrate ~10 separate parts into one lighter, thermally efficient component
- Method: Evolutionary algorithm + generative design (Autodesk Fusion 360)
- Result: 1/3 weight reduction, stronger structure, faster design cycle (months → hours)
How evolutionary algorithms work:
1. Generate random design population
2. Simulate performance (CFD for fluid dynamics, FEA for structural stress)
3. Score designs based on objectives (minimize mass, maximize strength)
4. “Breed” top performers → create new generation
5. Repeat for thousands of iterations
This is multi-objective optimization. The AI isn’t learning from data—it’s exploring a design space guided by physics simulations.
Another example: Leap 71’s AI-designed aerospike rocket thruster.
- Designed, manufactured (3D printed in copper), and tested in weeks
- A process that traditionally took NASA decades
- Uses “Noyron” AI engineer for computational geometry optimization
Key distinction: These AIs don’t “predict”—they generate and optimize. They’re solving constrained optimization problems, not pattern matching.
The AI Taxonomy: Where Everything Fits
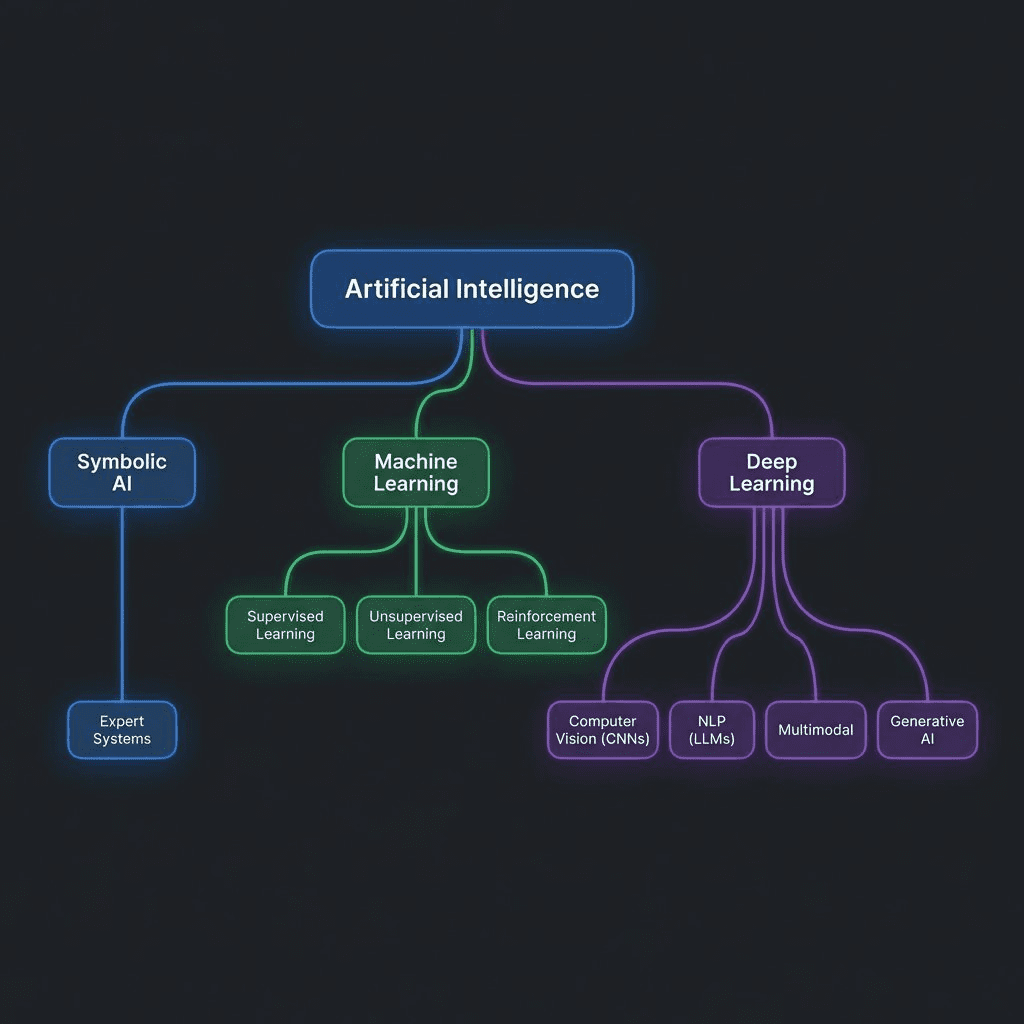
Here’s the mental model:
- AI (the goal: intelligent machines)
- Symbolic AI (1950s-1990s): Rules and logic
- Expert Systems (Dendral, XCON)
- Machine Learning (1980s-present): Learning from data
- Supervised Learning (classification, regression)
- Unsupervised Learning (clustering)
- Reinforcement Learning (AlphaGo, robotics)
- Deep Learning (2012-present): Multi-layer neural nets
- Computer Vision (CNNs, ViTs)
- NLP → LLMs (GPT, Claude, Gemini)
- Multimodal (GPT-4o, Gemini 1.5)
- Generative AI (Text, Images, Video)
LLMs sit in ONE leaf of this tree.
Scaling Laws: Why Companies Are Betting $100B
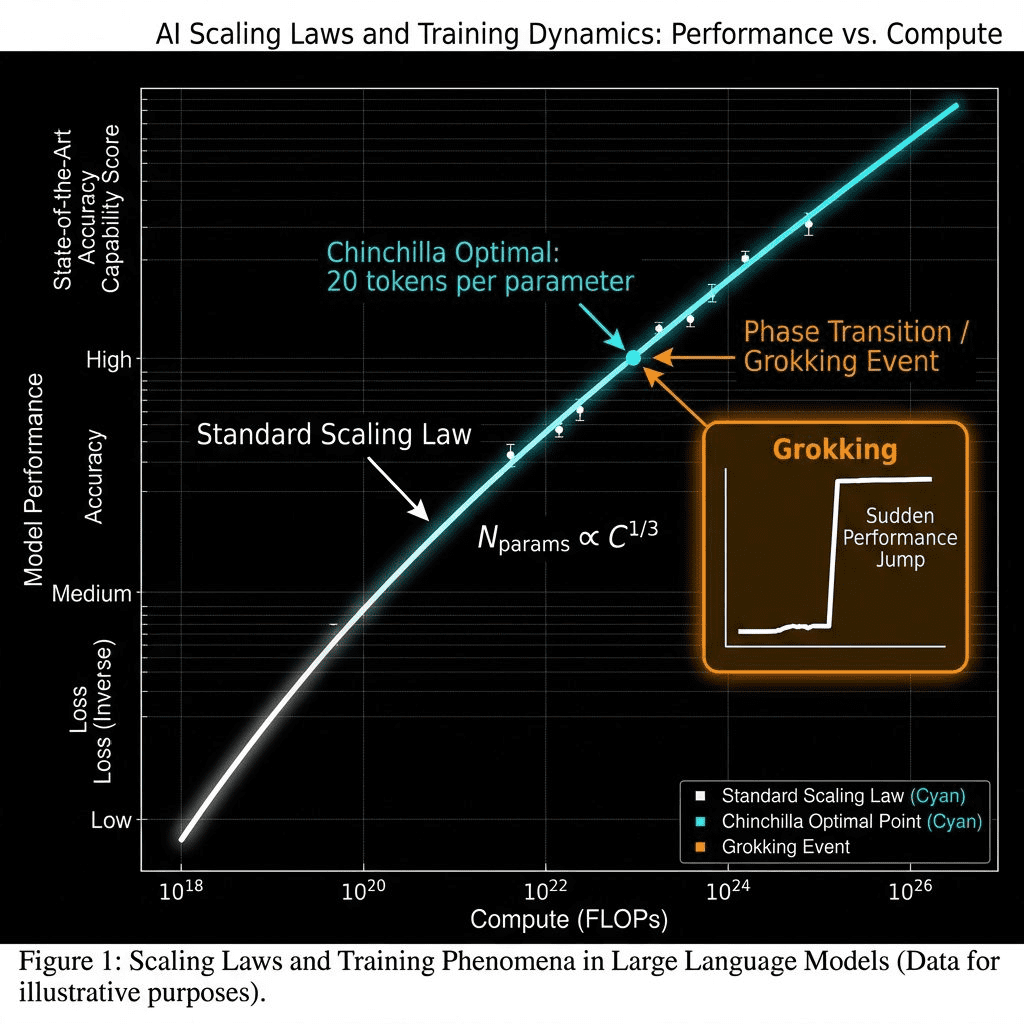
You’ve seen the headlines: “$100B for GPT-5.” “10 trillion tokens.” “1 million H100 GPUs.”
Why the insane investment?
The Chinchilla Discovery (2022)
DeepMind found the magic ratio: 20 tokens per parameter.
Before this? Models were undertrained. GPT-3 had ~1.7 tokens per parameter. That’s like teaching a student with 1.7 textbooks instead of 20.
The new rule: If you have a 70B parameter model, train it on 1.4 trillion tokens for compute-optimal performance.
This changed everything. Scaling isn’t just “bigger models”—it’s pairing model size with proportional data.
The Grokking Phenomenon: AI’s WTF Moment
Here’s something weird.
Sometimes, a model trains for weeks with zero improvement on validation data. Flat line. You’re about to give up.
Then, suddenly, overnight—it “groks.” Near-perfect generalization.
This is delayed generalization, or “grokking.” It suggests models transition through complexity phase shifts, favoring simpler (but harder-to-find) general solutions over memorization.
Why this matters: Scaling isn’t linear. You can’t predict when breakthroughs happen. You just scale compute and data, hoping for the grok.
The Scaling Bet
Companies are betting:
1. More compute + more data = better performance (so far, true)
2. Emergent abilities appear at scale (few-shot learning, chain-of-thought)
3. Whoever scales fastest wins
But there’s a wall coming.
The Constraints No One Talks About
Scaling has physics limits.
Energy: The Power Plant Problem
Training GPT-4 consumed ~50 GWh of electricity. That’s a small power plant running for months.
OpenAI’s Sam Altman is investing in fusion and nuclear because current grids can’t sustain the AI industry’s appetite.
Heat: Liquid Cooling Everywhere
NVIDIA’s H100 dissipates 700W per chip. Multiply by 10,000 chips in a cluster.
You need liquid cooling, specialized data centers, and industrial-scale airflow systems.
Memory Bandwidth: The Real Bottleneck
It’s not compute speed—it’s moving data.
Loading a 70B parameter model from memory to GPU is I/O-bound. This is why Groq built “LPUs” (Language Processing Units) with deterministic execution to minimize latency.
Data Scarcity: The 2027 Wall
We’re running out of high-quality text.
By ~2027-2028, we’ll have scraped all human-written text on the internet. After that? Synthetic data, RL fine-tuning, and multimodal training become critical.
The Bottom Line
AI ≠ LLM. LLM ≠ AI.
AI includes:
- Boston Dynamics robots doing parkour (CV + RL + control)
- DeepMind’s AlphaFold predicting protein structures (deep learning on 3D data)
- Tesla Autopilot navigating highways (CV + sensor fusion)
- NASA’s evolved rocket engines (computational optimization via evolutionary algorithms)
- Mars rover autonomous navigation (generative AI for route planning)
- AlphaGo/AlphaZero mastering games (RL + neural networks + tree search)
LLMs are:
- ChatGPT writing emails (next-token prediction)
- Claude analyzing legal docs (transformer-based text processing)
- Copilot completing code (autoregressive generation)
The confusion is understandable—LLMs are the most consumer-visible AI right now.
But conflating them with “all of AI” is like thinking the internet is just Google.
If you’re building in 2026, you need to know which branch of AI solves your problem:
- Need to process images? → Computer Vision
- Need decision-making through interaction? → Reinforcement Learning
- Need language understanding? → NLP (maybe LLMs, maybe smaller models)
- Need physical interaction? → Robotics (LLM for planning + RL/control for execution)
- Need design optimization? → Computational AI (evolutionary algorithms, generative design)
LLMs are powerful. Evolving. Incredibly hyped.
But they’re still just one tool in the AI toolkit.
FAQ
What’s the difference between AI and machine learning?
Machine learning is a subset of AI. AI is the goal—machines that perform tasks requiring intelligence. ML is one method, using algorithms that learn from data. Not all AI uses ML (symbolic AI didn’t), and not all ML is “intelligent” (spam filters use ML but aren’t considered AI by most definitions).
Are LLMs actually intelligent?
Depends on your definition. LLMs exhibit emergent reasoning (chain-of-thought, few-shot learning) but lack physical grounding, can’t revise past outputs without external loops, and hallucinate facts. They’re probabilistic text engines that mimic intelligence through pattern matching at scale. Intelligent? Partially. AGI? Not even close.
Why are companies scaling LLMs if we’re hitting limits?
Because scaling STILL works—for now. Chinchilla laws show compute-optimal training. Grokking suggests phase transitions unlock abilities. But yes, we’re approaching data limits by 2027-2028. That’s when synthetic data, multimodal fusion, and RLHF become the frontier.
Can computer vision models use transformers too?
Yes! Vision Transformers (ViTs) apply self-attention to image patches instead of word tokens. They’re now competitive with CNNs. Transformers are becoming universal—text, images, video, even protein sequences.
What’s the future of AI beyond LLMs?
Multimodal models (text + vision + audio), embodied AI (robots), world models (simulators like Sora that predict future states), and agentic systems (autonomous decision-makers). LLMs are step 1. The endgame is AI that can perceive, reason, plan, and act—not just predict the next token.



