

It seems the era of “dumb” RAG is over. You know the drill: dump PDFs into a vector DB, slap on a cosine similarity search, and pray your LLM hallucinates less. That was RAG 1.0. It was cute. It worked… sometimes. But for real-world, complex, multi-hop reasoning? It’s a toy.
Enter Ultra RAG 2.0 (specifically, UltraRAG v3 by OpenBMB and Tsinghua University).
This isn’t just an “update.” It’s a fundamental architectural shift. We’re moving from static, linear retrieval to a modular, adaptive, agency-centric engine that actually thinks about where to look. It’s what powers the “Deep Research” capabilities everyone is chasing.
Let’s rip it open.
Standard RAG vs. Ultra RAG: The “Dumb” vs. “Smart” Gap
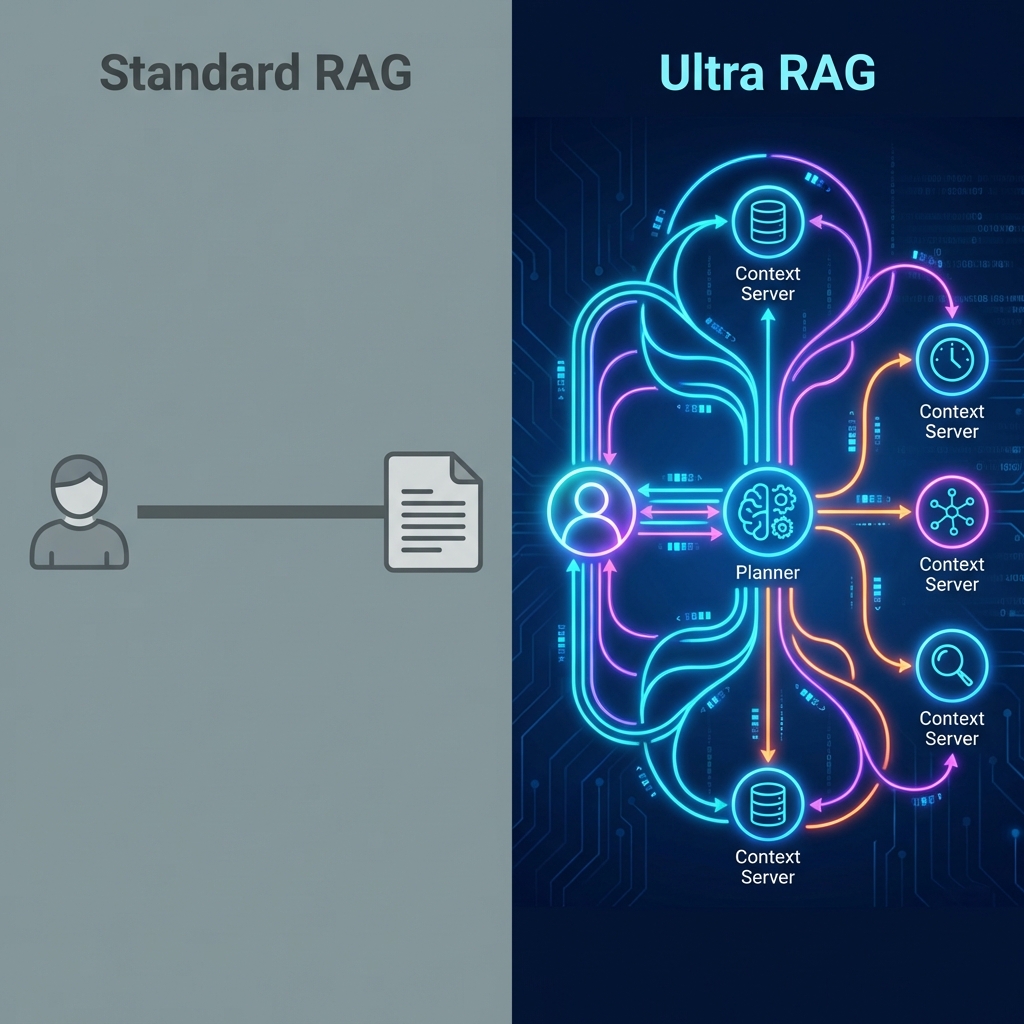
Most RAG systems today are Static Retrieval. They retrieve once based on the initial query. If the query is vague? Garbage in, garbage out. If the answer requires synthesizing three different documents? Good luck.
Ultra RAG introduces Adaptive Knowledge Management and a refined Model Context Protocol (MCP) architecture.
| Feature | Standard RAG (The “Old Way”) | Ultra RAG 2.0 (The “Deep” Way) |
|---|---|---|
| Logic | Linear (Retrieve -> Generate) | Modular & Looping (Plan -> Retrieve -> Critique -> Loop) |
| Context | Static chunks | Adaptive, hot-swappable “Context Servers” |
| Complexity | Fails at multi-hop reasoning | Built for complex, deep research tasks |
| Dev Ex | Spaghetti code | Low-code YAML Pipelines |
| Learning | Static knowledge base | Adaptive Knowledge: Fine-tunes retrieval on your data |
The Technology: Modular Agents & MCP
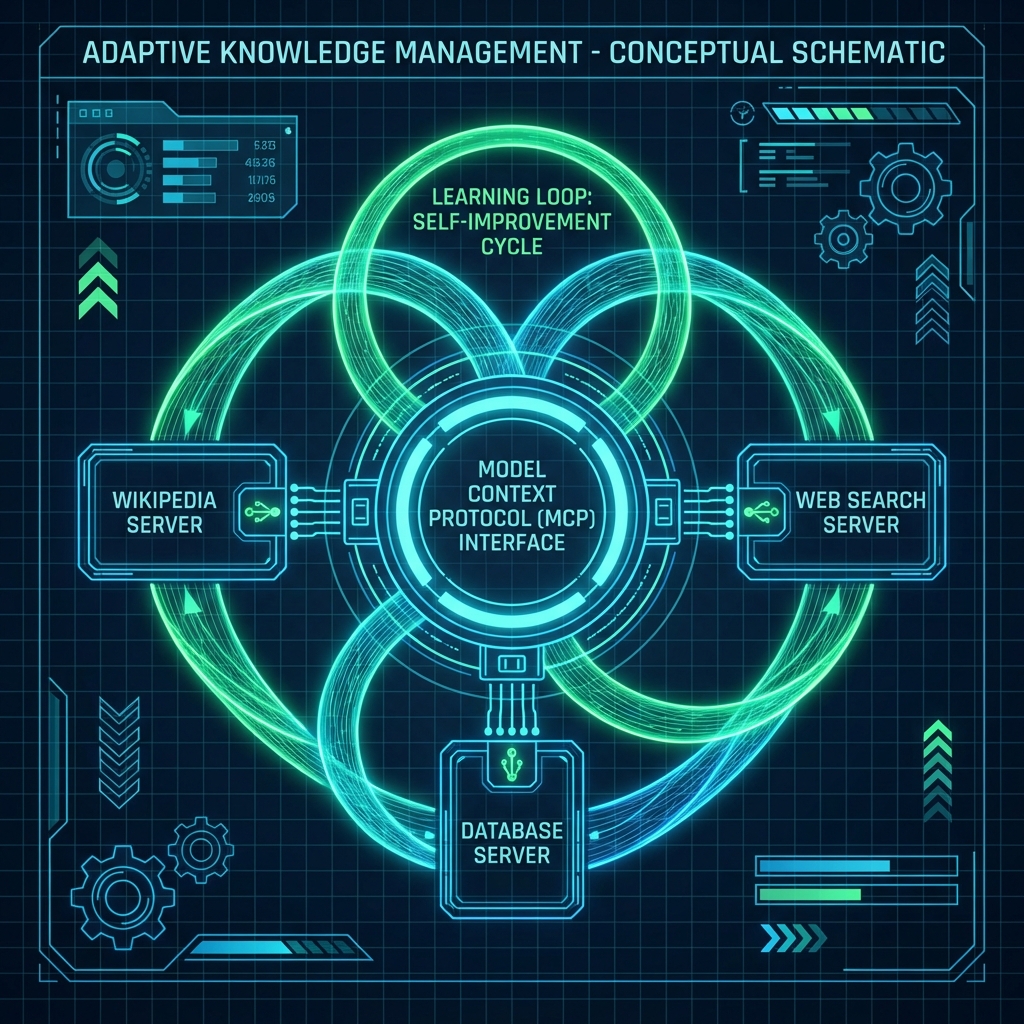
The secret sauce of UltraRAG is that it treats every part of the RAG pipeline as a Tool or a Server, adhering to the Model Context Protocol (MCP).
Model Context Protocol (MCP) in Depth
Instead of hardcoding “search Wikipedia,” UltraRAG defines a “Wikipedia Server” or “Database Server” that exposes tools (like search_page, get_schema, sql_query). The LLM, acting as a “Client,” can choose to call these tools dynamically. This decouples the intelligence (LLM) from the knowledge (Data).
This is similar to how Physical AI and Robotics creates a feedback loop between code and the real world. In UltraRAG, the “world” is your data ecosystem.
Adaptive Knowledge: The “Learning” Loop
Standard RAG databases are static. UltraRAG’s “Adaptive Knowledge” module allows the system to update its own retrieval logic. If it consistently fails to answer questions about a specific topic (e.g., “Rocket Engine Cooling”), it can flag that domain for finer-grained indexing or request human-in-the-loop clarification. It uses a Hierarchical Index where high-level summaries point to detailed chunks, allowing the agent to “drill down” only when necessary.
Code: Building Your Own Ultra RAG
Let’s build a conceptual UltraRAG v2 pipeline. We’ll set up a system that doesn’t just “search,” but investigates.
The Setup (YAML)
First, we define our pipeline logic. Notice how clean this is compared to 500 lines of LangChain code.
“yaml
modules:
- name: "planner"
type: "llm-planner"
model: "gpt-4o"
- name: "retriever"
type: "ultra-retriever"
source: "my_vector_db"
- name: "critic"
type: "llm-critic"
flow:
- step: "plan"
module: "planner"
instruction: "Break down the user query into sub-tasks."
- step: "research_loop"
type: "loop"
items: "plan.sub_tasks"
actions:
- module: "retriever"
query: "item.query"
- module: "critic"
instruction: "Is this info sufficient? If not, refine query."
- step: "synthesize"
module: "generator"
instruction: "Compile all findings into a final report."
The Python Execution
`python
from ultrarag import UltraRAG, Pipeline
engine = UltraRAG(config_path="config.json")
research_pipeline = Pipeline.load("deep_research_flow.yaml")
query = "How does UltraRAG's MCP architecture differ from standard LangChain tools, and what are the performance implications?"
result = engine.run(pipeline=research_pipeline, input=query)
print(f"Final Report:\n{result.output}")
for step in result.trace:
print(f"Step: {step.name} | Action: {step.action} | Result: {step.result[:50]}...")
Why This Matters
This research_loop` is the key. In standard RAG, you get one shot. In Ultra RAG, the system:
1. Realizes it didn’t find the answer to “performance implications.”
2. Refines the search query.
3. Goes back to the vector DB.
4. Updates the context.
That is the difference between a chatbot and a Research Agent. This capability is essential for generating the kind of high-fidelity data needed for AI Designed Rocket Engines and other critical engineering tasks.
The Bottom Line
Ultra RAG 2.0 isn’t just a library; it’s a blueprint for the future of AI search. By modularizing context and automating the feedback loop, it turns LLMs from passive text generators into active investigators.
If you’re still building linear RAG pipelines in 2026, you’re building a horse carriage in the age of the Tesla Cybertruck. Time to upgrade.



