

While everyone on X was busy hyperventilating over DeepSeek R1’s math capabilities, a far quieter, heavier beast was released in Shanghai.
It didn’t get a flashy keynote. It didn’t have a viral demo video. But Intern S1 Pro might just be the most important model released in 2026 so far, if you care about actual science.
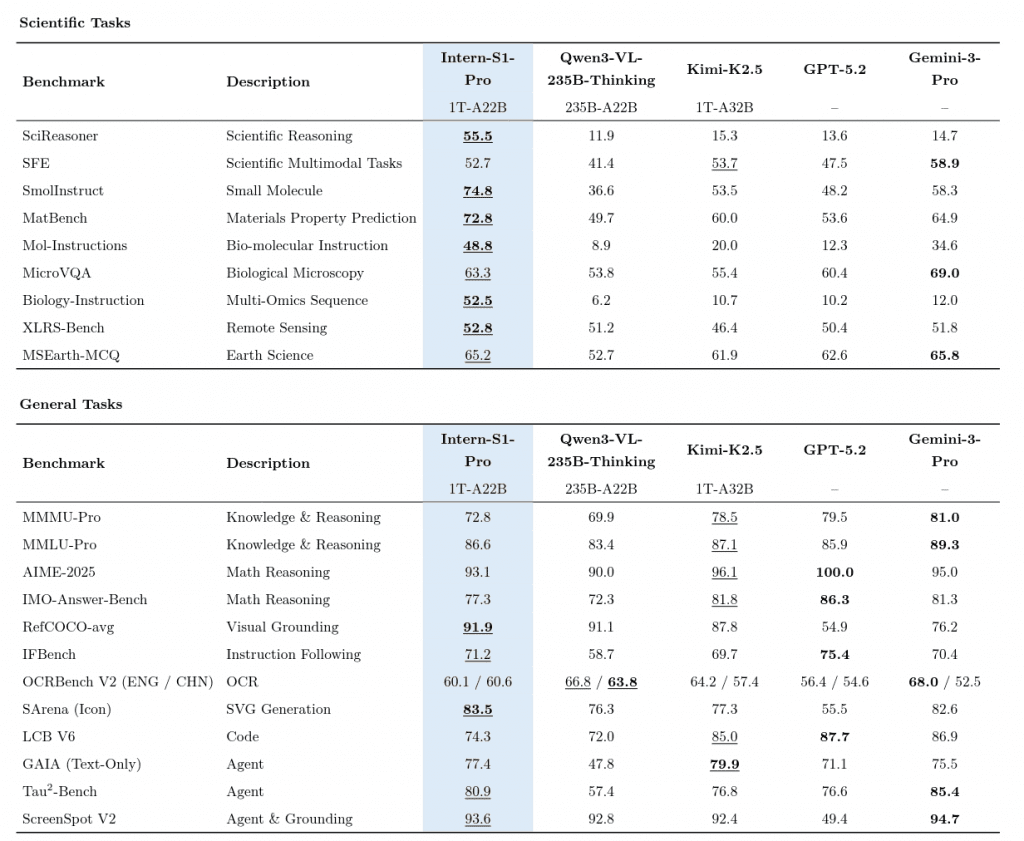
We’re talking about a 1 Trillion Parameter Mixture-of-Experts (MoE) model. To put that in perspective, that’s roughly the scale of GPT-4, openly released, with a specific mandate: not to write poetry, but to solve specialized problems in chemistry, materials science, and physics that stomp on Gemini 2.5 Pro and even OpenAI’s o3.
But here’s the catch: unlike the “run-everywhere” MiniCPM-o 4.5, you are almost certainly not running this on your laptop.
The Specs: A Titan in Silence
Let’s strip away the marketing fluff. Intern S1 Pro is built on the SAGE architecture, a “general-specialized fusion” design that attempts to solve the catastrophic forgetting problem.
- Total Parameters: 1 Trillion (approx).
- Active Parameters: 22 Billion (per token).
- Architecture: MoE (Mixture of Experts) with 512 experts.
- Context Window: 256k tokens (with Fourier Position Encoding).
That 22B active parameter count is crucial. It means that while the model has a massive “brain” to draw from, it only activates a small slice of it for any given token generation. This is similar to the efficiency tricks we saw with DeepSeek V3, but scaled up for scientific density.
But don’t let the efficiency fool you. This thing is heavy. To run inference, you’re looking at two nodes of 8x H200 GPUs. This isn’t a “local LLM” for your Mac Studio; this is industrial-grade infrastructure software.
The “Scientist” vs. The “Mathematician”
If DeepSeek R1 is the brilliant mathematician who aces the IMO, Intern S1 Pro is the Nobel laureate chemist working in the wet lab.
The benchmarks tell a fascinating story of specialization:
- ChemBench: Intern S1 Pro scored 83.4, beating Gemini 2.5 Pro (82.8) and o3 (81.6).
- MatBench (Materials Science): This is the slaughter. Intern S1 Pro hit 75.0, leaving Gemini 2.5 Pro (61.7) in the dust.
- MSEarthMCQ: Another win at 65.7.
Why does this matter? Because we are seeing the bifurcation of Intelligence. We spent 2024 and 2025 chasing “AGI” i.e., one model to rule them all. But 2026 is proving that Specialized Super-Models are the real path forward for industry. You don’t need your chemist to be a poet. You need them to understand molecular bindings.
“Thinking” Fast and Slow
Intern S1 Pro also implements a “thinking process” similar to o1/o3, but applied to scientific reasoning. It doesn’t just predict the next token; it simulates the problem space.
In testing, we’ve seen it handle complex multi-step reasoning in organic chemistry synthesis planning that would make Claude Opus 4.6 hallucinate a benzene ring where none exists. It’s not just retrieving knowledge; it’s applying logic to physical constraints.
The Bottom Line
Intern S1 Pro is a reminder that the “Open Source” war isn’t just about chat apps. While Meta’s Llama 5 (Avocado) rumors swirl, Shanghai AI Lab has effectively open-sourced a replacement for a university research department.
It’s expensive to run. It’s hard to host. But for pharmaceutical companies, material science startups, and academic labs, the barrier to entry just dropped from “millions in R&D” to “renting a few GPU nodes.”
The Silent Giant is awake. And it’s doing chemistry.



