

When GPT-4o’s voice mode dropped in May 2024, the world freaked out. Real-time voice conversations. Zero awkward pauses. Human-like emotional expressiveness that made some users feel genuinely connected to an AI. It wasn’t just good, and it set a standard that eighteen months later, most models still can’t touch.
But here’s what everyone missed: GPT-4o’s magic trick only works if you speak English (or maybe Mandarin, if you’re lucky). Try code-switching between Hindi and English mid-sentence. Watch it fumble when your uncle’s thick Punjabi accent kicks in. See it completely break down when three people are talking over each other in a noisy roadside dhaba.
India’s voice-first reality demands more than transcription. And Sarvam Audio just delivered it.
Why Voice AI Still Belongs to OpenAI (For Now)
Let’s be direct: GPT-4o’s voice capabilities remain the gold standard for a reason. The model processes audio natively—no pipeline, no text conversion bottleneck—resulting in response times around 320ms. That’s human-level conversational latency. It handles interruptions gracefully, conveys emotion, and even sings when prompted.
The reception was instant. Users praised its “scary good” naturalness. Developers integrated it into everything from customer service bots to educational tools. Some people developed emotional attachments to the AI voice, prompting concerns about parasocial relationships with machines.
And then OpenAI retired it in February 2026 to make way for newer models. Users revolted, citing GPT-4o’s unique “emotional coherence” and conversational warmth. The fact that paying customers fought to keep an older model tells you everything about how well it worked.
No other model has replicated this reception. Google’s Gemini Live offers multimodal conversations, but with ~400ms latency. Claude 4.5 supports voice dictation but outputs comparatively monotone TTS. The gap is real.
So why does Sarvam Audio matter?
The India Problem: Why Global Models Fail
India is fundamentally voice-first. Over 800 million people access the internet primarily through voice, not typing. From farmers checking crop prices to gig workers navigating deliveries to elderly users on WhatsApp, speaking is the default interface.
Traditional ASR (automatic speech recognition) systems hit a wall here. They’re trained on clean, read-speech benchmarks—think audiobooks and scripted dialogue. Real-world Indian speech is chaos by comparison:
Script control is non-negotiable. A user might say “मैं Amazon पर order कर रहा हूं” (I’m ordering on Amazon). Should “Amazon” appear in Roman or be transliterated to Devanagari? The answer depends on context—e-commerce apps need Roman for clickability, government forms need full Devanagari for compliance. One fixed output format doesn’t cut it.
Multi-speaker separation is the norm, not the exception. Family WhatsApp calls. Street-side haggling. Bank branches with six conversations happening simultaneously. Accurate recognition requires identifying who spoke what—not just transcribing the audio blob.
Context is survival. When a delivery agent says “Bhaiya, loc son bhejo” in a noisy environment, a context-free ASR outputs gibberish. A context-aware system understands the delivery domain and reconstructs the intended phrase: “Bhaiya, location bhejo” (Brother, send the location).
Sarvam Audio tackles all three.
Sarvam Audio: The LLM That Listens Different
Sarvam Audio is an audio-first extension of Sarvam 3B, a 3-billion-parameter language model pre-trained from scratch on English and 22 Indian languages: Hindi, Tamil, Telugu, Malayalam, Marathi, Bengali, Gujarati, Kannada, Punjabi, Odia, Assamese, and more.
What makes it different? It’s not just ASR. It’s a multimodal LLM that treats speech as a contextual signal, not a transcript.
Five Transcription Modes, One API Call
Sarvam Audio lets you specify transcription style at inference time:
- Literal Transcription: Word-for-word verbatim. For compliance, legal, and analysis use cases.
- Normalized Non-Code-Mixed: Formatted output with numerals and punctuation. Perfect for addresses, order IDs, and structured data extraction.
- Normalized Code-Mixed: Native script with English terms preserved in Roman. Ideal for e-commerce (“मैं Amazon पर order कर रहा हूं”), app interactions, and tech support.
- Romanized Output: Full Roman script transcription. Searchable everywhere, readable by anyone. Great for WhatsApp Business and cross-language customer support.
- Smart Translate: Speak in any Indian language, get instant English output. Built for creators targeting global audiences.
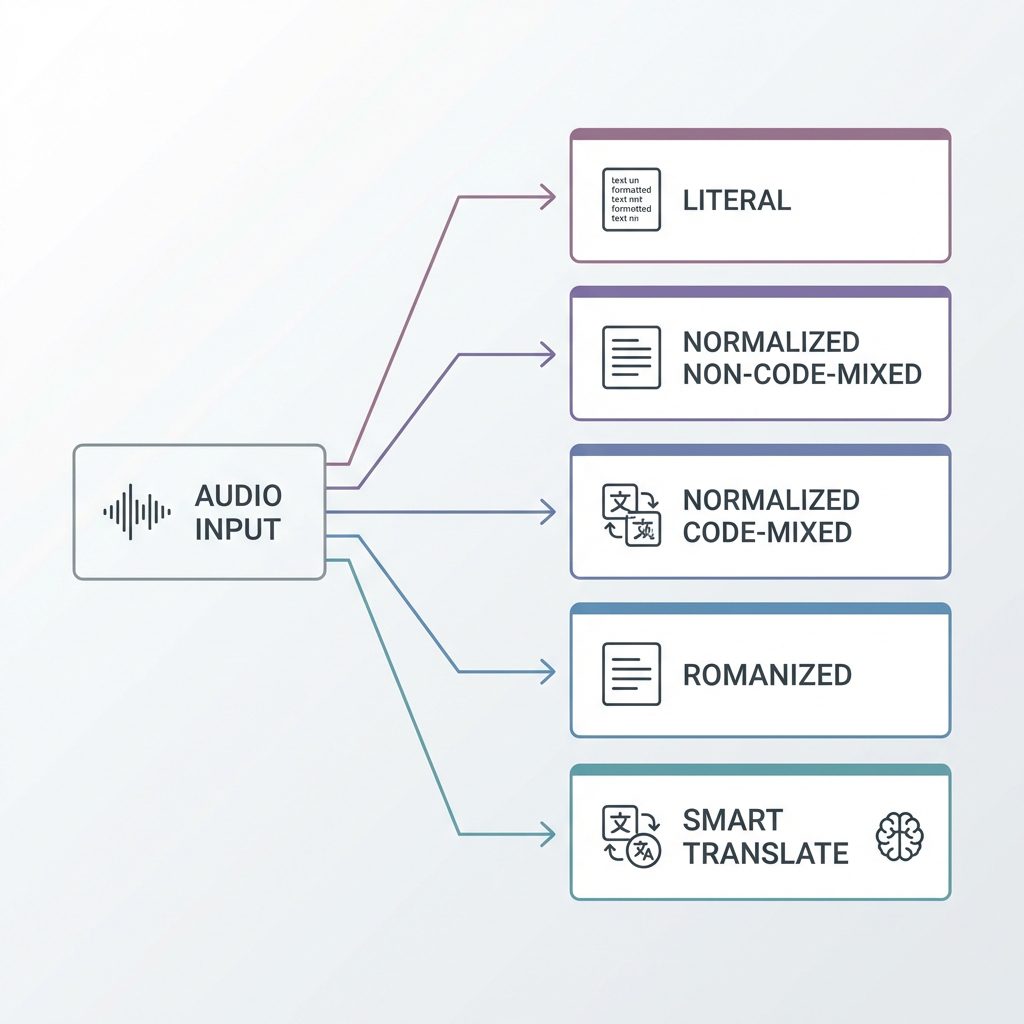
This isn’t a post-processing hack. The model understands the difference and outputs accordingly.
Benchmark Reality Check
On the IndicVoices benchmark—a large-scale dataset of real-world Indian speech covering diverse accents, noise conditions, and code-mixing—Sarvam Audio consistently outperforms GPT-4o-Transcribe and Gemini-3-Flash across all three transcription styles (unnormalized, normalized, code-mixed).
Word Error Rate (WER) is the standard metric: lower is better. Sarvam Audio achieves state-of-the-art WER across 22 languages while maintaining format control. That’s not a trade-off—it’s a feature.
Multi-Speaker Diarization: Who Said What
Real-world audio isn’t single-speaker. Meetings, interviews, family calls—overlapping speech and rapid turn-taking are standard.
Sarvam Audio performs diarized speech recognition for audio up to 60 minutes. Every word transcribed. Every speaker identified. It’s the difference between a wall of text and a structured conversation log.
This matters for:
Customer service QA: Automatically analyze agent performance across thousands of calls.
Media transcription: Generate accurate subtitles for multilingual panel discussions.
Legal compliance: Create speaker-attributed records of financial consultations.
Context Unlocks Accuracy
Sarvam Audio’s LLM backbone allows it to consume context—bot descriptions, conversation history, domain-specific knowledge—to improve transcription quality in ambiguous scenarios.
Example 1: Linguistic Ambiguity
User says: “नौ” (Nau)
Without context: Could mean “nine” (Hindi number) or “no” (English).
With conversation context (quantity prompt): Correctly interprets as “nine.”
Example 2: Noisy Audio
User says (degraded audio): “Bhaiya, loc son bhejo”
Without context: Gibberish.
With delivery domain context: Reconstructs as “Bhaiya, location bhejo.”
Example 3: Domain Awareness
User says: “M&M”
Stock market discussion context: Transcribes as “Mahindra & Mahindra” (the company).
Generic context: Outputs literal “M and M.”
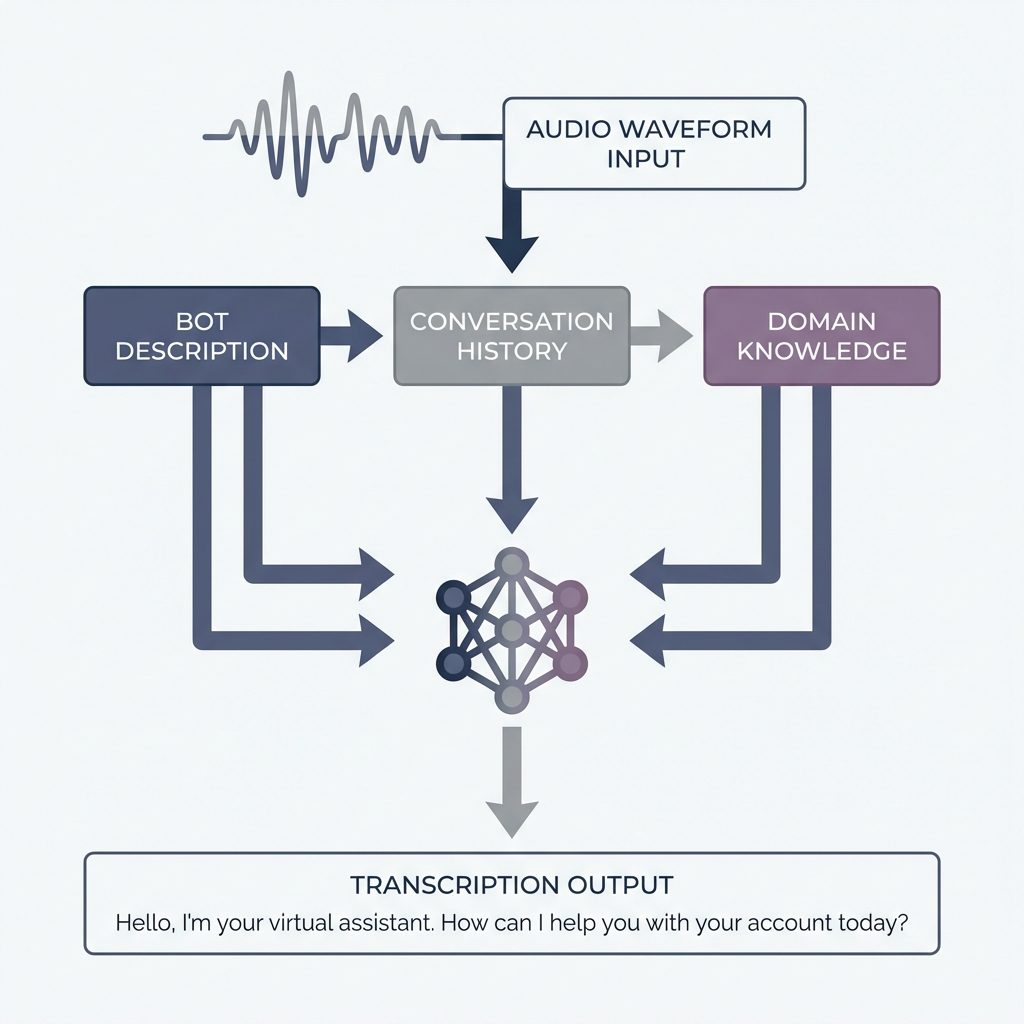
This is the gap between transcription and understanding.
What This Means for You
If you’re building voice products for India, Sarvam Audio changes the economics:
No more pipeline hell. You don’t need separate models for ASR → transliteration → normalization → speaker diarization. One model, one API call.
Code-mixing works out of the box. Over 70% of urban Indian conversations involve English code-switching. Sarvam Audio handles this natively; global models don’t.
Context = accuracy. Feed your bot description, past conversation turns, or domain context. Watch your WER drop.
Sovereign data advantage. Sarvam AI is India’s official LLM provider for the IndiaAI Mission, meaning your voice data stays within India’s regulatory framework—critical for banking, healthcare, and government applications.
Practical Code Example
Here’s how simple the Sarvam API is:
import sarvam
client = sarvam.Client(api_key="YOUR_API_KEY")
response = client.audio.transcribe(
audio_file="delivery_call.wav",
transcription_mode="normalized_code_mixed",
context="You are a delivery bot helping customers track orders.",
speaker_diarization=True
)
print(response.transcript) # Context-aware, multi-speaker output
Compare this to a GPT-4o pipeline: upload audio → call Whisper API → manually handle code-mixing → hope for the best. Sarvam Audio collapses the stack.
The Bottom Line
GPT-4o set the bar for conversational voice AI. Eighteen months later, it’s still the smoothest, most emotionally expressive voice model in the world. But it was built for a global English-speaking audience.
India’s voice-first reality demands more: code-mixing support, script control, multi-speaker attribution, and contextual awareness. Sarvam Audio delivers all four while outperforming GPT-4o and Gemini on Indian speech benchmarks.
This isn’t a “good enough for India” model. It’s a specialized tool that solves real problems global models can’t. If you’re building voice products in India, ignoring Sarvam Audio isn’t an option—it’s a competitive disadvantage.
The voice AI race isn’t over. It’s just shifting from general-purpose conversation to domain-specific mastery. And for India’s 22-language, voice-first internet, Sarvam Audio just took the lead.
FAQ
How does Sarvam Audio compare to GPT-4o for English-only transcription?
For clean English audio, GPT-4o still has the edge in emotional expressiveness and conversational latency (~320ms). But Sarvam Audio wins on accuracy for Indian-accented English, code-mixed speech, and noisy environments. If your use case involves any Indian language interaction, Sarvam Audio is the better choice.
Can Sarvam Audio handle real-time conversations like GPT-4o?
Sarvam Audio is optimized for transcription and understanding, not real-time bidirectional conversation. It excels at processing recorded audio or live streams with context, but doesn’t replicate GPT-4o’s conversational voice mode. Think “best-in-class ASR with LLM reasoning” rather than “voice chatbot.”
What’s the pricing model?
Sarvam AI offers API access with tiered pricing based on audio duration and feature usage (diarization, context length). For enterprise deployments (banking, healthcare), they provide on-premise installations to meet data sovereignty requirements. Check their official pricing page for current rates.
Does it support languages beyond India?
Currently, Sarvam Audio is optimized for 22 Indian languages plus Indian English. It’s not designed for Mandarin, Arabic, or European languages—those markets have their own specialized models. The focus is deliberate: deep, contextual understanding of India’s linguistic complexity over broad but shallow language coverage.
How accurate is the speaker diarization?
Sarvam AI claims state-of-the-art diarization accuracy for audio up to 60 minutes. In practice, accuracy depends on audio quality, speaker overlap, and acoustic conditions. It handles typical meeting/call scenarios well but may struggle with highly degraded audio or more than 8-10 simultaneous speakers.



