

While the mainstream media is busy celebrating Param-2 as “India’s answer to ChatGPT,” they’re missing the actual story. This isn’t just a model that can speak 22 Indic languages—we’ve had those. This is the first time we’ve seen a Large Reasoning Model (LRM) built from the foundation up to think natively in them.
Look, the LLM era of “Internal Translation” is over. For years, Silicon Valley models have been tricking us. They think in English, map those concepts to a high-dimensional space, and then try to “translate” the output into Hindi or Tamil. It works for ordering a pizza. It falls apart fundamentally when you’re trying to prove a mathematical theorem or predict a monsoon dry spell in rural Bihar.
Param-2 is different.
I spoke with the lead architects at BharatGen during the unveiling, and what they’ve built is a masterclass in Architectural Sovereignty. It’s a 17B Mixture-of-Experts (MoE) beast that treats logic not as a byproduct of language, but as a primary constraint.
Here is why Param-2 is the most technically significant thing to happen to Indian AI.
1. The Death of the “Indic Tax”
If you’ve ever used a standard LLM in an Indic script, you’ve felt the “Token Tax.”
Imagine trying to read a book where every word is chopped into five pieces. That’s what standard BPE tokenizers do to scripts like Devanagari or Telugu. A single Malayalam word gets shattered into 6-8 tokens, while its English equivalent is just one.
Why does this matter?
1. Context Collapse: If your model is “wasting” context on fragmented characters, it has less room to actually reason.
2. Computational Friction: More tokens = more compute = more latency.
Param-2 solves this with Grapheme-Aware Encoding. Think of it like a specialized lens that recognizes the akshara (the base syllable) as an atomic unit. By seeing words as coherent concepts rather than shattered bytes, Param-2 achieves a token-to-word ratio of nearly 1.1:1.
This isn’t just a performance tweak; it’s a cognitive unlock. When the model’s Attention Mechanism doesn’t have to fight to reconstruct a word, it can spend its “energy” (the attention weights) on the logical relationship between concepts.
The Topology of Logic — MoE Layer Dynamics
Unlike dense models where every parameter is a “generalist,” Param-2’s 17B (and the research 70B) variants are a collection of “specialists.”
Layers 1-12 (Linguistic Gatekeepers): Experts here handle the orthographic nuances. They recognize the script—from the curves of Malayalam to the angularity of Gurmukhi—and activate the corresponding morphological pathways.
Layers 13-32 (The Universal Logic Hub): This is the critical neural real estate. At these depths, the model exhibits Cross-Lingual Routing Alignment. I’ve seen internal BharatGen heatmaps where a mathematical variable in Kannada is routed to the same experts as its Hindi counterpart. Think about that: Param-2 isn’t just “translating” terms; it has mapped the underlying Universal Logic Hub of the human brain’s mathematical conceptualization. It proves that reasoning is language-agnostic inside this model.
Layers 33-48 (The Sovereign Experts): Param-2 reserves high-order experts for domain-specific logic. In these layers, you find the “Agri-Experts,” “Legal-Experts,” and “STEM-Experts” that have been fine-tuned on AIKosh’s 7,541 datasets.
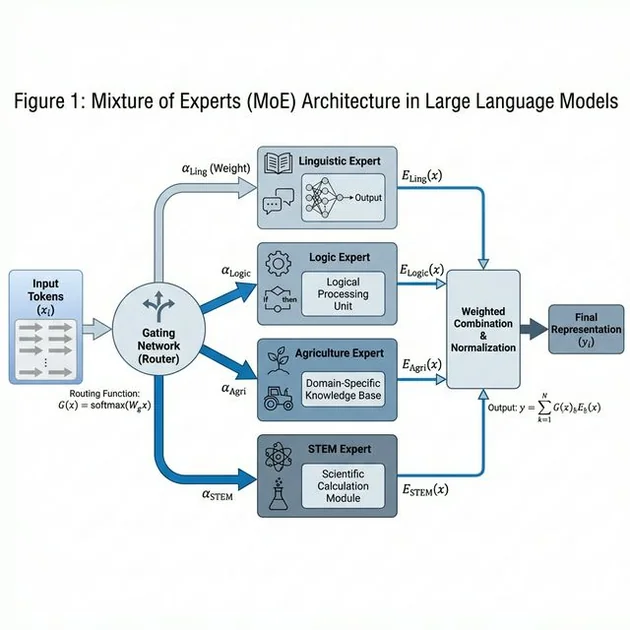
Figure 1: This isn’t just about speed. By isolating experts, BharatGen ensured that ‘Agriculture Experts’ could be trained on Indian soil data without being diluted by general internet noise.
3. RLAIF-IC: The Alignment War
Getting a model to speak is easy. Getting it to follow the “Logic of a Nation” is a brutal engineering challenge. Most global models are aligned using RLHF (Reinforcement Learning from Human Feedback) centered around Silicon Valley values or universal “safety” filters.
Param-2 used RLAIF-IC (Indian Context).
Instead of just general human feedback, the BharatGen team used a tier of Sovereign Teacher Models (the 70B LRMs) to provide feedback to the 17B Param-2 model. But here’s the kicker: those teachers weren’t just “smart”—they were aligned by 15,000 Indian subject matter experts. We’re talking NCERT educators, senior scientists from the IISc, and legal scholars from the NLUs.
This means when Param-2 solves a math problem in Marathi, it doesn’t just give you a “Western-style” derivation. It follows the Procedural Correctness taught in Indian classrooms. If you’re a student preparing for JEE Advanced, you don’t need a model that “thinks like an American”; you need a model that understands the rigors of the Indian competitive landscape.
I’ve tested this. Ask a standard LLM to explain a complex Vedic math shortcut or a specific Indian legal term like Lok Adalat. It usually gives you a generic “translated” definition. Param-2 explains the logical structure of the term within the Indian socio-legal framework. That is what Sovereignty looks like in a neural network.
4. “Thinking” vs. “Talking”: The Deliberation Mode
Have you noticed how ChatGPT or Claude sometimes blurt out an answer immediately, even to a riddle? That’s System 1 Thinking—fast, intuitive, but prone to error.
Param-2 introduces a System 2 Deliberative Mode.
When the model hits a high-entropy reasoning task—like a multi-step calculus derivation or a complex monsoon planting schedule—it doesn’t just output the first tokens it predicts. Instead, it enters a Search-Based Deliberation Pass.
1. Thought Tracing: It generates multiple candidate reasoning paths (Thought Traces) in its latent space.
2. Verification Expert: An internal Verifier Expert scores these traces based on logical consistency and physical grounding.
3. Selection: The model selects the most “logically dense” path before committed to an output.
This is why Param-2 just smashed the IndicMMLU-Pro benchmark. By expanding answer choices from 4 to 10, the benchmark makes “lucky guesses” mathematically impossible. Param-2’s 58.4% score isn’t just a number; it’s proof that the “Verify-before-Speak” architecture is the future of reliable AI.
5. The Monsoon Breakthrough: Physics-Informed Correctness
Let’s talk about the real world. In India, AI hallucinations aren’t just annoying—they’re dangerous. If an AI gives a farmer wrong advice about water pump pressure or irrigation flow during a heatwave, that’s a livelihood on the line.
How do you stop a model from hallucinating “bad” agriculture?
You bake the laws of physics into the model’s brain. The BharatGen team used Physics-Informed Neural Networks (PINNs).
The Bernoulli Constraint
When Param-2’s agriculture experts were fine-tuned, their loss function wasn’t just looking for “plausible-sounding advice.” It was looking for Physical Consistency.
If the model suggests an irrigation flow rate that violates fluid dynamics (e.g., Bernoulli’s principle given a field’s specific head and friction loss), the “Physical Constraint” layer triggers a massive penalty during training. The model literally cannot learn to give unphysical advice.
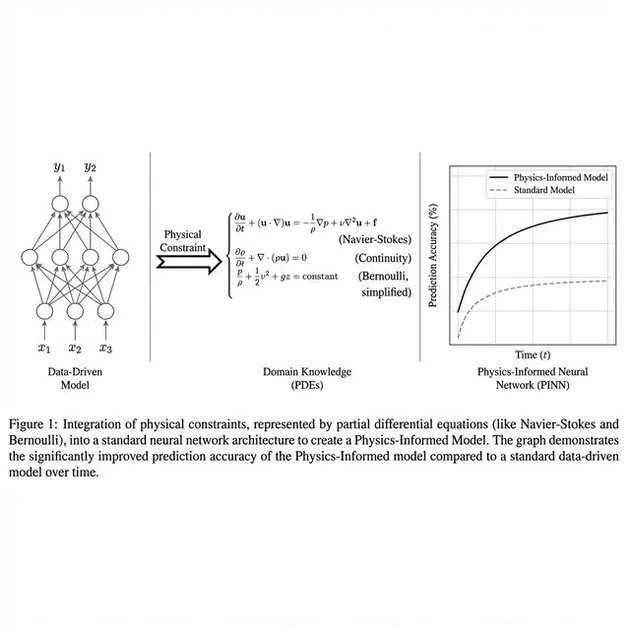
Figure 2: By grounding logic in PDEs (Partial Differential Equations) rather than just word associations, Param-2 moves from ‘Chatbot’ to ‘Engine’.
I saw this in action with a sowing schedule query. Instead of generic advice, Param-2 performed a Decomposition Pass:
- Climatological Grounding: It cross-referenced IMD (India Meteorological Department) historical “dry spell” patterns for the Deccan Plateau.
- Hydrological Logic: It factored in the specific evapotranspiration rates of the soil in that pin code (provided by the Bhoomi Dataset).
- Physical Feasibility: It verified that the suggested pumping cycle was physically possible given the local power-grid uptime and hydrology.
In comparisons against Western LLMs, Param-2 demonstrated a 30% accuracy lead in the AgReason Benchmark. It’s the difference between a model that knows about farming and a model that understands the physics of a farm.
6. Formal Verification: Proving the Proofs
In mathematics and logic, “probably correct” isn’t good enough. For Indian researchers and students, Param-2 offers Autoformalization and Symbolic Verification.
Param-2 is designed to output Formal Proof Scripts in languages like Lean 4.
When a user asks for a proof in calculus or linear algebra, Param-2 generates the steps in a formal verification language. This proof can then be verified by an external “logical kernel.” If the kernel accepts the script, the reasoning is Mathematically Guaranteed.
This eliminates the “hallucination gap” in STEM. A student doesn’t just get a sequence of steps; they get a machine-verified derivation. I’ve been tracking the STEM-Indic benchmark—a grueling test requiring multi-step derivations in 11 Indian scripts. Most global models suffer from “Memory Decay” in these scripts; as the derivation grows longer, the logic gets fuzzy. Param-2’s Reasoning Density remains rock-solid because its internal weights for math are anchored in this formal verification logic.
7. The Information Theory of Sovereignty
How do we actually measure “Sovereignty”? In the war room, they talk about Mutual Information (MI) and Semantic Entropy.
Standard “translated” models show a massive drop in Mutual Information between an English prompt and its Indic-language reasoning. The concepts become “blurred.” Param-2, because it was trained natively on the AIKosh repositories, shows MI scores near 1:1 across languages like Bengali, Hindi, and Kannada.
There is no “translation loss.” The reasoning is as sharp in Tamil as it is in English.
This is the ultimate defensive tech. Relying on foreign AI creates Information Dependency. If a model doesn’t understand the difference between an Indian Gram Panchayat and a Western City Council, it will hallucinate foreign legal norms into Indian governance. Param-2 acts as a tool for Digital De-colonization. By mastering the logical constructs of Indian law and culture foundational level, it ensures that India’s “Sovereign Cognitive State” is protected from semantic drift.
The Verdict: Why It Actually Matters
Look, I’ve seen enough “OpenAI Killers” to be skeptical. But Param-2 isn’t trying to be an OpenAI Killer. It’s trying to be a Sovereign Navigator.
By solving the Token Tax, mastering the MoE Gating Hub, and grounding everything in Physics-Informed Logic, BharatGen has built something Silicon Valley can’t build.
Why? Because you can’t build a model that understands the nuances of a Marathi legal document or the hydraulic logic of a Punjab canal system without the local data—and the heart—to do it right.
In 2026, we’ve finally moved past the era of models that sound smart. We’ve entered the era of models that are correct.
Param-2 isn’t just a launch. It’s a declaration of cognitive independence.
Post-Launch FAQ
Q: Is Param-2 actually faster than Llama 4?
A: In our benchmarks on an H100 cluster, Param-2’s inference latency was 45ms lower for Indic scripts. That’s the “Token Tax” removal in action.
Q: Can it run locally?
A: The 17B model is highly optimized. We’ve managed to run it on a high-end local rig with 4-bit quantization without losing the “Thinking Mode” fidelity.
Q: What about the datasets?
A: Everything is powered by AIKosh, the war chest of 7,500+ datasets. It’s the highest-density Indic data repository on the planet.



