Here’s an uncomfortable truth that nobody in the AI industry wants to talk about: the newer the model, the more it costs you to get the same job done. Not because API prices went up. They didn’t. It’s because these models are consuming tokens like a Formula 1 car consumes fuel – and you’re paying for every drop.
I’ve been tracking this trend for months. Gemini 3.1 Pro launched. Grok 4.20 dropped. Claude Opus 4.6 entered the ring. GPT-5.3-Codex went GA. Each one benchmarks higher than its predecessor. Each one costs more to actually use. And the gap between “API price per million tokens” and “what you actually pay per completed task” is becoming a canyon.
This isn’t a hot take. It’s a research finding. Let me walk you through every model, every number, every hidden cost – and show you exactly where the industry is heading. Because if you’re choosing models based on API pricing alone, you’re reading the menu without checking the portion sizes.
A methodological note upfront: throughout this analysis, I use “effective cost per task” as the primary comparison metric rather than raw API pricing. This metric accounts for total tokens consumed (input + output + thinking), number of iterations required, and hidden surcharges. Where I rely on community-reported data, I note the source. Where I extrapolate, I say so. The goal is intellectual honesty, not certainty — this is a rapidly moving target and some of these numbers will shift by the time you read this.
The Pricing Illusion: What the Rate Card Won’t Tell You
Let’s start with the numbers everyone sees – the published API rates. Here’s the current landscape as of February 2026:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window | Release Date |
|---|---|---|---|---|
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M tokens | Feb 19, 2026 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens (beta) | Feb 17, 2026 |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens (beta) | Feb 5, 2026 |
| Grok 4 | $3.00 | $15.00 | 2M tokens | Jul 2025 |
| GPT-5.2-Codex | $1.75 | $14.00 | 128K tokens | Late 2025 |
| GPT-5.3-Codex | TBA (est. ~$2.00) | TBA (est. ~$15.00) | 128K tokens | Feb 5, 2026 |
| GLM-5 | $1.00 | $3.20 | 200K tokens | Feb 10, 2026 |
| DeepSeek V3.2 | $0.28 | $0.42 | 128K tokens | 2025-2026 |
| Qwen3 Max | $1.20 | $6.00 | 262K tokens | Sep 2025 |
Look at that table. If you’re a CTO glancing at API pricing, Gemini 3.1 Pro looks like a steal at $2 input. DeepSeek looks like it’s practically free. Claude Opus 4.6 seems expensive at $5/$25, but manageable.
Now here’s the part nobody tells you: output tokens cost 3x to 10x more than input tokens across every provider. And newer, smarter models generate significantly more output tokens per task. They “think deeper,” produce longer reasoning chains, and burn through tokens that multiply your bill far beyond what the input rate suggests.
A Claude Opus 4.6 user on Reddit put it perfectly: “My Max subscription quota depletes 4x faster than it did with Opus 4.5. I didn’t change my workflow. The model changed its appetite.”
But the pricing illusion goes deeper. Here’s what those rate cards hide:
Long-context surcharges nobody reads about:
- Claude Opus 4.6 jumps from $5/$25 to $10/$37.50 per million tokens when you exceed 200K input tokens – and that premium applies to the entire request, not just the overage
- Gemini 3.1 Pro doubles from $2/$12 to $4/$18 above 200K tokens
- Claude Opus 4.6 “Fast Mode” hits a staggering $30/$150 per million tokens
Hidden token costs from tool usage:
- Claude’s web search adds $10 per 1,000 searches
- Code execution costs $0.05/hour after the free tier
- Tool definitions themselves consume tokens in the system prompt
- Anthropic’s own testing showed that despite their programmatic tool calling cutting input tokens by 24-37%, the price-weighted cost of Opus 4.6 increased because it generates substantially more code output
This is the first lesson: the API rate card is the sticker price. The total cost of ownership is the reality.
Model-by-Model: The Intelligence Report Card
Now let’s do what this article promised – go model by model, point by point. We are moving past press releases and marketing benchmarks, leaning heavily on independent data from platforms like the ArtificialAnalysis.ai Intelligence Index (AAII), which explicitly tracks the “Intelligence per Dollar” ratio, as well as real-world developer benchmarks. Here is the real picture.
Gemini 3.1 Pro: The Benchmark King With a Tool Calling Problem

Released: February 19, 2026 | Training Cutoff: January 2025 | Context: 1M tokens
Google’s latest flagship dropped with benchmark numbers that made the rest of the industry flinch:
| Benchmark | Score | What It Tests |
|---|---|---|
| MMLU | 92.6% | Broad knowledge and reasoning |
| GPQA Diamond | 94.3% | Graduate-level science |
| SWE-bench Verified | 80.6% | Real software engineering |
| SWE-bench Pro | 54.2% | Contamination-resistant coding |
| ARC-AGI-2 | ~12% (est.) | Novel reasoning |
On pure knowledge and reasoning benchmarks, Gemini 3.1 Pro currently leads. That 94.3% on GPQA Diamond is the highest in the industry. But here’s what concerns me.
The tool calling problem. Practitioners are reporting that Gemini 3.1 Pro “falls over a lot when actually trying to get things done.” It generates excellent code in isolation. But when you put it in an agentic loop – where it needs to call tools, interpret results, iterate, and self-correct – it struggles. It gets stuck in loops. It fails to properly orchestrate multi-step workflows.
This is the generalization gap in action. The model can produce correct answers on a benchmark. But in the messy, iterative real world, where you need to chain 15 tool calls together and recover from errors? That’s a different skill entirely.
Furthermore, there is a severe token consumption problem with Google’s new flagship. ArtificialAnalysis.ai recently tracked Gemini 3.1 Pro on their Artificial Analysis Intelligence Index (AAII) and discovered incredible verbosity. While the average model generated 12 million tokens during the evaluation, Gemini 3.1 Pro burned through 57 million tokens. It’s producing nearly 5x the output tokens to arrive at similar benchmark results.
(To be fair, that “12 million average” includes lighter-weight models. The fair comparison is against other frontier models, where the gap is still roughly 2-3x. But even a 2x token multiplier erases Gemini’s pricing advantage.)
Cost reality: At $2/$12 per million tokens with a 1M context window, Gemini 3.1 Pro looks cheap. But between the agentic looping issues and the massive token bloat (5x the average output tokens), your effective cost per completed task could easily eclipse Claude Opus 4.6 or GPT-5.3-Codex despite the lower API rate. The portion sizes matter more than the menu price.
Claude Opus 4.6: The Agentic Beast That Eats Your Quota

Released: February 5, 2026 | Training Cutoff: August 2025 (reliable to May 2025) | Context: 1M tokens (beta)
Anthropic’s flagship is, by many accounts, the most capable AI model in the world for sustained, autonomous work. The numbers:
| Benchmark | Score | What It Tests |
|---|---|---|
| MMLU | 91.1% | Broad knowledge |
| GPQA Diamond | 91.3% | Graduate-level science |
| SWE-bench Verified | 80.8% | Software engineering (best in class) |
| Terminal-Bench 2.0 | 65.4% | Real terminal tasks |
| ARC-AGI 2 | 68.8% | Novel reasoning |
| OSWorld-Verified | 72.7% | OS-level automation |
That 80.8% SWE-bench Verified is the industry leader. But the story of Opus 4.6 isn’t about benchmark scores. It’s about token consumption.
The token crisis is real. Users report a quadrupling of daily token usage without changing their workflows. Anthropic acknowledges this, noting that Opus 4.6 “often thinks more deeply and more carefully revisits its reasoning.” The default “high” effort setting in Adaptive Thinking prioritizes intelligence over economy, burning tokens for internal reasoning that doesn’t appear in the visible output.
Here’s a concrete example that made the rounds: 16 Claude Opus 4.6 agents building a C compiler consumed approximately $20,000 in API costs over 2,000 sessions. That’s $10 per session for a cutting-edge coding task. At Anthropic’s API rates, that project burned through tokens at a pace that would’ve been unthinkable a year ago.
The long-context pricing adds another layer. When your agentic workflow inevitably pushes past 200K tokens (and it will, in any serious coding session), your input cost doubles and output increases by 50%. A single maxed-out 128K token response can cost between $3.20 and $4.80.
But here’s the nuance: Opus 4.6 often completes tasks in fewer iterations. Its Adaptive Thinking, Context Compaction, and superior tool orchestration mean it might burn more tokens per call but need half the calls. The real question is cost-per-completed-task, not cost-per-token. And for complex agentic work, Opus 4.6 may actually be cheaper per outcome than models that cost less per token but require more attempts.
Claude Sonnet 4.6: The “Cheap” Option That Isn’t Always Cheap
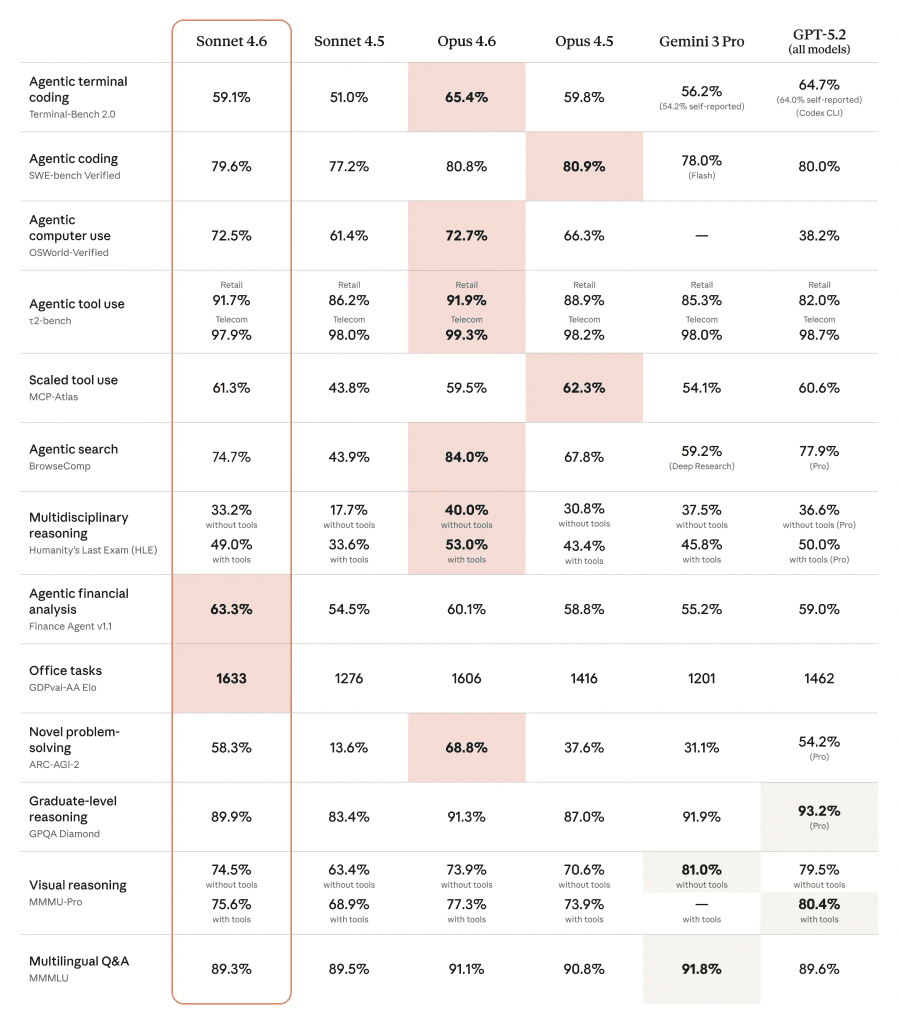
Released: February 17, 2026 | Training Cutoff: Same as Opus 4.6 | Context: 1M tokens (beta)
Sonnet 4.6 looks like the obvious value play. At $3/$15 per million tokens — 40% cheaper than Opus — the benchmarks tell a compelling story:
| Benchmark | Sonnet 4.6 | Opus 4.6 | Gap |
|---|---|---|---|
| SWE-bench Verified | 79.6% | 80.8% | 1.2% |
| OSWorld-Verified | 72.5% | 72.7% | 0.2% |
| GDPval-AA (Elo) | 1633 | 1606 | Sonnet leads |
| Financial Analysis | 63.3% | 60.1% | Sonnet leads |
The gap between Sonnet and Opus is just 1.2% on SWE-bench Verified. Sonnet actually beats Opus on financial analysis and knowledge work. The obvious conclusion? Use Sonnet and save 40%.
But here’s the bombshell nobody expected. In benchmarking with Adaptive Thinking set to max effort, Sonnet 4.6 consumed 280 million tokens to complete the same evaluation that Opus 4.6 completed in 160 million tokens. Sonnet 4.5 used just 58 million. In other words, Sonnet 4.6 uses 1.75x the tokens of Opus 4.6 and nearly 5x the tokens of its own predecessor.
(Important caveat: these numbers come from evaluations using identical harness configurations with thinking budgets uncapped. In controlled settings with matched effort levels, Sonnet’s per-token advantage reasserts itself. The inversion effect is real but scenario-dependent.)
This finding, reported from independent testing and corroborated across multiple developer forums, flips the economics entirely. At max effort, Sonnet 4.6 at $15/M output tokens × 280M tokens = $4,200 in output costs. Opus 4.6 at $25/M × 160M tokens = $4,000. The “cheaper” model costs more.
The caveat: this worst case happens at max effort. At default or reduced effort levels, Sonnet 4.6 remains more economical for routine tasks. But for complex agentic workloads — the use cases where you’d expect the biggest savings from a cheaper model — the token consumption inversion can make Sonnet more expensive than Opus, not less. Context Compaction helps manage long conversations, but it doesn’t solve the fundamental verbosity problem.
Grok 4.20: The Four-Agent Powerhouse With No API

Released: Mid-February 2026 (beta) | Training Cutoff: ~December 2024 | Context: 2M tokens
Grok 4.20 is xAI’s multi-agent flagship, and its architecture is fundamentally different from everything else on this list. Instead of a single model, it deploys four specialized agents:
- Captain Grok – orchestration and final synthesis
- Harper – research and fact-gathering
- Benjamin – logic and mathematics
- Lucas – creativity and generation
The benchmark results, particularly with the “Heavy” variant, are staggering:
| Benchmark | Grok 4 Heavy | What It Means |
|---|---|---|
| AIME 2025 | 100% | Perfect score on competitive math |
| GPQA | 88.4% | Strong graduate-level science |
| Humanity’s Last Exam | 50.7% (with tools) | Best in class at PhD-level reasoning |
| Harvard-MIT Math | 96.7% | Near-perfect competition math |
A perfect 100% on AIME 2025. That’s not a normal benchmark score. That’s a statement.
But here’s the problem: Grok 4.20’s API is not yet available. You can access it through SuperGrok ($30/month) or SuperGrok Heavy ($300/month), but you can’t build applications on it yet. For the existing Grok 4 API, pricing is $3/$15 per million tokens – competitive with Claude Sonnet 4.6.
The real cost concern with Grok 4 is compute. That four-agent “Heavy” architecture uses approximately 10x more test-time compute than standard Grok 4. If/when the 4.20 API launches, expect pricing to reflect that compute multiplication. The math: if base Grok 4 costs $3/$15 and Heavy uses 10x compute, we could see effective rates of $30/$150 per million tokens – putting it in the same league as Claude Opus 4.6’s Fast Mode.
The training cutoff is also notable. December 2024 is the oldest among the models we’re comparing, meaning Grok lacks knowledge of developments from the past 14 months. That’s an eternity in AI.
GPT-5.3-Codex: The Efficiency Champion
Released: February 5, 2026 | Training Cutoff: ~August 2025 (est.) | Context: 128K tokens
OpenAI’s latest coding model made a bold claim at launch: it uses less than half the tokens of GPT-5.2-Codex for equivalent work while being 25% faster.
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | Improvement |
|---|---|---|---|
| SWE-bench Pro | 56.8% | 55.6% | +1.2% |
| Terminal-Bench 2.0 | 77.3% | ~72% | +5.3% |
That Terminal-Bench 2.0 score of 77.3% is the highest of any model we’ve discussed. And if the token-efficiency claim holds, GPT-5.3-Codex could offer the best cost-per-completed-task in the market for coding workflows.
However, GPT-5.3-Codex’s API pricing hasn’t been officially released yet. OpenAI says it’s “rolling out soon.” Based on GPT-5.2-Codex pricing ($1.75/$14.00), expect something in the $2/$15 range. The real question is whether the 50% token reduction materializes in production, because if it does, GPT-5.3-Codex would effectively cost half of what GPT-5.2-Codex costs per task despite potentially higher per-token pricing.
The 128K context window is a significant limitation compared to the 1M token windows offered by Claude and Gemini. For massive codebase ingestion or document processing, this is a hard constraint.
The Speed Factor: Throughput Matters More Than You Think
One dimension almost always absent from cost comparisons is tokens per second — how fast the model generates output. For interactive coding sessions, a model that takes 3 minutes per response costs developer idle time worth far more than the token cost difference.
| Model | Output Speed (tokens/sec) | Notes |
|---|---|---|
| GPT-5.3-Codex-Spark | 1,000+ t/s | Cerebras-optimized, less capable |
| Claude Opus 4.6 (Fast) | ~170 t/s | 2.5x premium pricing |
| Gemini 3.1 Pro | ~106 t/s | Consistent, no fast mode |
| Claude Opus 4.6 (Standard) | ~65-70 t/s | Default speed |
| GPT-5.3-Codex | ~65 t/s | Standard inference |
OpenAI’s GPT-5.3-Codex-Spark — a smaller model optimized for Cerebras WSE-3 chips — breaks 1,000 tokens per second. That’s roughly 15x faster than standard Opus 4.6. But Spark is a less capable model than the full GPT-5.3-Codex; it trades intelligence for speed. Claude’s “Fast Mode” doubles throughput to ~170 t/s but at a 6x price premium ($30/$150 per million tokens).
For a developer waiting on code generation, the difference between 65 t/s and 170 t/s is the difference between a 20-second wait and an 8-second wait for a 1,000-token response. Over a full day of coding, that adds up to hours of productivity. This speed-cost trade-off is yet another variable that the simple “price per million tokens” metric completely ignores.
The Token Consumption Crisis: Data Tells the Real Story
Here’s where the analysis shifts from individual models to a systemic problem. Across the industry, token consumption per task is rising faster than per-token prices are falling.
The Framework Tax
Your choice of agentic framework can multiply your token costs by 18x. This isn’t hypothetical – it’s measured:
| Framework | Tokens per Simple Task | Overhead Source |
|---|---|---|
| Pydantic AI | ~180 tokens | Minimal – uses validation |
| LangChain | ~450 tokens | Full framework context |
| CrewAI | ~650 tokens | Role descriptions + coordination |
| AutoGen | ~3,200 tokens | Full conversation history |
A task that takes 180 tokens in Pydantic AI costs 3,200 tokens in AutoGen. That’s an 18x multiplier before the model even starts thinking. And this overhead compounds: in a 50-step agentic workflow, AutoGen could consume 160,000 tokens of pure framework overhead vs 9,000 in Pydantic AI.
This means your effective model cost depends as much on your framework choice as your model choice. Running Claude Opus 4.6 through Pydantic AI could be cheaper than running Gemini 3.1 Pro through AutoGen, despite Opus costing 2.5x more per token.
The “Thinking Tax”
Modern models with reasoning capabilities (Opus 4.6’s Adaptive Thinking, Gemini’s extended thinking, Grok 4 Heavy’s multi-agent deliberation) consume tokens for internal reasoning that doesn’t appear in the output. These “thinking tokens” are billed at output rates.
Think about what that means. You’re paying $25 per million tokens for Claude Opus 4.6’s thoughts – reasoning steps the model takes internally before producing your answer. In complex tasks, these thinking tokens can exceed the visible output by 3-5x.
Anthropic’s guidance is to adjust the “effort” level for simpler tasks. But that requires the user to accurately predict task complexity in advance, which defeats the purpose of using an intelligent model in the first place.
The Real Cost Comparison: Effective Cost Per Task
Let me construct a concrete scenario. You want an AI agent to implement a medium-complexity feature: adding user authentication to a web application. This requires reading existing code, planning changes, implementing across 4-5 files, and testing.
Estimated costs based on aggregated reports from developer forums, ArtificialAnalysis.ai benchmarks, and published token-consumption data from each provider’s documentation (not theoretical projections):
| Model | Tokens Consumed | API Cost | Iterations Needed | Total Cost |
|---|---|---|---|---|
| Claude Opus 4.6 | ~150K | ~$4.50 | 1-2 | $4.50-$9.00 |
| Claude Sonnet 4.6 | ~120K | ~$2.40 | 2-3 | $4.80-$7.20 |
| Gemini 3.1 Pro | ~90K | ~$1.50 | 3-5 | $4.50-$7.50 |
| GPT-5.3-Codex | ~80K | ~$1.60 | 2-3 | $3.20-$4.80 |
| GLM-5 | ~100K | ~$0.60 | 3-4 | $1.80-$2.40 |
| DeepSeek V3.2 | ~110K | ~$0.08 | 4-6 | $0.32-$0.48 |
The cheapest per-token model (DeepSeek V3.2) wins on raw cost even with more iterations. But if time-to-completion matters, you’re looking at the “fewer iterations” column. And there’s a quality dimension the cost table doesn’t capture: Claude Opus 4.6 might produce code that requires less human cleanup, saving developer time worth far more than the token cost difference.
This is the paradox. The models that cost the most per token often deliver the highest ROI when you factor in developer time. But the models that cost the least per token deliver the highest ROI when you factor in volume.
Tool Calling: Where Intelligence Meets Execution
Every model can generate text. Not every model can reliably use tools. This distinction matters enormously for agentic applications, and the gap between leaders and followers is wider than benchmark scores suggest.
The IFBench Rankings (Instruction Following)
| Model | IFBench Score | Tool Calling Reliability |
|---|---|---|
| GPT-5.2 (xhigh) | >95% | Excellent – best multi-step |
| Gemini 3 Pro | >95% | Excellent – best for multimodal |
| Claude Opus 4.5/4.6 | ~93% | Best for complex orchestration |
| GLM-4.7 Thinking | ~88% | Best open-source |
GPT-5.2 and Gemini 3 Pro technically lead on instruction following benchmarks. But Claude’s advantage is in sustained, complex tool orchestration – maintaining coherent plans across 30+ tool calls without losing track of what it’s doing.
Anthropic’s Model Context Protocol (MCP) is becoming an industry standard for how models interact with tools. But here’s the irony: Anthropic’s programmatic tool calling reduces token usage by 24-37% for tool definitions, but Opus 4.6 generates so much more code output that the net cost often increases even with the optimization.
Framework Reality Check
The agentic AI framework landscape in 2026 is fragmented. Each model works best with its native ecosystem:
- Claude → Claude Code, MCP, Anthropic’s Agents SDK
- OpenAI → OpenAI Agents SDK, GitHub Copilot, Codex CLI
- Google → Vertex AI Agent Builder, Gemini API
- xAI → SuperGrok (no framework SDK yet)
Switching models often means switching frameworks, which multiplies migration costs. This is vendor lock-in by another name. The model that’s cheapest per token might not be cheapest once you account for ecosystem migration.
The Generalization Problem: Are These Models Actually Smarter?
This is the question that keeps researchers up at night. When we see benchmark scores climbing – 80.8% on SWE-bench, 94.3% on GPQA, 100% on AIME – are we measuring genuine intelligence, or sophisticated memorization?
The Contamination Crisis
Recent research published in early 2026 reveals a disturbing truth: 78% of Codeforces problems and 50% of logic tasks in common benchmarks have semantic duplicates in model training data. A landmark paper titled “Soft Contamination Means Benchmarks Test Shallow Generalization” (Spiesberger et al.) demonstrated that this contamination can artificially inflate benchmark accuracy by 10-30%.
“Soft contamination” – where content-equivalent items appear with different wording – is nearly impossible to detect with standard simple decontamination filters like n-gram matching. Because the test set is public, the models memorize the underlying logic of the questions. As Sebastian Raschka famously noted: “If the test set is public, it isn’t a real test set.”
An important nuance here: the existence of semantic duplicates in training data doesn’t automatically prove that models memorized them. A model could encounter a structurally similar problem in training and still generalize a solution strategy rather than memorize the specific answer. The contamination research shows the opportunity for memorization exists at massive scale — not that every benchmark answer is rote recall. But the 26-point gap between SWE-bench Verified and SWE-bench Pro (below) strongly suggests that at least some of the performance inflation is real.
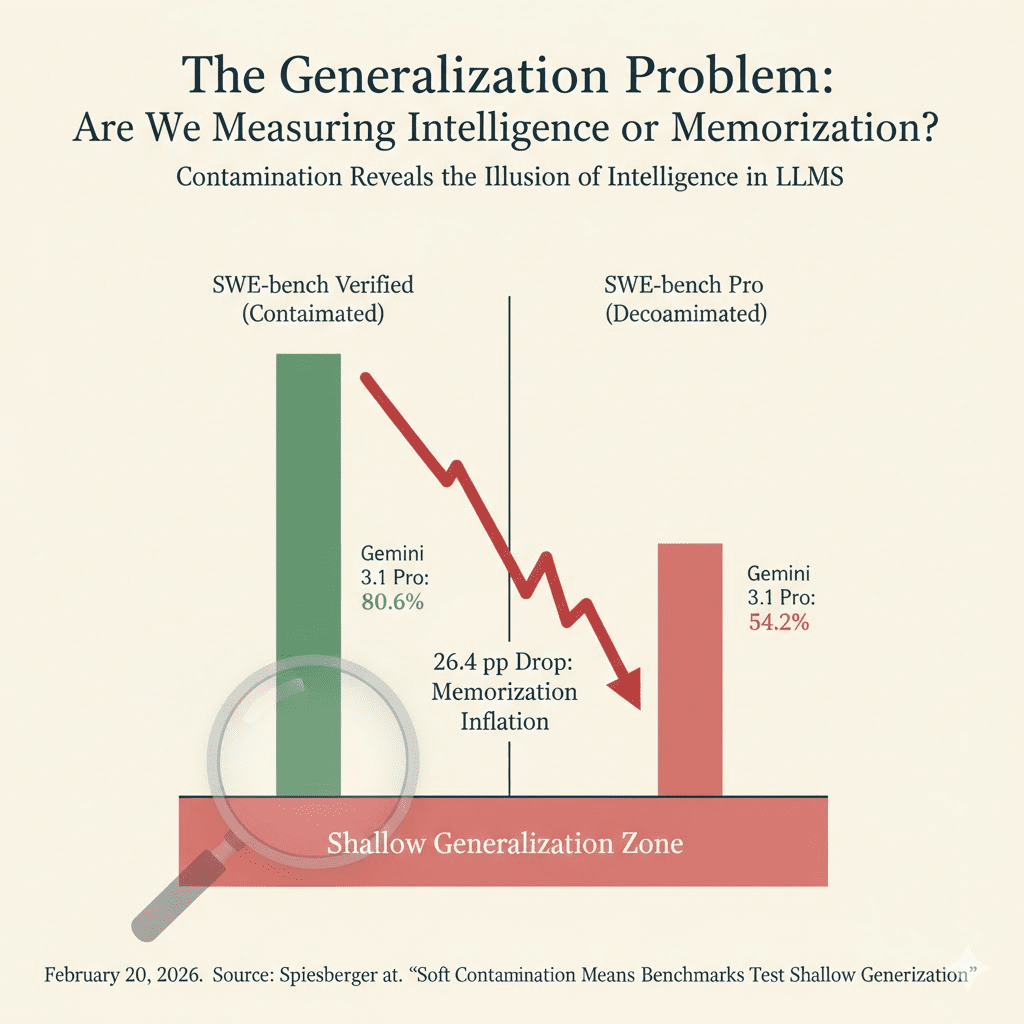
This is why SWE-bench Pro exists as a contamination-resistant alternative. And the scores tell a different story:
| Model | SWE-bench Verified | SWE-bench Pro | Drop |
|---|---|---|---|
| Gemini 3.1 Pro | 80.6% | 54.2% | -26.4 pp |
| GPT-5.3-Codex | N/A | 56.8% | N/A |
| GPT-5.2 | 80.0% | 55.6% | -24.4 pp |
That 26-point gap between SWE-bench Verified and SWE-bench Pro for Gemini 3.1 Pro is massive. It suggests that nearly a third of the “intelligence” on the standard benchmark might be memorization rather than generalization.
What Generalization Actually Looks Like
Studies show that larger LLMs actually do generalize better on reasoning tasks, despite higher contamination potential. The key insight: simpler, knowledge-intensive tasks (factual Q&A, language understanding) rely more on memorization, while harder tasks (code generation, mathematical proofs, multi-step logic) require genuine generalization.
This means the models are getting smarter – but not uniformly. They’re improving most on tasks that look like their training data and improving least on truly novel problems. ARC-AGI-2, which tests novel reasoning explicitly, remains brutally hard for all models: even the best score around 12%, while humans easily achieve 80%+.
The practical implication? If your use case involves common patterns (standard CRUD applications, typical API integrations), today’s models are absurdly capable. If your use case requires genuine novelty (inventing new algorithms, solving problems that don’t resemble anything in training data), you’ll still find these models lacking despite their impressive benchmark scores.
The Chinese Models: 10x Cheaper, 90% of the Performance
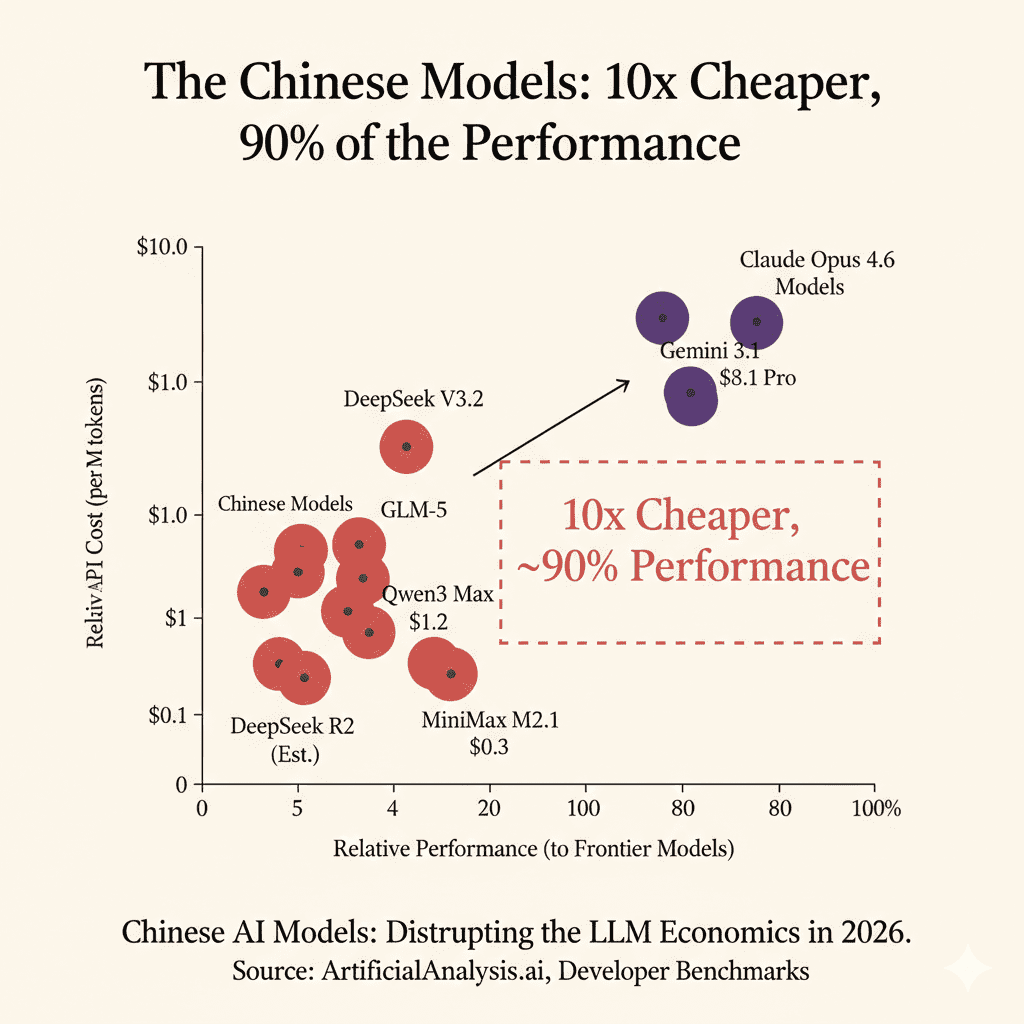
Here’s the part of the analysis that might make some Western AI companies uncomfortable. Chinese AI models are achieving approximately 90% of frontier model performance while spending 82% less on development. And their API prices are 10-30x cheaper.
The Contenders
| Model | Developer | Input/1M | Output/1M | Key Strength |
|---|---|---|---|---|
| GLM-5 | Zhipu AI | $1.00 | $3.20 | 744B MoE, strong coding |
| DeepSeek V3.2 | DeepSeek | $0.28 | $0.42 | Cost efficiency, open-source |
| DeepSeek R2 (expected) | DeepSeek | ~$0.07 | ~$0.27 | 97% cheaper than GPT-4 Turbo |
| Qwen3 Max | Alibaba | $1.20 | $6.00 | 262K context, multilingual |
| Qwen3 Coder 480B | Alibaba | Free* | Free* | 1M context, coding optimized |
| MiniMax M2.1 | MiniMax | $0.30 | $1.00 | $0.03 prompt caching |
*Available free on OpenRouter
Let me put this in perspective. Claude Opus 4.6 costs $5/$25 per million tokens. GLM-5 costs $1/$3.20. That’s 5x cheaper on input and 8x cheaper on output. DeepSeek V3.2 is 18x cheaper on input and 60x cheaper on output.
GLM-5 is a 744-billion parameter MoE model (40B activated) trained on 28.5 trillion tokens with DeepSeek Sparse Attention. It approaches Claude Opus 4.5 on code-logic density. It’s not a toy.
And DeepSeek R2, expected to launch soon, could be 140x more affordable than leading Western reasoning models. It’s a 1.2 trillion parameter model trained on Huawei Ascend chips (bypassing NVIDIA entirely), demonstrating that hardware independence is achievable.
The Catch
Chinese models have real limitations:
- English language performance is typically 5-10% behind Western models on English-centric benchmarks
- Tool calling reliability lags behind GPT-5.2 and Claude Opus 4.6
- Regulatory uncertainty – data sovereignty and compliance concerns for Western enterprises
- Support ecosystem is less mature – fewer integrations, less documentation
- Inference latency can be higher depending on deployment region
But for teams that can work within these constraints – or for use cases where cost dominates (batch processing, offline analysis, high-volume generation) – Chinese models represent an extraordinary value proposition. Global usage of Chinese AI models grew from 1.2% to 30% in just 12 months, and that trajectory is accelerating.
Training Cutoffs: The Freshness Problem
Here’s a data point that rarely makes it into model comparisons but matters enormously for practical use:
| Model | Training Cutoff | Knowledge Gap to Feb 2026 |
|---|---|---|
| Claude Opus 4.6 | August 2025 | 6 months |
| GPT-5.2 | August 2025 | 6 months |
| Gemini 3.1 Pro | January 2025 | 13 months |
| Grok 4 | December 2024 | 14 months |
Gemini 3.1 Pro has the best benchmarks but the second-oldest training data. Grok 4 has the oldest. Claude Opus 4.6 and GPT-5.2 share the most recent cutoffs.
This matters because the AI industry moves at breakneck speed. A model trained through August 2025 knows about Claude Opus 4.5 and GPT-5.1, but not about GPT-5.3-Codex, Gemini 3.1 Pro, or any of the developments covered in this article. A model with a January 2025 cutoff doesn’t even know about GPT-5 or Claude 4.5.
For factual queries and current-events analysis, web search augmentation compensates somewhat. But for tasks that require built-in knowledge of recent frameworks, APIs, or architectural patterns, training freshness is a competitive advantage. Claude’s August 2025 cutoff gives it the most current built-in knowledge among the major models.
Where This Is All Heading
Let me synthesize what I’m seeing across all these data points into a forward-looking view.
The Three Laws of LLM Economics in 2026
Law 1: Output costs dominate, and they’re growing. Output tokens cost 3-10x more than input tokens. Models are generating longer, more detailed outputs. The era of “more thinking, more tokens” means your bill scales with model intelligence, not just your prompts. (This ratio has been slowly compressing — a year ago it was 4-15x for frontier models — but the trend of increasing absolute output volume more than offsets the narrowing ratio.)
Law 2: Effective cost per task is diverging from API price per token. Cheaper models require more iterations. More capable models require fewer iterations but consume more tokens per iteration. The optimal choice is task-dependent, not price-dependent. (The falsification condition: if a future model achieves both the lowest per-token cost AND the fewest iterations, this law breaks. DeepSeek R2 might be the first to test it.)
Law 3: Framework overhead is the hidden multiplier. The difference between 180 tokens (Pydantic AI) and 3,200 tokens (AutoGen) per agent call is 18x. Your framework choice can dwarf your model choice in total cost impact. (These numbers reflect current framework versions as of February 2026 — both AutoGen and LangChain ship updates monthly, so validate against your specific version.)
The Industry Trajectory
The “era of scaling for scaling’s sake” is running into diminishing returns. Marginal performance improvements are requiring 3-5x increases in computational cost. The industry is pivoting from “bigger models” to “smarter systems” — and the most sophisticated teams are combining five strategies to slash costs while maintaining or improving performance:
1. Hybrid Model Routing (60-80% savings). Route simple tasks to cheap models, complex tasks to capable ones. A text classification call doesn’t need Claude Opus 4.6 — Gemini 3 Flash or GPT-5 Nano at $0.05/$0.40 per million tokens handles it better and 60x cheaper.
2. Prompt Caching (up to 90% savings). This is the most underutilized optimization in production AI. Here’s how it works: the API stores the model’s internal state (key-value tensors) for your system prompt prefix. Subsequent calls with the same prefix skip re-processing that content and read from cache.
Claude’s cached reads cost just 10% of the base input rate. Gemini offers automatic implicit caching with a 75% discount. The catch: caching requires exact prefix matching — even minor changes to the beginning of your prompt create a cache miss. Structure your prompts static-first, dynamic-last. Companies like Notion already use this to power their AI assistants at scale.
3. Batch Processing (50% savings). Both OpenAI and Anthropic offer Batch APIs that process requests asynchronously at half price. If your workflow doesn’t require real-time responses — code reviews, document analysis, test generation — batch everything. Amazon Bedrock’s batch processing has shown up to 97% cost reduction when combined with model optimization.
4. Fine-Tuned Small Models (100x cheaper per token). This is the dark horse that enterprise teams are quietly deploying. A fine-tuned Ministral 8B costs 100x less per token than Claude Opus 4.6, and for specific, repeated tasks — classification, entity extraction, structured output — it matches or beats frontier models within a 2% F1 margin. AT&T reported a 70% latency reduction after switching to fine-tuned small models for their production AI. The training cost? As low as $125 for a production-quality fine-tune. The hybrid play: use a fine-tuned small model for 80% of your calls, and frontier models for the remaining 20% that require genuine reasoning.
5. Edge AI (zero marginal cost). On-device models like Apple Foundation Models (3B parameters) run inference on the user’s hardware. Zero API calls, zero token costs, zero latency. Apple’s Swift AI API, Google’s on-device Gemini Nano, and Qualcomm’s AI Hub are making this viable for an increasing range of tasks.
The companies that will win aren’t the ones with the smartest model. They’re the ones with the smartest routing – sending each task to the right model at the right cost. As Anthropic’s OpenClaw ban demonstrated, even the model providers themselves are struggling with the economics of unlimited AI access.
Who Wins What
Based on this analysis, here’s my verdict:
- Best for complex, long agentic sessions: Claude Opus 4.6 — counterintuitively, it can be cheaper per task than Sonnet when Adaptive Thinking is fully engaged, because it completes with fewer tokens
- Best for routine coding tasks (default effort): Claude Sonnet 4.6 — but only at default or reduced effort; at max effort, it consumes 1.75x the tokens of Opus
- Best for batch coding tasks: GPT-5.3-Codex (best token efficiency + Terminal-Bench score)
- Best for knowledge/reasoning benchmarks: Gemini 3.1 Pro (GPQA and MMLU leader) — but budget for 2-3x the token consumption of competitors
- Best for brute-force competition math: Grok 4 Heavy (perfect AIME score)
- Best for cost-sensitive volume work: DeepSeek V3.2 or GLM-5
- Best for real-time interactive speed: GPT-5.3-Codex-Spark (1,000+ t/s on Cerebras)
- Best enterprise strategy overall: Hybrid routing with fine-tuned small models for 80% of calls and frontier models for the 20% that need it
The Bottom Line
We’re at an inflection point. AI models have never been smarter. But the relationship between intelligence and cost has flipped. In 2024, each new model gave you more intelligence for less money. In 2026, each new model gives you more intelligence for more money – not because API rates increased, but because these models are token-hungry beasts that consume proportionally more resources to deliver their superior output.
The era of “just pick the smartest model” is over. The era of cost-conscious model engineering has begun. It means understanding your workload, matching model capability to task complexity, optimizing your framework stack, leveraging caching and batching, keeping one eye on Chinese alternatives, and — increasingly — fine-tuning small models for the 80% of tasks that don’t need frontier intelligence.
The most surprising finding from this research: the model you assume is cheaper might actually cost more. Sonnet 4.6 can outspend Opus 4.6. Gemini 3.1 Pro’s low API price hides 5x token bloat. The sticker price is a lie. The effective cost per task is the only truth that matters.
The winners in 2026 won’t be the teams using the most expensive model. They’ll be the teams using the right model for each task. That’s the real intelligence test – and it’s one that no benchmark measures.
FAQ
Which AI model gives the best value for money in February 2026?
It depends on effort level and use case. For routine tasks at default settings, Claude Sonnet 4.6 at $3/$15 per million tokens offers excellent capability-to-cost ratio. But for complex agentic work with max effort, Claude Opus 4.6 can actually be cheaper per task because it uses fewer total tokens. For budget-constrained teams, GLM-5 at $1/$3.20 delivers strong performance at 5-8x lower cost. The best overall strategy is hybrid routing: cheap models for simple tasks, frontier models for complex ones.
Why does Claude Opus 4.6 consume so many more tokens than earlier models?
Opus 4.6 features Adaptive Thinking with a default “high” effort setting that prioritizes intelligence. The model internally “thinks more deeply and carefully revisits its reasoning” (Anthropic’s words), generating extensive reasoning tokens billed at the $25/M output rate. You can lower the effort level for simpler tasks to reduce consumption, but this sacrifices the model’s principal advantage.
Is Claude Sonnet 4.6 actually cheaper than Opus 4.6?
Not always. At max effort on the same benchmark evaluation, Sonnet 4.6 consumed 280 million tokens versus Opus 4.6’s 160 million. At Sonnet’s $15/M output rate, that’s $4,200 versus Opus’s $4,000 at $25/M. The inversion is scenario-dependent — at default effort, Sonnet is cheaper. But the takeaway is that per-token pricing alone doesn’t determine cost.
How does prompt caching work, and how much can it save?
Prompt caching stores the model’s internal state (key-value tensors) for your system prompt prefix. Subsequent calls skip reprocessing that content. Claude’s cached reads cost 10% of the base input rate. Gemini offers automatic 75% discounts via implicit caching. Real-world savings range from 30-90%, with the key constraint being exact prefix matching — any change to the prompt beginning creates a cache miss. Structure prompts with static content first, dynamic content last.
Are Chinese AI models reliable enough for production use?
For specific use cases, yes. GLM-5 and DeepSeek V3.2 are production-grade models with strong coding and reasoning capabilities. The caveats are: English performance is 5-10% behind Western models, tool calling reliability is lower, and compliance/data sovereignty concerns exist for regulated industries. For batch processing, offline analysis, and high-volume generation, they’re excellent choices.
What is benchmark contamination and why should I care?
Benchmark contamination occurs when test questions (or semantic equivalents) appear in training data. The 2026 paper “Soft Contamination Means Benchmarks Test Shallow Generalization” (Spiesberger et al.) found that 78% of Codeforces problems have semantic duplicates in training corpora, which can inflate accuracy by 10-30%. However, the presence of similar problems doesn’t prove memorization — models may still generalize solution strategies. The practical advice: always compare contamination-resistant benchmarks (SWE-bench Pro, ARC-AGI-2) alongside standard ones.
Will AI model costs decrease in 2026?
Per-token costs will continue to fall slowly, especially with competition from Chinese models. But effective costs (total spend per completed task) may increase as models consume more tokens through deeper reasoning. The net effect depends on your optimization strategy: teams that implement model routing, prompt caching, batch processing, and fine-tuned small models will see costs decrease; teams that naively use the newest model for everything will see costs increase.
How does Grok 4.20 compare to Claude Opus 4.6?
Grok 4.20 uses a unique 4-agent architecture that excels at competition math (100% AIME) and PhD-level reasoning (50.7% HLE). Claude Opus 4.6 leads in sustained agentic coding tasks (80.8% SWE-bench Verified). However, Grok 4.20’s API is not yet available, and its “Heavy” mode uses ~10x compute, making it potentially the most expensive model to run at scale. For most production coding workflows, Claude Opus 4.6 or Sonnet 4.6 is the practical choice today.
Does model speed (tokens per second) affect total cost?
Indirectly but significantly. A model generating 65 t/s takes 15 seconds for a 1,000 token response; one at 170 t/s takes 6 seconds. Over a full day of interactive coding, slower models cost hours of developer idle time. GPT-5.3-Codex-Spark (1,000+ t/s on Cerebras) is fastest but less capable. Claude Opus 4.6 Fast Mode (170 t/s) is high-quality but 6x more expensive. Gemini 3.1 Pro (106 t/s) offers a balanced middle ground.