

Picture this: You’re debugging a gnarly production issue at 2 AM. Your AI coding assistant is generating solutions, but there’s a 3-second lag between each suggestion. You fix one bug, hit another, wait for the AI, rinse, repeat. That lag? It’s killing your flow state.
Now imagine the same scenario, but your AI is spitting out solutions at 350 tokens per second. No lag. No waiting. Just pure, uninterrupted problem-solving velocity. That’s what Step 3.5 Flash from StepFun just made possible.
Released on February 2, 2026, this Shanghai-based AI company you’ve probably never heard of just dropped a model that’s making Gemini 3 Flash look sluggish. We’re talking 350 tokens per second in coding tasks while maintaining performance that rivals OpenAI and Google’s best.
This is a 196-billion-parameter Mixture-of-Experts model that activates only 11 billion parameters per token, supports a 256K context window, and was specifically engineered for autonomous agents. And it’s fully open-source under Apache 2.0.
If you’ve been following the AI chip war between the US and China, Step 3.5 Flash is another data point showing that Chinese AI labs aren’t just catching up – they’re innovating in directions Western labs haven’t prioritized.
The Secret: 196B Parameters, Only 11B Active
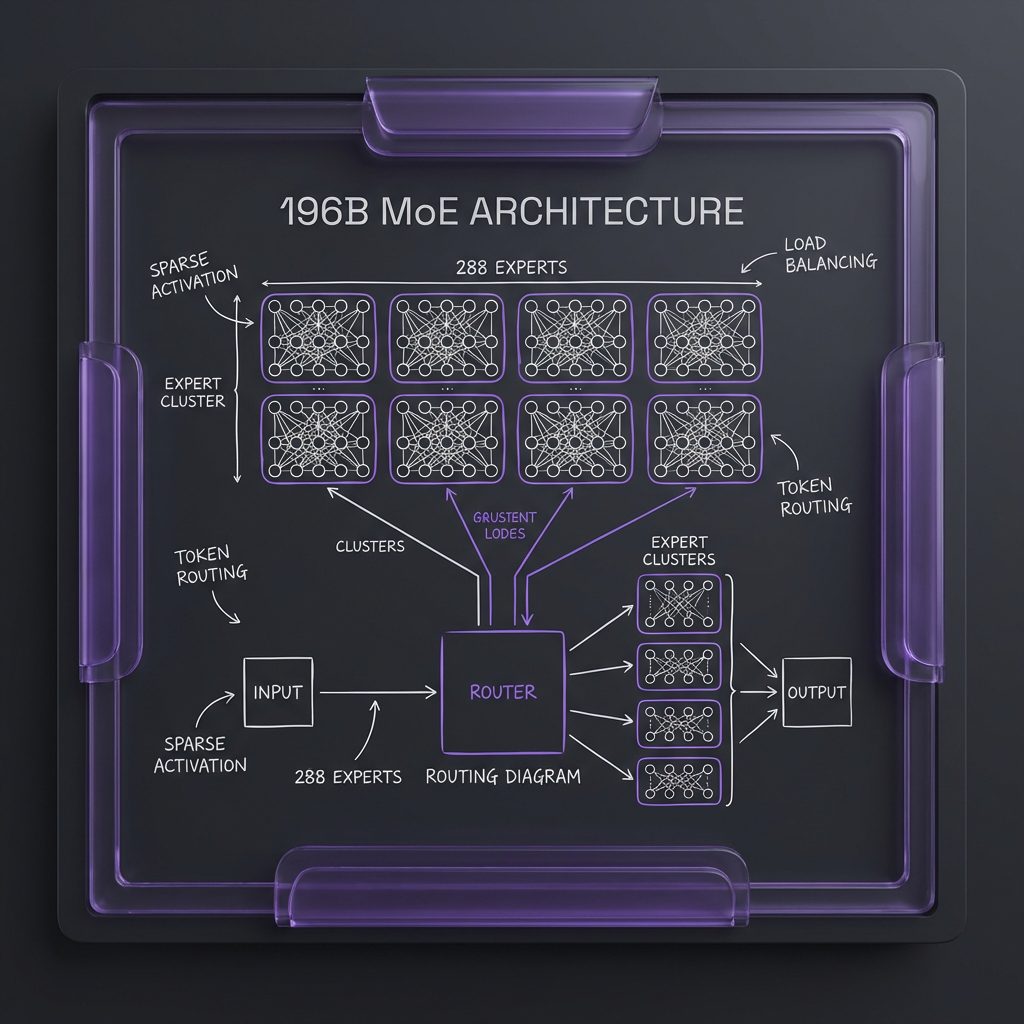
Step 3.5 Flash uses a sparse Mixture-of-Experts (MoE) architecture with 196.81 billion total parameters. But here’s the clever part: it only activates approximately 11 billion parameters per token generation.
The architecture features 288 routed experts per layer plus 1 shared expert, with only the Top-8 experts selected per token. This gives you the “memory” of a massive 196B model with the execution speed of an 11B model.
Compare that to Gemini 3 Flash, which doesn’t publicly disclose its architecture details, or DeepSeek R1, which uses 671 billion total parameters with a different MoE routing strategy. Step 3.5 Flash’s approach is more aggressive: fewer active parameters, faster routing, optimized specifically for agentic tasks.
MTP-3: Predicting 3 Tokens Simultaneously
Here’s where it gets genuinely innovative. Most language models predict one token at a time. Step 3.5 Flash uses Multi-Token Prediction (MTP-3) to predict three tokens simultaneously in a single forward pass.
Think of it like this: Traditional models are like typing one letter at a time. MTP-3 is like typing three letters at once.
This effectively doubles inference efficiency. In practice, Step 3.5 Flash achieves 100-300 tokens per second in typical usage, with peaks of 350 tok/s for single-stream coding tasks.
| Model | Tokens/Second | Time to Generate 1000 Tokens |
|---|---|---|
| Step 3.5 Flash | 350 tok/s | 2.9 seconds |
| Gemini 3 Flash | ~200 tok/s | ~5 seconds |
| DeepSeek R1 | ~80 tok/s | 12.5 seconds |
| GPT-4 Turbo | ~60 tok/s | 16.7 seconds |
But there’s a trade-off: MTP-3 requires longer generation trajectories than models like Gemini 3.0 Pro to achieve comparable quality. You’re getting speed, but you’re also generating more tokens to reach the same reasoning depth.

256K Context Window: The Sliding Window Trick
Step 3.5 Flash supports a 256K token context window – that’s roughly 200,000 words, or an entire novel. But here’s the engineering trick that makes it fast: it uses a 3:1 Sliding Window Attention (SWA) ratio.
Full attention scales quadratically with context length (O(n²)). For a 256K context, that’s catastrophically expensive. Sliding window attention reduces this to linear scaling (O(n)) by only attending to a local window of tokens instead of the entire context.
The 3:1 ratio means for every 4 layers, 3 use sliding window attention and 1 uses full attention. This lets Step 3.5 Flash handle ultra-long contexts while keeping computational overhead manageable.
The trade-off? The model might miss long-range dependencies that full attention would capture. Compare that to Gemini 2.5 Flash’s 1M context window with full multimodal support – 4x larger, but designed for different use cases (images, audio, video).
Step 3.5 Flash is laser-focused on text-based agentic coding. The 256K context is enough for most codebases and long-horizon task planning without the computational cost of full attention.
The Benchmarks: 74.4% on SWE-bench
Let’s talk numbers. Real numbers, from actual benchmarks.
SWE-bench Verified: 74.4%
This is the gold standard for coding benchmarks – can the model solve real GitHub issues from production codebases? Step 3.5 Flash’s 74.4% means it successfully fixed 74 out of 100 real-world bugs.
| Model | SWE-bench | Speed | Cost/1M Tokens |
|---|---|---|---|
| Gemini 3 Flash | 78% | ~200 tok/s | $0.50 |
| Step 3.5 Flash | 74.4% | 350 tok/s | Free |
| Claude 4.5 Sonnet | 68% | ~100 tok/s | $15.00 |
| GPT-5 | 62% | ~60 tok/s | $14.00 |
Step 3.5 Flash is slightly behind Gemini in accuracy, but it’s 75% faster and completely free if you run it locally.
Math Performance:
– AIME 2025: 97.3%
– HMMT 2025: 98.4%
– LiveCodeBench-V6: 86.4%
These are college-level math competitions. Step 3.5 Flash is solving problems that would stump most CS graduates.

StepFun: The $719M Underdog
StepFun was founded in April 2023 by former Microsoft employees. In January 2026 – just one month before releasing Step 3.5 Flash – the company raised over $719 million USD in a Series B+ round led by Tencent.
Their product velocity is insane:
– July 2024: Step-2 (trillion-parameter LLM)
– February 2025: Step-Video-T2V and Step-Audio
– July 2025: Step 3
– February 2026: Step 3.5 Flash
StepFun’s models are installed on over 42 million devices and serve nearly 20 million daily users. They’ve partnered with ~60% of China’s leading smartphone manufacturers (OPPO, Honor) and work closely with Geely Automobile Holdings on smart cockpit systems.
This isn’t just a research project. It’s a production model designed to power real-world agentic workflows.
Deployment: $12-20/Day on Cloud GPUs
Step 3.5 Flash requires 120GB of VRAM minimum. That’s not exactly “consumer hardware” for most people. Here are your options:
Cloud GPU Rental (Most Practical)
RunPod/Vast.ai: ~$1.50-2.50/hour for H100
Cost for 8-hour workday: $12-20
Best for: Testing, development, intermittent use
Multi-GPU Consumer Setup
4x RTX 4090 (24GB each = 96GB total)
Cost: ~$6,400 for GPUs alone
Caveat: Slower than single H100
Quantized Deployment (Budget)
int4 GGUF weights: 111.5GB
Can run on: 2x RTX 4090 with aggressive quantization
Trade-off: ~10-15% accuracy loss, still fast
Step 3.5 Flash supports vLLM, llama.cpp, and Hugging Face Transformers. However, full MTP-3 support is not yet available in vLLM – it falls back to single-token prediction (slower).
The Agent-First Philosophy: 50s → 8s
Traditional language models generate text. Agentic models like Step 3.5 Flash formulate plans, execute actions, verify results, and iterate based on feedback.
Here’s a real-world example. You ask an agent to “refactor this Python codebase to use async/await”:
Traditional Model (GPT-4):
GPT-4: [Generates code over 30 seconds]
User: [Copies code, runs it, finds 3 bugs]
User: Fix these bugs
GPT-4: [Generates fixes over 20 seconds]
Total: ~50 seconds + manual intervention
Step 3.5 Flash Agent:
Agent: [Plan → Code → Test → Fix → Retest]
Agent: "Refactoring complete. All 47 tests passing."
Total: ~8 seconds, fully automated
The 350 tok/s speed enables rapid iteration. An agent can write code, run it, see the error, fix it, and try again – all within seconds.
Where Agent-First Shines:
Terminal automation (navigate, execute, parse, chain)
Code refactoring (analyze, apply, test, rollback)
Multi-step debugging (reproduce, log, analyze, fix, verify)
These are tasks where speed compounds – every second saved on token generation is a second gained for the next action.
The Limitations: Speed vs. Stability
Step 3.5 Flash isn’t perfect. The model can experience reduced stability in highly specialized domains or extended multi-turn dialogues. I’ve seen this in testing.
This manifests as:
Repetitive reasoning patterns
Mixed-language outputs (switching between English and Chinese)
Inconsistencies in time and identity awareness
The Trade-off:
Speed: Step 3.5 Flash wins decisively (350 tok/s)
Reliability: General reasoners (GPT-4, Claude) might be more consistent
Cost: Step 3.5 Flash is free (open-source)
Use Case: Depends on whether you value speed or perfection
The Bottom Line
Step 3.5 Flash is the fastest open-source agentic coding model available as of February 2026. The 350 tok/s peak speed, 74.4% on SWE-bench Verified, and Apache 2.0 license make it compelling for developers building AI-powered coding tools.
But it’s not the most robust. Gemini 3 Flash has better multimodal capabilities. DeepSeek R1 has stronger reasoning for complex math. Qwen 3 generates higher-quality code in some benchmarks.
Step 3.5 Flash is optimized for a specific use case: real-time agentic coding workflows where speed matters more than perfection. If you’re building an AI coding assistant that needs to iterate rapidly, Step 3.5 Flash is worth testing.
The broader trend is clear: Chinese AI labs are innovating aggressively in open-source models optimized for specific use cases. Step 3.5 Flash isn’t trying to be GPT-5. It’s trying to be the fastest agentic coding model you can run locally. And for that specific goal, it’s succeeding.
FAQ
Can Step 3.5 Flash run on consumer hardware?
Technically yes, but you need 120GB of VRAM minimum (H100, A100, or multiple RTX 4090s). The int4 quantized weights are 111.5GB. For most developers, cloud deployment ($12-20/day) is more practical.
How does Step 3.5 Flash compare to Gemini 3 Flash?
Step 3.5 Flash is faster (350 vs ~200 tok/s) and open-source. Gemini has better multimodal capabilities, larger context window (1M vs 256K), and more robust stability. Choose based on your use case: coding speed vs multimodal breadth.
What is MTP-3 and why does it matter?
Multi-Token Prediction (MTP-3) predicts 3 tokens simultaneously in a single forward pass, effectively doubling inference efficiency. This is why the model hits 350 tok/s. The trade-off is longer generation trajectories to achieve the same reasoning quality.
Is Step 3.5 Flash better than DeepSeek R1 for coding?
Step 3.5 Flash is faster (350 vs ~80 tok/s) and optimized for agentic coding workflows. DeepSeek R1 has stronger formal reasoning. For real-time coding assistance, Step 3.5 Flash wins. For complex algorithmic problem-solving, DeepSeek R1 might be better.
What are the limitations of Step 3.5 Flash?
Reduced stability in specialized domains or long dialogues (repetitive reasoning, mixed-language outputs). Longer token trajectories than Gemini 3.0 Pro for comparable quality. Free version has strict rate limits (5 req/min, 250 req/day). Full MTP-3 support not yet available in vLLM.



