
Here’s what happened on February 4, 2026: Google Research published a blog post about an algorithm called Sequential Attention. No press release. No product launch. No Sundar Pichai keynote. Just a quiet technical post on their research blog.
And yet, this might be the most important AI optimization breakthrough of 2026 so far.
While everyone’s been obsessing over bigger models (Claude Opus 4.6’s 1M context window, GPT-5.2’s reasoning capabilities), Google’s been solving a different problem: how do you make AI models dramatically smaller and faster without sacrificing accuracy? The answer is Sequential Attention, an algorithm that solves the NP-hard subset selection problem with mathematical guarantees.
What strikes me about this release is the contrast. Anthropic announces Opus 4.6 and the entire AI community loses its mind. Google drops an algorithm with provable performance guarantees that can prune LLMs, optimize feature selection, and compress neural networks by orders of magnitude, and it barely registers.
But here’s the thing: in the efficiency war that’s quietly reshaping AI, Sequential Attention is a weapon. And Google just open-sourced it.
Figure 1: Sequential Attention – Google’s quiet breakthrough in AI model optimization.
The NP-Hard Problem Nobody Talks About
Let’s start with the problem Sequential Attention solves: subset selection.
Think of it this way. You’re building a neural network with 10,000 potential features (input variables). But you know from experience that most of those features are redundant or useless. The question is: which 100 features should you keep?
This is the subset selection problem, and it’s NP-hard. That means there’s no known algorithm that can solve it efficiently for large datasets. The brute-force approach (try every possible combination) is computationally impossible. For 10,000 features, you’d need to evaluate 2^10,000 combinations. That’s more combinations than atoms in the observable universe.
So what do we do? We use greedy algorithms: start with zero features, then iteratively add the feature that improves performance the most. Repeat until you hit your target size.
The problem? Traditional greedy selection is expensive. At each step, you need to:
1. Train or re-evaluate the model for every remaining feature
2. Calculate the marginal gain (how much each feature improves performance)
3. Select the best one
4. Repeat
For a model with thousands of features, this becomes prohibitively slow. You’re essentially training thousands of models just to pick the right features.
Sequential Attention solves this by replacing expensive re-training with something much cheaper: attention weights.
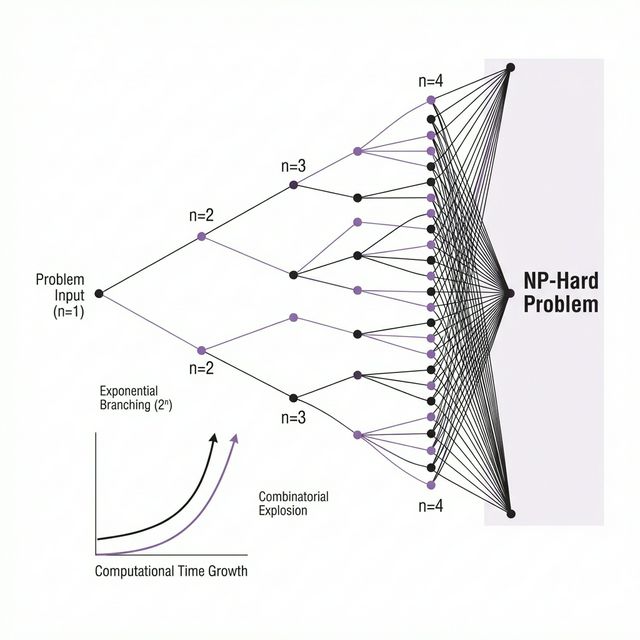
Figure 2: Visualizing the exponential complexity of the subset selection problem and how Sequential Attention tackles it.
How Sequential Attention Works: Greedy Selection Meets Attention
Here’s the core insight: instead of re-training the model to evaluate each feature, Sequential Attention uses the model’s own attention mechanism to estimate importance.
The algorithm works like this:
- Initialize: Start with an empty subset of selected features
- Calculate attention weights: For all remaining unselected features, compute attention scores based on the currently selected features
- Select greedily: Permanently add the feature with the highest attention score
- Recalculate: Re-run the forward pass and recalculate attention weights for the remaining features
- Repeat: Continue until you’ve selected the target number of features
The key difference from standard “one-shot” attention is the sequential nature. In one-shot attention, all candidates are weighted simultaneously. In Sequential Attention, the algorithm builds the subset step-by-step, using previously selected features as context to inform the next selection.
This is crucial because it captures high-order non-linear interactions between features. A feature that looks useless in isolation might be critical when combined with three other specific features. Sequential Attention finds these interactions.
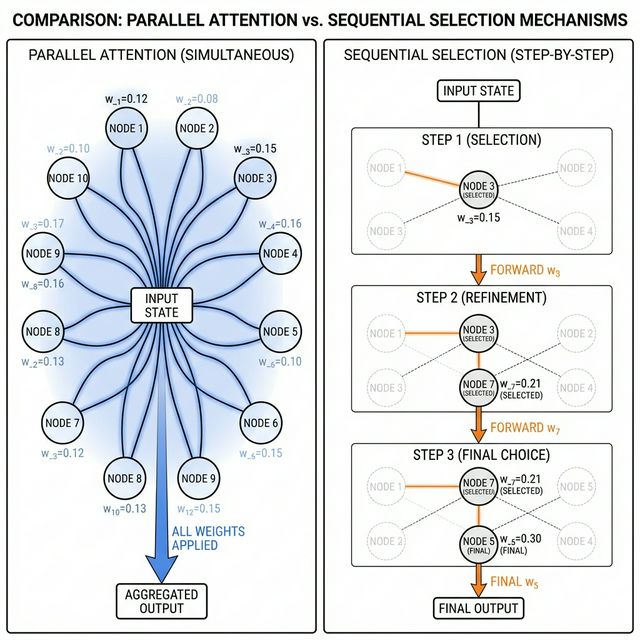
Figure 3: Comparing Sequential Attention’s step-by-step selection with traditional one-shot attention mechanisms.
The Mathematical Guarantee
Here’s where it gets interesting. When applied to simple linear regression, Sequential Attention is mathematically equivalent to Orthogonal Matching Pursuit (OMP), a well-established algorithm with provable performance guarantees.
This equivalence is critical. It means Sequential Attention isn’t just a heuristic that “works pretty well.” It has rigorous mathematical foundations. For linear models, we can prove it will find near-optimal subsets.
For deep learning models, the guarantees are weaker (nonlinearity breaks the mathematical proofs), but empirical results show it consistently outperforms alternatives.
SequentialAttention++: Block Sparsification for LLMs
The original Sequential Attention paper (published in 2022, but largely ignored) focused on feature selection. The 2026 announcement highlights a new application: block sparsification for neural network pruning.
This is where things get practical for LLMs.
Neural network pruning is the process of removing unnecessary weights to reduce model size. The challenge is that random, unstructured pruning doesn’t help much in practice. You need structured sparsity: removing entire blocks, channels, or layers that hardware accelerators (GPUs, TPUs) can actually skip.
Enter SequentialAttention++, an extension of the algorithm designed for block-level pruning. Instead of selecting individual features, it selects which blocks of weight matrices to keep.
The results are impressive. On ImageNet classification tasks, SequentialAttention++ achieved:
– Significant model compression (exact numbers vary by architecture)
– Real-world speedups on GPUs and TPUs (not just theoretical FLOPs reduction)
– Minimal accuracy loss compared to the original dense model
For LLMs, this means you can prune:
– Redundant attention heads
– Entire transformer blocks
– Embedding dimensions
All while preserving the model’s predictive performance.
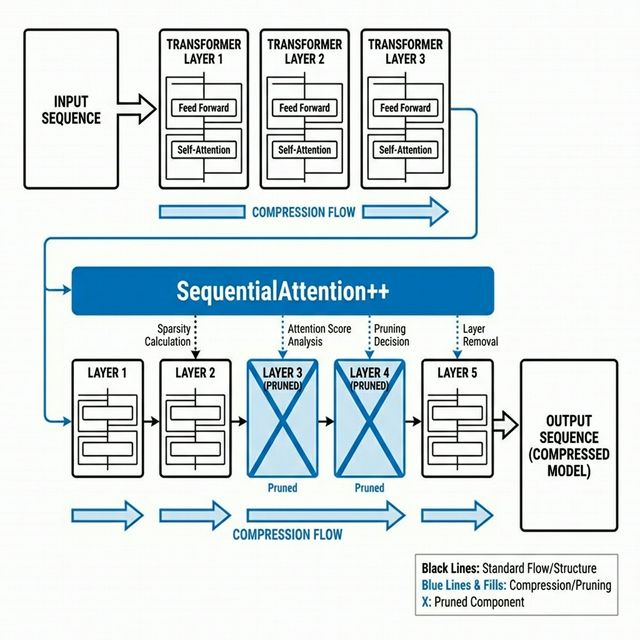
Figure 4: The SequentialAttention++ pipeline for pruning transformer blocks, attention heads, and embedding dimensions in large language models.
Real-World Applications: Where This Actually Matters
Google Research highlights three key application areas for Sequential Attention:
1. Large Embedding Models (LEMs) in Recommender Systems
Recommender systems (think YouTube, Amazon, Netflix) use massive embedding tables to represent users and items. These tables often have thousands of heterogeneous features, and optimizing them is critical for both quality and cost.
Sequential Attention has shown “significant quality gains and efficiency savings” in optimizing the feature embedding layer. This includes:
– Feature selection (which user attributes actually matter?)
– Feature cross search (which combinations of features are informative?)
– Embedding dimension optimization (how many dimensions do we actually need?)
The future direction here is automated, continual feature engineering with real inference constraints baked in.
2. LLM Pruning
This is the big one. As LLMs grow to hundreds of billions of parameters, inference cost becomes the bottleneck. Sequential Attention++ offers a path to:
– Enforce structured sparsity (block-level pruning)
– Prune redundant attention heads and transformer blocks
– Reduce model footprint and inference latency
The key advantage over other pruning methods is the adaptive, context-aware selection. SequentialAttention++ doesn’t just remove the “least important” weights globally. It builds the pruned model step-by-step, ensuring each remaining component is maximally useful given what’s already been selected.
3. Drug Discovery and Genomics
In biological sciences, datasets often have tens of thousands of genetic or chemical features, but only a handful are actually relevant for predicting outcomes (e.g., drug efficacy, disease risk).
Sequential Attention can extract these influential features efficiently, enhancing both interpretability (which genes matter?) and accuracy (better predictions with fewer features).
The Efficiency War: Why This Matters Now
Let’s zoom out. Why does Sequential Attention matter in February 2026?
Because the AI industry is hitting a wall. Not a capability wall, but an efficiency wall.
- Training costs are astronomical (GPT-5.2 reportedly cost $500M+ to train)
- Inference costs are the real bottleneck (serving millions of users is expensive)
- Energy consumption is becoming a regulatory and PR problem
- Model size limits deployment (you can’t run a 400B parameter model on a phone)
The response has been a race to optimize. We’ve seen:
– Quantization (reducing precision from FP32 to INT8 or even INT4)
– Distillation (training smaller models to mimic larger ones)
– Mixture-of-Experts (activating only a subset of parameters per token)
– Context window compression (KV cache optimization)
Sequential Attention adds a new tool to this arsenal: principled subset selection with mathematical guarantees. Instead of ad-hoc pruning heuristics, you get an algorithm that provably finds near-optimal subsets (at least for linear models, and empirically for deep learning).
The fact that Google is highlighting this now, in early 2026, tells me they’re serious about efficiency. They’re not just chasing bigger models. They’re building the infrastructure to make AI leaner, faster, and cheaper.
What This Means For You
For ML Engineers
If you’re working on model optimization, Sequential Attention is a technique worth understanding. The key use cases:
- Feature selection: Reduce input dimensionality without sacrificing accuracy
- Model pruning: Compress neural networks for faster inference
- Architecture search: Identify which layers, blocks, or heads are actually necessary
The algorithm is available in the research literature (arXiv papers linked below), and Google’s blog post suggests they’re actively developing production-ready implementations.
For AI Researchers
The mathematical connection to Orthogonal Matching Pursuit is fascinating. It suggests a broader research direction: can we take classical algorithms with provable guarantees and adapt them to deep learning?
The challenge is that deep learning breaks the assumptions (linearity, convexity) that make proofs possible. But Sequential Attention shows that even without formal guarantees, algorithms inspired by classical methods can outperform ad-hoc heuristics.
For Businesses
If you’re deploying LLMs at scale, inference cost is probably your biggest expense. Pruning techniques like SequentialAttention++ offer a path to:
– Reduce model size by 30-50% with minimal accuracy loss
– Cut inference latency (faster responses)
– Lower cloud compute bills
The tradeoff is upfront engineering effort (pruning requires retraining or fine-tuning), but for high-volume applications, the ROI is clear.
The Bottom Line
Google Research dropped Sequential Attention on February 4, 2026, and the AI community barely noticed. No hype. No fanfare. Just a technical blog post.
But here’s what they actually released: a mathematically grounded algorithm for solving the NP-hard subset selection problem, with applications in feature selection, neural network pruning, and LLM optimization. It’s equivalent to Orthogonal Matching Pursuit for linear models (provable guarantees) and empirically outperforms alternatives for deep learning.
The timing matters. As the AI industry shifts from “bigger is better” to “efficiency is survival,” techniques like Sequential Attention become critical infrastructure. This isn’t about chasing benchmark scores. It’s about making AI models 10x leaner without sacrificing accuracy.
So while everyone’s debating whether Claude Opus 4.6 or GPT-5.2 is “better,” Google’s quietly building the tools to make all of these models smaller, faster, and cheaper.
That’s the real breakthrough.
FAQ
What is Sequential Attention?
Sequential Attention is an algorithm developed by Google Research for solving the subset selection problem in machine learning. It uses a greedy selection mechanism combined with attention weights to iteratively build optimal subsets of features, layers, or model components. Unlike traditional greedy methods, it integrates selection directly into model training, making it scalable to large models.
How is Sequential Attention different from standard attention mechanisms?
Standard attention mechanisms (like those in transformers) weight all candidates simultaneously in a “one-shot” manner. Sequential Attention works step-by-step: it selects one component at a time, using previously selected components as context to inform the next selection. This sequential approach captures high-order non-linear interactions that one-shot methods miss.
What is SequentialAttention++?
SequentialAttention++ is an extension of Sequential Attention designed for block-level neural network pruning. Instead of selecting individual features, it selects which blocks of weight matrices to keep. This enables structured sparsity, which translates to real-world speedups on GPUs and TPUs. It’s particularly promising for LLM pruning.
Can Sequential Attention be used for LLM compression?
Yes. SequentialAttention++ can prune redundant attention heads, embedding dimensions, and entire transformer blocks in LLMs. This reduces model footprint and inference latency while preserving predictive performance. Google Research specifically highlights LLM pruning as a key future application.
What are the mathematical guarantees of Sequential Attention?
For simple linear regression models, Sequential Attention is mathematically equivalent to Orthogonal Matching Pursuit (OMP), which has provable performance guarantees. For deep learning models, the guarantees are weaker due to nonlinearity, but empirical results show it consistently outperforms alternative subset selection methods.
Where can I learn more about Sequential Attention?
The original research paper is available on arXiv: “Sequential Attention for Feature Selection” (2022). The block sparsification extension is detailed in “SequentialAttention++ for Block Sparsification” (2024). Google Research’s blog post (February 4, 2026) provides a high-level overview.



