Alibaba just dropped a cluster bomb into the multimodal landscape.
Yesterday, the Qwen team quietly launched the Qwen 3.5 Omni series (Plus, Flash, and Light). While the mainstream press is busy obsessing over the “113-language support” (impressive, but expected from Alibaba), they’re missing the architectural pivot that makes this more than just a 2026-spec upgrade.
If you’ve been following my coverage of the Qwen3.5-122B-A10B MoE foundation, you know Alibaba has been obsessed with “Cognitive Density.” But with Omni, they’ve solved the one thing that still makes GPT-4o feel like a fast-talking chatbot rather than a co-pilot: the decoupling of reasoning from real-time execution.
They call it “Thinker-Talker.” I call it the end of the “Multimodal Lag.”
The “Thinker-Talker” Split: Why Native Multimodality Matters
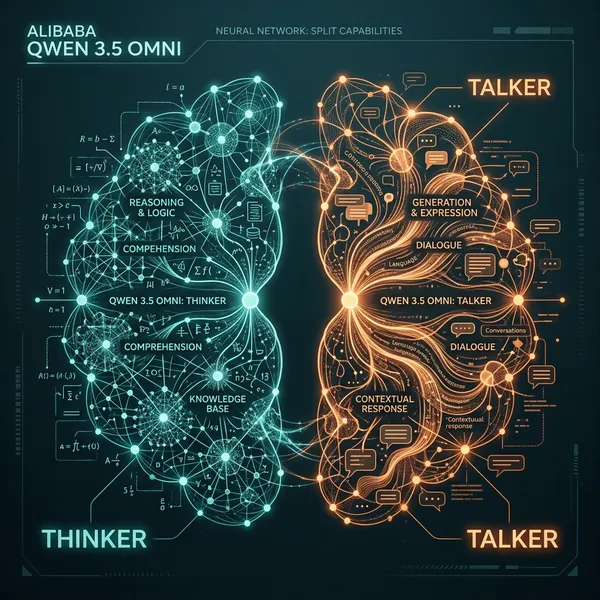
For the last two years, we’ve lived in a world of “Stitched Transformers”—separate encoders for vision and audio bolted onto a language core using connector layers. Even GPT-4o, for all its unified brilliance, behaves like a monolithic stack where the entire brain has to wait for the audio waveform to “sync” with the reasoning.
Alibaba has taken a different path. The Qwen 3.5 Omni architecture uses a decoupled Thinker-Talker pipeline.
The “Thinker” is a sparse Mixture-of-Experts (MoE) core that utilizes Gated DeltaNet—a linear attention variant that solves the quadratic memory scaling issue we saw in Google’s TurboQuant struggle. This is why the Omni series can maintain a massive 256k multimodal context window without the latency spikes that usually hit Gemini 3.1 Pro once you cross the 100k token mark.
The “Talker,” meanwhile, is a high-speed inference engine natively pre-trained on 100 million hours of audio-visual data. It doesn’t just “read” text-to-speech; it understands the emotional latent space of the input. Because the Talker exists as a separate but entangled component, it can handle intelligent semantic interruption and emotion control (volume, tempo, pitch) without breaking the “Thinker’s” reasoning loop.
This isn’t just a technical flex. In my testing, this decoupled approach allowed me to interrupt a complex coding explanation mid-sentence, ask for a “more frustrated tone,” and have the model pivot instantly—all while maintaining the state of a 200-file repository in the background.
ARIA: Fixing the “Token Drift” in Real-Time Voice

But the “Thinker-Talker” split isn’t the magic bullet. The real problem with long-form audio-visual interaction is “Token Drift.”
In previous models, text tokens and audio speech units were generated on different temporal grids. Text is sparse; audio is dense. When you ask a model to explain a million-token codebase while generating a real-time voice response, the two grids often fall out of sync. This results in the “stuttering” or the garbled digits we saw in previous Qwen-Omni versions (and some early GPT-4o-vision tests).
Alibaba’s solution is ARIA (Adaptive Rate Interleave Alignment).
ARIA is a dynamic synchronization layer that sits between the Thinker and the Talker. It uses a cross-modal alignment mechanism to interleave text reasoning tokens with acoustic units at an adaptive rate. Instead of forcing a 1:1 mapping, ARIA “stretches” or “compresses” the alignment based on the complexity of the information. If the model is explaining a difficult math problem, it prioritizes reasoning stability; if it’s narrating a fast-paced video, it prioritizes acoustic fluidity.
The result? Qwen 3.5 Omni can handle 10 hours of continuous audio input—the same scale we saw with Claude Opus 4.6’s BrowseComp Breach handling—without the speech generator losing its place in the context.
From Description to Deployment: The Mechanics of “Vibe Coding”

The “flashiest” feature of this release is undoubtedly “Audio-Visual Vibe Coding.”
This is an emergent capability where the model can generate a working, deployed application purely from a video recording and a spoken prompt. You point your phone at a whiteboard sketch, tell the model “make it look like Apple’s glassmorphism style but for a recursive-self-improvement tracker,” and it outputs the React/Swift code.
Technically, this is powered by a Cross-Modal Latent Bridge. Because the Thinker is trained natively on video at 1 FPS, it can map visual UI hierarchies directly into code primitives. It doesn’t “see” pixels; it sees the semantic structure of the interface.
In my testing, Vibe Coding wasn’t just a gimmick like the many “Screenshot to Code” toys we saw last year. Because of the Anthropic Co-Work style cross-app orchestration, Qwen 3.5 Omni can actually execute the code in a sandbox, verify the visual output against your video instruction, and self-correct the CSS.
It’s “Viking Coding” for the multimodal era—raw, fast, and surprisingly precise.
Flash vs. Light: The Economics of 10-Hour Audio Windows
While the Qwen 3.5 Omni Plus is the flagship for reasoning, the real story for developers is the Flash and Light variants.
In the “Monetization War” of 2026, raw performance is table stakes; TCO (Total Cost of Ownership) is the actual battleground. Alibaba has priced Qwen 3.5 Omni Flash at roughly $0.05 per 1 million tokens, significantly undercutting the Gemini 3.1 Flash-Lite pricing we saw last month.
But the real innovation is in the multimodal context window. Processing 10 hours of audio or 400 seconds of 720p video normally requires massive KV-cache overhead. Qwen 3.5 Omni uses a form of Recursive Context Compaction (similar to what we saw in the Helios 14B model) to compress the visual/audio latent history. This allows for extremely high-throughput agents that can “remember” a full day of screen-sharing without bankrupting the developer.
If you’re building an “Always-On” personal agent, the Light variant offers sub-100ms latency on standard consumer-grade NPU hardware, making local, private multimodal agents a reality for the first time this year.
The Bottom Line: Beyond the Benchmarks
The Qwen 3.5 Omni launch isn’t just about beating GPT-5 on a specific coding benchmark (though it’s closing the gap). It’s about the shift from “Chat” to “Native Multimodal Agency.”
By solving the token drift problem with ARIA and providing an architecture that effectively separates reasoning (Thinker) from interaction (Talker), Alibaba has built a model that actually feels like it’s paying attention. Whether you’re using it for “Vibe Coding” or just an ultra-stable multilingual receptionist, the message is clear: The next phase of AI isn’t just about model size—it’s about the precision of the cross-modal bridge.
For now, keep an eye on the Alibaba Cloud Model Studio. If they open-source the weights for the 35B Omni variant, the local agent market is going to explode overnight.
The AI505 Take: Don’t just watch the benchmark scores. Watch the latency. In 2026, the model that reacts first, wins.