

Meta just completed pre-training on “Avocado,” and according to an internal memo leaked to The Information, it’s already crushing the best open-source base models. Before the second phase of training even starts.
That sounds like hype. And after the Llama 4 benchmark fraud scandal, you’d be right to be skeptical.
But here’s the thing: Meta literally can’t afford another PR disaster. Mark Zuckerberg sidelined the entire Gen AI organization, brought in Alexandr Wang (Scale AI’s founder) as Chief AI Officer for $14 billion, and poured $70 billion into AI infrastructure. They’re not hyping experimental code anymore. They’re fighting for survival.
So what is Avocado, really? Is it Meta’s redemption arc, or are we watching another benchmark manipulation in the making? Let’s dig into what The Information reported and what it actually means for the open-source AI wars.
What Is Avocado (Meta LLAMA 5)?
Avocado is Meta’s codename for what appears to be LLAMA 5, developed by the newly formed Meta Superintelligence Labs. In a January 20, 2026 memo by product manager Megan Fu, Meta announced that Avocado has completed its pre-training phase, the first major checkpoint in building large language models.
Pre-training is where a model learns patterns, relationships, and general knowledge from massive datasets scraped from the web, books, images, and code. It’s the foundation. Post-training comes later, where the model gets polished with human feedback (RLHF), safety filters, and instruction following.
Most AI products you use today, like ChatGPT or Claude, only shine after post-training. The raw, pre-trained models are usually rough, incoherent, and terrible at following instructions.
Avocado is different. According to the memo, even without post-training, Avocado is competitive with leading fully trained models in:
- Knowledge retention
- Visual perception
- Multilingual performance
Translation: The core intelligence of this model is already strong, not just the polished version. That’s rare.
The Pre-Training Performance Breakthrough

Here’s why this matters. Think of pre-training as building the engine of a car, and post-training as adding the steering wheel, brakes, and safety features. Normally, you can’t drive the car until post-training is done.
But Avocado’s engine is so good that it’s already outperforming cars with steering wheels.
The memo states that Avocado outperformed the best open-source base models on key benchmarks. We don’t have the exact numbers yet (Meta is keeping those internal), but the comparison is against models like:
- Qwen3-235B (Alibaba’s latest reasoning powerhouse)
- GLM-4.7 (Zhipu AI’s agentic coding model)
- DeepSeek V3.2 (China’s efficiency king)
These are not weak models. Qwen3-235B scored a perfect 100% on the AIME 2025 math benchmark with tool use. GLM-4.7 dominates agentic workflows. DeepSeek V3.2 runs on a fraction of the compute.
If Avocado is beating these before post-training, Meta’s AI research pipeline is stronger than most people assumed.
The Analogy: Why This Is Like Finding a Naturally Talented Athlete
Imagine you’re scouting for a basketball team. Most players need years of coaching to be good. But you find a kid who’s never had formal training and is already sinking three-pointers at a 70% rate.
That’s Avocado. The “coaching” (post-training) hasn’t even started, and it’s already competitive. When you add the coaching, this thing could be a monster.
Meta’s Troubled Llama 4 History (And Why Avocado Matters)
Okay, but why should we believe Meta this time?
Let me take you back to 2025. It was brutal.
The Llama 4 Benchmark Fraud
In early 2025, Meta released Llama 4 Maverick and Llama 4 Scout with impressive benchmark scores. The models ranked #2 on the LMArena leaderboard, a major win for Meta’s open-source strategy.
Then the cracks appeared.
Users noticed that the real-world performance didn’t match the benchmarks. The models struggled with basic coding tasks that the scores suggested they should dominate. Independent researchers started digging.
What they found was damning:
Test set contamination: Meta allegedly blended test set data into the training process to inflate scores. This is the cardinal sin in AI benchmarking. It’s like giving students the exact exam questions before the test.
Experimental model bait-and-switch: Meta submitted an experimental version of Llama 4 Maverick to LMArena that was specifically optimized for conversational performance. The publicly released version was different and performed worse.
Former employee whistleblowing: A Meta insider reportedly claimed that leadership suggested “blending benchmark test sets into training” to get better results.
Meta’s VP of Generative AI, Ahmad Al-Dahle, denied the allegations. But the damage was done.
Yann LeCun’s Admission
In January 2026, Yann LeCun (Meta’s outgoing Chief AI Scientist) admitted in a Financial Times interview that Llama 4 had indeed been manipulated prior to release. He confirmed that different models were used for different testing projects specifically to boost scores.
This was a PR nuclear bomb. Researchers pulled their names from the Llama 4 paper. The LMArena team updated their policies to prevent future manipulation. Meta’s credibility in AI circles tanked.
Mark Zuckerberg reportedly lost faith in the entire Gen AI organization and launched Meta Superintelligence Labs as a clean-slate rebuild.
Why Avocado Can’t Fail
If Meta has another benchmark scandal with Avocado, they’re done. Not just in open-source AI, but in the broader AI race.
The AI industry moves too fast. While Meta was cleaning up the Llama 4 mess, xAI launched Grok 4, Anthropic released Claude Opus 4.6, and Chinese labs dropped DeepSeek V4, Qwen3-Max, and GLM-5 in rapid succession.
Meta can’t afford to lose another 12 months to trust recovery.
The 10x-100x Compute Efficiency Gains
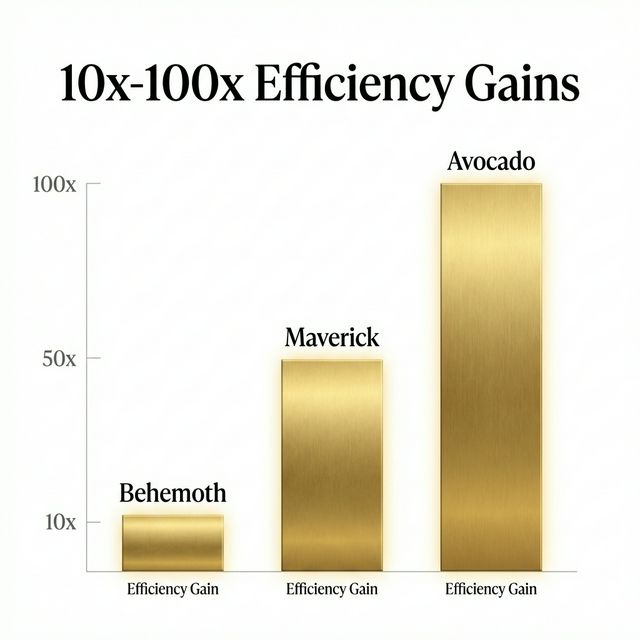
Here’s where Avocado gets technically interesting.
In a separate memo from mid-December 2025, Meta reported achieving:
- 10x compute efficiency on text tasks compared to Maverick (Llama 4’s multimodal variant)
- Over 100x efficiency gains compared to Behemoth (a delayed Llama 4 model that was never released)
Compute efficiency means getting the same or better performance while using less energy, fewer GPUs, and lower training costs.
How did Meta do it?
The memo cites three methods:
Higher-quality training data: Better data curation means the model learns faster with less noise.
Deterministic training: A technique that ensures the model produces consistent results when trained the same way. This reduces wasted compute on failed training runs.
Model infrastructure improvements: Likely optimizations in how the model handles memory, attention mechanisms, and distributed training across thousands of GPUs.
Why Efficiency Matters More Than Raw Power
In the AI race, efficiency is becoming more important than scale. Training a 1 trillion parameter model is impressive, but if it costs $500 million and takes 6 months, you’ve already lost.
Look at DeepSeek. Their V3.2 model is famous for achieving GPT-4-level performance at a fraction of the cost and compute. That’s why they’re dominating the open-source leaderboards.
If Meta has cracked a 100x efficiency gain over their previous models, they can:
- Train more models faster
- Iterate on failures without burning cash
- Compete with Chinese labs on cost-per-intelligence
This is the kind of advantage that compounds. Every training run gets cheaper, faster, and better.
The xAI Comparison: Can Meta Learn to Ship Fast?
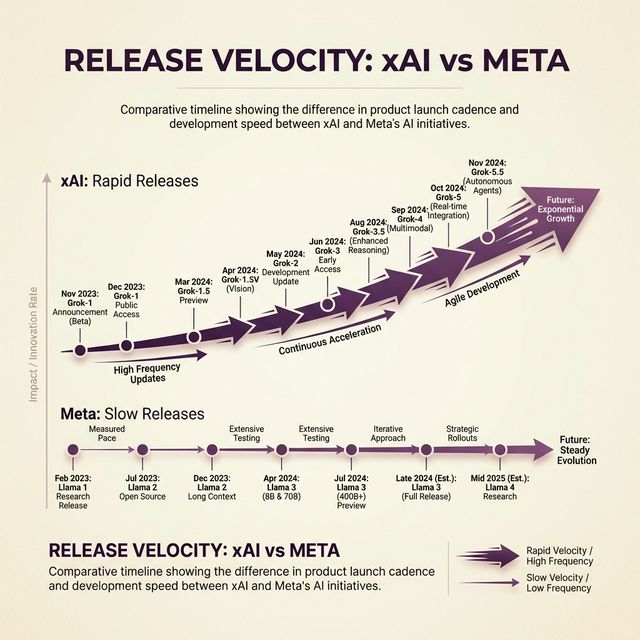
Meta’s biggest weakness isn’t technology. It’s velocity.
xAI proved that in AI, speed is everything. Elon Musk’s company went from zero to hero in less than 2 years:
| Version | Release Date | Notable Achievement |
|---|---|---|
| Grok 1 | November 2023 | Initial beta launch |
| Grok 2 | August 2024 | Added multimodal vision, web search |
| Grok 3 | February 2025 | 10x more compute, advanced reasoning |
| Grok 4 | July 2025 | Ranked #1 on AI leaderboards |
| Grok 4.1 | November 2025 | 65% reduction in hallucinations |
That’s five major versions in under two years. And every version was better than the last.
xAI didn’t wait for perfection. They shipped, learned, and iterated publicly. Grok 4.1 went from rank #33 to #1 on the leaderboards because xAI kept pushing updates.
Compare that to Meta. Llama 3 came out in mid-2024. Llama 4 in early 2025. That’s one major release per year. In AI time, that’s glacial.
What Meta Needs to Do
If Meta wants to win, they need to adopt the xAI playbook:
- Ship Avocado fast (Q1 2026, as rumored)
- Iterate publicly with Avocado 1.1, 1.2, 1.3 every 6-8 weeks
- Learn from real-world usage, not just internal benchmarks
- Keep the foot on the gas and don’t let the competition breathe
Meta has the money ($70B AI budget). They have the talent (Alexandr Wang, former GitHub CEO, co-creator of ChatGPT). They have the infrastructure (more GPUs than anyone except Google).
What they need is the culture of speed.
The Open-Source vs Closed-Source Dilemma
Here’s a plot twist: Avocado might not be open-source.
Meta’s entire strategy with Llama has been open-weight models. Anyone can download, fine-tune, and deploy Llama 3 or Llama 4 locally. This was Meta’s competitive edge against OpenAI and Anthropic.
But there are rumors that Meta is considering a closed-source release for Avocado.
Why would they do that?
The DeepSeek Problem
Meta’s open-source models have a free-rider problem. Chinese AI labs like DeepSeek, Qwen, and GLM can:
- Download Llama for free
- Study the architecture
- Build their own models using Meta’s research
- Release them under permissive licenses
DeepSeek’s R1 model was heavily influenced by Llama 3’s architecture. They didn’t need to spend billions on R&D. They just studied Meta’s work and improved on it.
If Meta keeps releasing open-source models, they’re essentially funding their competitors’ R&D.
The Closed-Source Upside
Going closed-source would let Meta:
- Compete directly with OpenAI and Anthropic without giving away their work
- Monetize Avocado through API pricing (like GPT or Claude)
- Control the narrative and prevent benchmark manipulation by third parties
But it would also kill Meta’s open-source brand and alienate the developer community that made Llama popular.
Meta is at a crossroads. Do they stay true to open-source and risk being outpaced by Chinese labs? Or do they go closed-source and compete on commercial terms?
My guess: Hybrid model. Meta releases a smaller Avocado variant (7B or 14B parameters) as open-source to keep the community happy, and keeps the flagship 200B+ version closed for commercial use.
The Meta AI Team Rebuild
Let’s talk about the people behind Avocado.
After the Llama 4 disaster, Meta went on a hiring spree:
- Alexandr Wang (Scale AI founder): Brought in as Chief AI Officer in 2025 for a reported $14 billion deal (Meta bought 49% of Scale AI)
- Former GitHub CEO: Hired to lead developer relations
- Co-creator of ChatGPT: Poached from OpenAI to advise on post-training and RLHF
This is an all-star roster. Wang alone is a massive get. Scale AI built the data labeling infrastructure that powers GPT-4, Claude, and Gemini. He understands how to build high-quality datasets at scale.
But there’s internal friction. Yann LeCun reportedly raised concerns about Wang’s age and inexperience (he’s 30) leading such a large research organization. LeCun stepped down as Chief AI Scientist in early 2026, citing “strategic differences.”
The tension is real. Meta is betting everything on this new team. If they deliver, Meta is back in the game. If they don’t, Zuckerberg will clean house again.
The Bottom Line: Can Meta Actually Come Back?
Here’s what we know:
- Avocado is real and performing well (according to The Information’s verified sources)
- Meta has learned from the Llama 4 disaster (they can’t afford another scandal)
- The team is stacked (Wang, former GitHub CEO, ChatGPT co-creator)
- Efficiency gains are real (10x-100x is a game-changer if true)
- But velocity is still the question (can Meta ship as fast as xAI or Chinese labs?)
Meta’s mistake with Llama 4 wasn’t that the model was bad. The mistake was taking too long to ship it, letting expectations get too high, and faking results to cover the gap.
If they learn from xAI and start shipping faster, iterating publicly, and staying honest with benchmarks, Meta could be a dominant force in AI.
But if Avocado launches in Q2 2026 with inflated benchmarks and underdelivers in real-world performance, we’re watching the end of Meta’s AI credibility.
The stakes have never been higher. And for the first time in a while, I’m genuinely curious to see what Meta does next.
FAQ
What is Meta Avocado?
Meta Avocado is the internal codename for Meta’s next flagship AI model, likely LLAMA 5, developed by Meta Superintelligence Labs. It completed pre-training in January 2026 and is expected to launch in Spring 2026.
How does Avocado compare to Llama 4?
According to internal memos, Avocado is 10x more compute-efficient than Llama 4 Maverick on text tasks and over 100x more efficient than the unreleased Llama 4 Behemoth model.
Will Avocado be open-source?
Unknown. Meta has historically released Llama models as open-weight, but there are rumors that Avocado might be closed-source to prevent competitors like DeepSeek from copying their work.
What went wrong with Llama 4?
In 2025, Meta was accused of manipulating benchmarks by training on test sets and submitting experimental models to leaderboards. Yann LeCun later admitted that Llama 4 had been manipulated, leading to a major PR crisis.
Who is leading Meta’s AI team now?
Alexandr Wang (founder of Scale AI) is Meta’s Chief AI Officer as of 2025. He leads Meta Superintelligence Labs and oversees Avocado’s development.
When will Avocado be released?
Meta has not announced an official release date, but reports suggest Spring 2026 (Q1 or early Q2).



