

For the last three years, generative video has had a glaring hole: it was silent. You could make a cinematic shot of a cyberpunk city, but it was a ghost town. No sirens, no rain, no dialogue.
To fix it, you had to drag the clip into ElevenLabs or Udio and pray the lips synced up (they never did). Today, that ends. Lightricks – the team behind Facetune – just dropped LTX-2, and it isn’t just another video model. It’s the first open-source foundation model that treats audio and video as a single, unified stream.
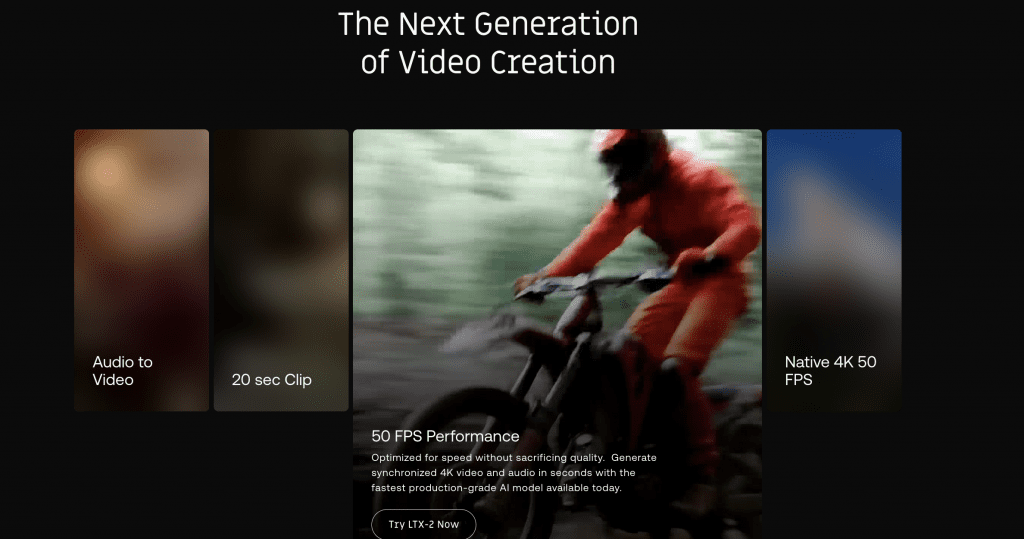
4K, 50fps, and The “Youtube-in-a-Box” Architecture
Most video models (like Sora or Veo) treat sound as an afterthought – a post-processing layer glued on top. LTX-2 is architecturally different.
It uses a Diffusion Transformer (DiT) that generates pixels and waveforms simultaneously. This means the model understands that a closing car door causes a “thud.” The causality is baked in.
The Specs That Matter
- Native 4K Resolution: Not upscaled 1080p. Real 3840×2160.
- 50 Frames Per Second: Buttery smooth motion compared to the industry standard 24fps.
- Synchronized Audio: The killer feature. Lips move with words. Footsteps match the beat.
- Speed: It generates a 6-second Full HD clip in ~5 seconds on consumer GPUs. That’s real-time.

LTX-2 vs Wan 2.1: The Battle for Open Source

Just last week, we were impressed by Wan 2.1. But the landscape moves fast. Here’s the breakdown:
| Feature | LTX-2 | Wan 2.1 | Sora (Closed) |
|---|---|---|---|
| Audio | ✅ Native (Sync) | ❌ Silent | ❌ Silent (Mostly) |
| Max Res | 4K | 1080p | 1080p |
| Frame Rate | 50 fps | 30 fps | 60 fps |
| Open Weights | ✅ Yes | ✅ Yes | ❌ No |
| Speed | ⚡️ Real-time | 🐢 Slow | 🐢 Very Slow |
The “real-time” aspect is crucial. Because LTX-2 is optimized for NVIDIA consumer GPUs (using new NVFP8 quantization), you don’t need an H100 to run it. A 4090 can actually handle this workflow, democratizing high-fidelity video production in a way we haven’t seen since Stable Diffusion 1.5.
What This Means For You
If you’re a creator, the workflow just collapsed from five tools to one.
Old Workflow:
1. Generate Image (Midjourney)
2. Animate Image (Runway)
3. Generate Sound (ElevenLabs)
4. Lip Sync (SyncLabs)
5. Upscale (Topaz)
LTX-2 Workflow:
1. Prompt: “Cinematic shot of a detective speaking in the rain.”
2. Done.
Practical Code Example (Practitioner Mode)
Want to try it locally? Lightricks released the weights on Hugging Face. Here’s the minimal inference code:
import torch
from diffusers import LTXPIpeline
pipe = LTXPIpeline.from_pretrained(
"Lightricks/LTX-2",
torch_dtype=torch.float16,
variant="fp16"
).to("cuda")
video = pipe(
prompt="A cyberpunk street perfomer playing a neon violin, high fidelity audio",
width=3840,
height=2160,
num_frames=250, # 5 seconds @ 50fps
fps=50
).frames
pipe.save_video(video, "ltx2_output.mp4")
The Bottom Line
LTX-2 is the “Stable Diffusion Moment” for video. By open-sourcing a model that handles the hardest part of video generation – audio synchronization – Lightricks has commoditized the entire stock footage industry overnight. And with 4K/50fps, we are perilously close to generating entire movies from a single prompt.
The silent film era of AI is officially over.
FAQ
Can it really run on my GPU?
Yes, if you have a high-end card. A standard RTX 4090 (24GB) is recommended for 4K. For 1080p generation, 16GB cards will suffice.
Is the audio actually good?
It’s surprisingly usable. While it won’t replace a Hans Zimmer score yet, for foley (sound effects) and basic dialogue, it’s miles ahead of disjointed generation techniques.
Is it commercial use friendly?
Lightricks has released the weights under a permissive open license (Apache 2.0 pending confirmation), meaning yes – you can build products on top of this.



