

We’ve all been there: staring at a “cutting-edge” AI model that chokes on basic instructions the moment you ask it to do something slightly complex. You ask for a web scraper, and it gives you a Python Hello World. You ask for a market analysis, and it regurgitates a Wikipedia summary from 2021.
Enter Kimi K2.5.
Moonshot AI just dropped this bombshell, and if the benchmarks are to be believed, we might be looking at the first true agentic powerhouse. We’re talking about a model that doesn’t just “think”—it swarms. With a reported 50.2% score on “Humanity’s Last Exam” (a benchmark name that sounds like it was written by a sci-fi villain), Kimi K2.5 isn’t just playing catch-up; it claims to have leapfrogged GPT-5.2 and Claude Opus 4.5.
But is it all hype, or is the “Swarm” real? Let’s tear it apart.
The “Agent Swarm”: 100 Brains Are Better Than One

Here’s the killer feature that has everyone talking: K2.5 Agent Swarm.
Most “agentic” workflows today are just a single LLM talking to itself in a loop, pretending to be different people. Kimi K2.5 takes a sledgehammer to that approach. It can spin up and orchestrate a literal swarm of up to 100 specialized sub-agents.
Imagine you need to research the entire history of semiconductor manufacturing in Taiwan.
- Agent 1 (The General) breaks it down.
- Agent 2 through 50 go out and scrape financial reports, news archives, and technical papers in parallel.
- Agent 51 fact-checks Agent 12.
- Agent 52 compiles the data into a JSON.
- Agent 53 writes the executive summary.
Moonshot claims this parallel processing makes it 4.5x faster than traditional single-agent setups. It’s not just faster; it’s smarter. By dynamically creating agents for specific tasks (e.g., a “Fact Checker” vs. a “Python Coder”), it avoids the jack-of-all-trades-master-of-none problem that plagues even the best models like Gemini 1.5 Pro. This approach mirrors the Agent Swarms we’ve seen conceptualized by NVIDIA, but now it’s in a production model.
Internally, Moonshot reports a 71.2% win rate on their “AI Office Bench” compared to just 11.9% for their previous K2 Thinking model. That’s not an iteration; that’s a new species.
Visual Coding: From Napkin to Native App

We’ve seen “screenshot-to-code” before. But Kimi K2.5 claims to be “native multimodal” in a way that feels different.
Trained on 15 trillion mixed tokens (text + visual), this thing doesn’t just “see” an image; it understands the logic behind it. You can feed it a video of a user flow or a sketchy wireframe, and it spits out functional, interactive code.
The benchmark here is VideoMMMU, where it scored 86.6%. For context, previous SOTA models were struggling to break 70%. Beating the competition by nearly 20 points in visual reasoning isn’t a “marginal improvement”; it’s a generational leap. If you’re a frontend dev, this might be the moment to start sweating—or celebrating, depending on how much you hate writing CSS.
Comparison: Kimi K2.5 vs The Giants
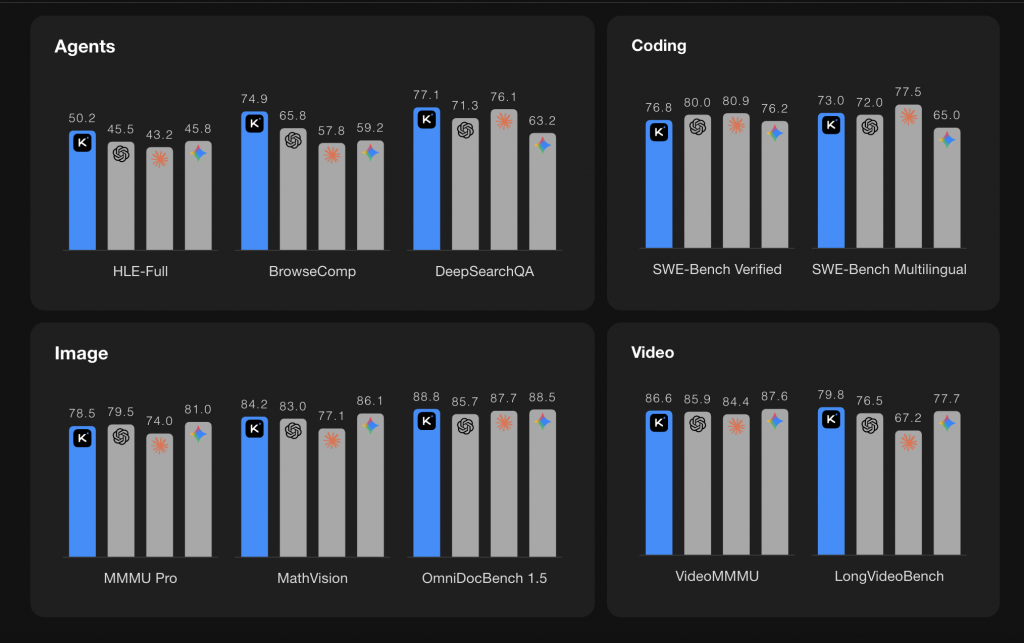
The numbers are out, and Kimi isn’t just competing; in agentic tasks, it’s dominating. Here is how K2.5 (with tools) stacks up against the “Big Three”:
| Benchmark | Kimi K2.5 | GPT-5.2 (xhigh) | Claude 4.5 Opus | Gemini 3 Pro |
|---|---|---|---|---|
| HLE-Full (Reasoning) | 50.2% | 45.5% | 43.2% | 45.8% |
| BrowseComp (Agents) | 74.9% | 65.8% | 57.8% | 59.2% |
| DeepSearchQA | 77.1% | 71.3% | 76.1% | 63.2% |
| OmniDocBench 1.5 | 88.8% | 85.7% | 87.7% | 88.5% |
| VideoMMMU | 86.6% | 85.9% | 84.4% | 87.6% |
| SWE-Bench Verified | 76.8% | 80.0% | 80.9% | 76.2% |
Key Takeaways
1. King of Agents: On HLE-Full and BrowseComp, Kimi K2.5 holds a significant lead. This validates the “Swarm” architecture for complex, multi-step reasoning.
2. Cost Efficiency: Perhaps the most shocking stat is the cost-performance ratio. Moonshot claims Kimi K2.5 is 5.1x cheaper than GPT-5.2 on coding tasks (SWE-Verified) and 10.1x cheaper on high-end reasoning (HLE).
3. Coding Tight Race: While Claude 4.5 Opus still edges it out slightly on raw coding benchmarks (80.9% vs 76.8%), the cost difference might make Kimi the default choice for automated engineering workflows.
Under the Hood: The 15 Trillion Token Monster
Let’s talk specs, because they are massive.
- Architecture: Mixture-of-Experts (MoE).
- Total Parameters: 1 Trillion.
- Active Parameters: 32 Billion (per token).
- Context Window: 256k (enabled by Multi-Head Latent Attention).
This is a beast. The 32B active parameter count strikes a sweet spot—big enough to be smart, but lean enough (thanks to MoE) to be served reasonably fast. This is the same architectural philosophy we’ve seen from DeepSeek, but scaled up.
The 256k context window is also a key player here. It allows the model to hold entire codebases or massive legal documents in memory while its swarm goes to town on them.
The Bottom Line
Moonshot AI has been a quiet contender in the shadow of DeepSeek and OpenAI. With Kimi K2.5, they’ve stepped into the spotlight.
The Agent Swarm feature is the real innovation here. We’re moving away from “chatbots” and towards “task forces.” If K2.5 can reliably orchestrate 100 agents without hallucinating into a spiral of madness, it’s going to change how we think about AI productivity.
Is it the GPT killer? Maybe. Maybe not. But it’s definitely the wake-up call that 2026 needed.
What do you think? Are 100 agents better than one, or just 100 times the chaos? Let us know below.



