

Davos, Switzerland — In a defining moment for the Global South’s technological future, India’s IT Minister Ashwini Vaishnaw has officially pulled the curtain back on the country’s secretive “Sovereign AI” roadmap.
Speaking alongside IBM CEO Arvind Krishna at the World Economic Forum, Mr. Vaishnaw revealed that the Indian government has handpicked 12 specific startups to build the nation’s “Civilizational Intelligence.”
The reveal marks a decisive shift in geopolitical AI strategy. While Silicon Valley races toward Trillion-parameter “God-like” models (AGI), India is placing a massive, state-backed bet on the “Middle Layer”—efficient, 50B-120B parameter models designed to run on local infrastructure, ensuring no Indian data ever crosses borders to US or Chinese servers.
“We are not just building chatbots. We are building the sovereign infrastructure for the next billion users,” sources close to the ministry confirmed.
Here is the full breakdown of the “Sovereign 12” list revealed by the Minister, and why the “50 Billion Parameter” strategy might be the smartest play in the global AI wars.
The Context – From UPI to UII (Unified Intelligence Interface)
To understand India’s AI strategy, you cannot look at 2024 alone. You have to look back at 2010.
India invented the “Digital Public Infrastructure” (DPI) playbook, a model that has no equivalent in the West.
The DPI Stack (Aadhaar -> UPI -> ONDC)
In the US, identity (SSN) is analog, payments (Visa/Mastercard) are private duopolies, and commerce (Amazon) is a private monopoly.
India flipped this:
1. Identity (Layer 1): Aadhaar created a biometric digital identity for 1.3 billion people. A public good.
2. Payments (Layer 2): UPI (Unified Payments Interface) democratized payments. It processes 12 billion transactions a month, more than Visa globally, for zero cost to the user. A public protocol.
3. Commerce (Layer 3): ONDC (Open Network for Digital Commerce) is now trying to break the Amazon/Flipkart duopoly by creating a public commerce protocol.
The Next Layer: “Unified Intelligence”
The IndiaAI Mission is effectively Layer 4. The government views “Intelligence” not as a luxury product to be rented from Microsoft, but as a utility—like electricity or water.
- The Thesis: If AI is the electricity of the 21st century, India cannot afford to have the “grid” controlled by a foreign corporation.
- The Goal: Create a “Unified Intelligence Interface” where sovereign models provide intelligence as a public service—cheap, accessible, and locally hosted.
This “DPI Mindset” is why India isn’t building a closed, proprietary competitor to ChatGPT. It is building a “Mosaic” of models thar are small, specialized, and interoperable and can be plugged into the existing public stack.
The “Walk Before Run” Chip Strategy
You can’t have Sovereign AI without Sovereign Silicon.
For decades, India was a chip design powerhouse (designing chips for Intel/NVIDIA) but a manufacturing zero. That changed in 2024 with a decisive $11 Billion move.
The Tata x PSMC Deal
While the US pushes for the bleeding edge (3nm chips) with the CHIPS Act to support AI training, India made a calculated decision to focus on the Legacy Nodes.
- The Fab: Tata Electronics partnered with Taiwan’s Powerchip Semiconductor Manufacturing Corp (PSMC) to build India’s first commercial fab in Dholera, Gujarat.
- The Technology: 28nm, 40nm, 55nm, 90nm, 110nm.
Why 28nm Matters More Than 3nm
To the tech press, 28nm sounds ancient. The iPhone 15 uses 3nm.
But ask yourself: What runs your electric vehicle? What runs the guidance system of a BrahMos missile? What runs the smart meter in your house or the router in your office?
The Answer: 28nm to 90nm chips.
The Strategy: These “Legacy Nodes” account for 75% of global chip volume.
Phase 1 (2025-2027): Secure the high-volume base. Insulate India’s auto and defense sectors from supply chain weaponization (like the 2021 chip shortage).
Phase 2 (2028-2030): Once the workforce is trained and the ecosystem is live, move to 14nm and eventually 7nm.
The AI Connection: While training immense models requires 3nm GPUs (NVIDIA H100s), running* deployed AI applications at the edge often happens on efficient, older-node chips. India is ensuring it owns the “Inference” hardware layer.
The “Sovereign 12” – A Detailed Profile
The IndiaAI Mission has allocated subsidized compute (from a pool of 10,000+ GPUs) to 12 specific initiatives. These are the chosen ones.
1. BharatGen (Consortium led by IIT Bombay)
The “Mother System”
This is the closest India gets to a state-backed “Manhattan Project” for AI. It is not a startup; it is a consortium of Tier-1 academic institutes (IIT Bombay, Hyderabad, Kanpur) and private partners.
The Mission: Create a Trillion-Parameter foundational model.
The Methodology: Unlike GPT-4, which is a “Black Box,” BharatGen is designed as a “Mother System.” Its primary goal isn’t direct user interaction but the distillation of smaller, domain-specific models.
Example: A 1T parameter BharatGen model ingests all Indian legal history. It then distills a 7B parameter “Legal-LLM” that can run on a lawyer’s laptop in a district court in Bihar, offline.
Data Strategy: They are systematically digitizing India’s “Dark Data”—decades of government records, literature, and scientific texts in 22 languages—that exist only on paper or in non-digitized formats.
2. Sarvam AI (Models: OpenHathi, Sarvam-1)
The Efficiency Kings
Sarvam made headlines with “OpenHathi,” a 7B model built on Llama 2. But their real innovation is in the plumbing.
The Tokenizer Breakthrough: Standard models are terrible at Indic languages. They “over-token” words (breaking a Hindi word into 5-6 tokens), which bloats cost and latency.
Solution: Sarvam extended the Llama tokenizer with 48,000 new Hindi tokens.
Impact: Training and inference on Hindi text became 4x more efficient.
The Product: Sarvam isn’t selling a chatbot; they are selling the “Voice Browser.” They believe the “Next Billion Users” won’t type URLs; they will speak to agents. Their entire stack is optimized for low-latency voice-to-action workflows on $50 smartphones.
3. Krutrim AI (Ola)
The First Sovereign Unicorn
Krutrim (Sanskrit for “Artificial”) is the brainchild of Bhavish Aggarwal (founder of Ola Cabs). It was India’s first AI unicorn ($1B+ valuation) and the most aggressive commercial player.
The Roadmap:
- Krutrim-1 (7B): The base model, released early 2024.
- Krutrim-2 (12B): Native multilingual support, built on Mistral-NeMo architecture, with a massive 128k context window to ingest entire books.
- Krutrim-3 (700B): The planned frontier model to compete with GPT-4.
- The “Western Bias” Fix: Krutrim’s core pitch is cultural. If you ask ChatGPT about Kashmiri history, you get a Western perspective. Krutrim is trained on specific Indian cultural/political datasets to provide a “Sovereign Perspective.”
4. CoRover.ai (BharatGPT)
The Scale Master
You might not know CoRover, but 1 Billion Indians have used their tech. They power AskDISHA, the chatbot for IRCTC (Indian Railways).
The Scale: Handling traffic for the world’s largest railway network is the ultimate stress test.
The Innovation: Conversational UPI.
Scenario: A rural user wants to buy a train ticket but can’t read English or navigate a complex app.
Solution: They speak to BharatGPT in Bhojpuri. The AI checks availability, books the seat, and then triggers a UPI payment request. The user just enters their PIN. No typing, no clicks.
Security: Since they handle public sector data (Police, Railways), their models are deployed in highly secure, sovereign clouds, ensuring citizen data never touches a public API.
5. Tech Mahindra (Project Indus)
The Dialect Keeper
India changes dialect every 50 kilometers. Project Indus is arguably the most culturally significant project.
- The Challenge: Standard “Hindi” models fail on the 40+ dialects (Bhojpuri, Maithili, Awadhi) spoken by 400 million people.
- The Solution: “Civilizational AI.” They crowdsourced voice samples from thousands of people across the “Hindi Belt,” creating a dataset that captures the nuanced intonations of rural India.
- Parameter Count: 1.2 Billion. Intentionally tiny. The goal is to run this on legacy banking terminals or cheap IoT devices in remote villages.
6. Gnani.ai
The Voice Internet Architecture
Gnani tackles the hardest problem in Indian NLP: Code Mixing.
- The Problem: Urban Indians don’t speak Hindi. They speak “Hinglish.” They switch languages mid-sentence (“Ticket book kar do but make sure window seat hai*”).
- The Tech: Gnani has built end-to-end foundation models specifically for this chaotic switching. Their engines power customer service for major banks, automating millions of calls that used to require human agents.
7. Fractal Analytics
The “Reasoning” Engine
While others chase “Chat,” Fractal chases “Thought.”
- The Gap: Large Language Models hallucinate. You can’t have a medical diagnosis AI that lies 10% of the time.
- The Model: A 70 Billion parameter “Reasoning Model”.
- The Approach: Implementation of “Chain of Thought” (CoT) processing at the architectural level. It breaks down complex queries (e.g., “Analyze this X-Ray for early-stage tuberculosis”) into logical steps before answering.
- Target: High-stakes enterprise sectors: Healthcare, Finance, and Insurance.
8. Gan.ai (The Video Wizard)
A direct competitor to HeyGen and Synthesia.
- The tech: Generative Video and Lip-Sync.
- The Roadmap: Moving towards a 70B parameter multi-modal model.
- The Use Case: Hyper-Personalized Communication. Imagine a Prime Minister sending a video message to 100 million farmers. Gan.ai allows that video to be personalized—calling each farmer by name and speaking in their specific local dialect, with perfect lip-sync, generated instantly.
9. Soket AI (The Enterprise Fortress)
Focus: Data Sovereignty.
The Client: Banks and Defense contractors.
The Product: Fine-tuned, efficient foundational models that live inside* the client’s firewall (“On-Prem AI”). This ensures that a bank’s proprietary trading data never trains a competitor’s model.
10. Avataar AI (The Spatial Eye)
Focus: 3D & Spatial Computing.
The Vision: The future of e-commerce isn’t 2D grids; it is 3D experiences. Avataar uses generative AI to instantly convert 2D images into photorealistic 3D assets, preparing Indian commerce for the AR/VR era.
11. NeuroDX / Intellihealth (The Doctor)
Focus: AI for Healthcare.
The Mission: Bridging the doctor-patient ratio gap (1:1456 in India vs WHO norm of 1:1000).
The Model: A sovereign diagnostic model. It doesn’t replace the doctor; it acts as a “Triage Agent” in rural clinics, analyzing symptoms and basic scans to prioritize critical cases for remote specialists.
12. Genloop / Shodh AI (The Pioneer)
Focus: Material Discovery.
The Frontier: Using AI to simulate molecular interactions.
Strategic Value: Discovering new battery materials (for EVs) or efficient solar cell compounds. This is “Deep Tech” in its purest form, moving beyond software into the physical world.
The Geopolitics of AI (The “T3” World)
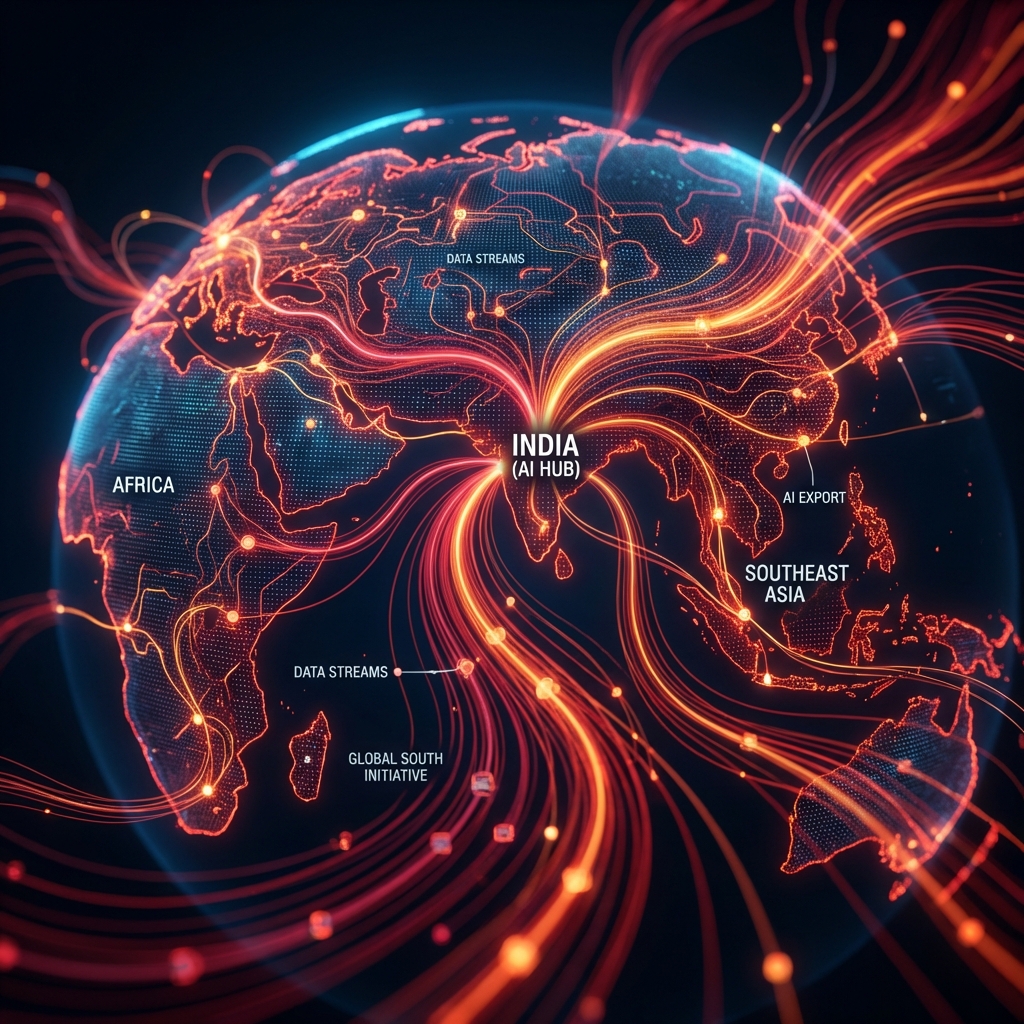
Why does this “Sovereign 12” list matter to the rest of the world?
Because the world is fracturing into three technology blocks.
1. The American Block: Defined by Private Capital, Trillion-Parameter Models, and a race to AGI. (OpenAI, Google, Microsoft).
2. The Chinese Block: Defined by State-Security Fusion, Surveillance, and tight integration with manufacturing.
3. The Indian Block: Defined by Public Digital Infrastructure (DPI), Open Protocols, and Cost-Efficient “Middle Layer” models.
The “Global South” Opportunity
Most of the world (Africa, South America, SE Asia) looks like India, not like Silicon Valley.
- They possess data constraints.
- They have diverse languages.
- They fear “Digital Colonization” (becoming dependent on US tech giants).
India is packaging its AI Strategy—the “India Stack for AI”—as an export product.
The pitch to a country like Nigeria or Indonesia is compelling: “We built a sovereign AI stack that works on $50 phones, speaks 20 languages, and runs on cheap compute. Don’t buy the American model; adopt the Indian model.”
The Impact Summit (Feb 2026)
This strategy culminates in February 2026 at the India AI Impact Summit in New Delhi. This is not just a tech conference; it is a diplomatic maneuver. India intends to officially offer its “AI Stack” to the Global South, positioning itself as the leader of the non-aligned digital world.
Conclusion: The Middle Path
India is betting that the future of AI isn’t just about who builds the smartest god-like intelligence. It’s about who builds the most useful intelligence for the most people.
By focusing on the “Middle Layer”—the 50B parameter models, the 28nm chips, and the public infrastructure—India is building a fortress of technological independence.
The “Sovereign 12” are the guardians of that fortress.



