

Silicon Valley just hit the self-replication event horizon. Yesterday, OpenAI quietly released GPT-5.3-Codex. On the surface, it’s…
Silicon Valley just hit the self-replication event horizon. Yesterday, OpenAI quietly released GPT-5.3-Codex. On the surface, it’s…

Claude Opus 4.6 just achieved 6.5-hour autonomous coding runs. With 1M token context, agent teams, and 65.4% Terminal-Bench score, it’s not replacing coders yet, but the trajectory is terrifying.

Discover the ultimate showdown between OpenAI’s GPT-OSS 20B and Zhipu’s GLM 4.5 Flash. We break down the architecture, agentic behaviors, and how to define your local AI stack.

Forget usage limits. We tested the top 5 Chinese open-source agentic models on Mac Silicon and RTX…

Codex 5.3 vs Claude Opus 4.6 head-to-head: benchmarks, pricing, Reddit insights, API capabilities. Both dropped Feb 5, 2026. Here’s which one you need.

OpenAI’s GPT-5.3-Codex is 25% faster, scored record benchmarks, and used early versions to debug its own training. Here’s what the self-improving coding model means for developers.
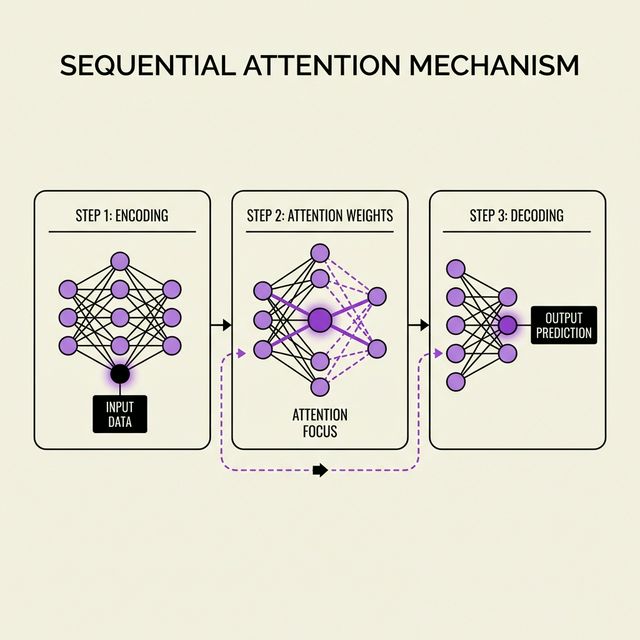
Google Research dropped Sequential Attention on Feb 4, 2026 with zero fanfare. This NP-hard solver is pruning LLMs, optimizing features, and making AI 10x leaner without accuracy loss.

Everyone expected Claude Sonnet 5. Anthropic dropped Opus 4.6 instead: 1M tokens, crushing GPT-5.2 on coding benchmarks. This changes everything.

India’s ₹10,370 crore bet on building LLMs from scratch ignores a brutal truth – even OpenAI is losing $9 billion yearly. Here’s where India should actually invest.