

We’ve been promised “real-time” AI video for years, but it always came with massive asterisks. Sure, it’s real-time, if you string together a supercluster of NVIDIA H100s. But the team at Peking University and ByteDance just dropped a 14-billion parameter model right onto GitHub, and it fundamentally breaks the video generation speed barrier.
The Problem With Long Context Video

Video generation models have a hoarding problem.
To keep a scene consistent from frame 1 to frame 1,000, traditional architectures hold onto the entire history of the generation process. Think of an artist trying to paint a massive, continuous comic strip while physically keeping every previous panel in their direct line of sight. Eventually, you simply run out of desk space. In the AI world, that desk space is the KV cache. It fills up, computation slows to a crawl, and generation speeds drop to a fraction of a frame per second.
When Wan 2.6 and Hunyuan Video launched, they produced stunning quality, but they weren’t fast enough for interactive use cases. We’ve seen similar constraints in images with models like BitDance, where 14B parameters require heavy tuning just to stay responsive.
So how do you fix it? The mainstream approach has been quantization or aggressive self-forcing heuristics. But these brute-force methods usually degrade the visual quality, causing characters to melt or scenes to drift wildly over a minute of video.
Helios takes a completely different path.
Context Compaction: The Sticky Note Engine

Instead of holding onto every frame, Helios acts like a summarizer. It writes a tiny “sticky note” encapsulating the crucial details of the previous scene, clears the desk, and keeps painting.
According to the official arXiv paper released March 4, Helios compresses historical and noisy context across three distinct time scales. By utilizing a dedicated distillation technique, the model cuts down the sampling steps drastically. What strikes me is the efficiency: the computational costs of this 14B parameter model are comparable to, or even lower than, much smaller 1.3B video generative architectures.
This is the exact same philosophy that made small open weights models viable for heavy cognitive lifting, a pattern we highlighted when Chinese labs launched Nanbeige4.1-3B and GutenOCR-3B. The secret isn’t just parameter count; it’s how you route the data.
In developer benchmarks, the distilled version of Helios reaches an absurd 19.53 FPS on a single NVIDIA H100. It also hits roughly 10 FPS on a single Huawei Ascend NPU. And it does this while supporting a unified input representation that natively handles text-to-video, image-to-video, and video-to-video seamlessly.
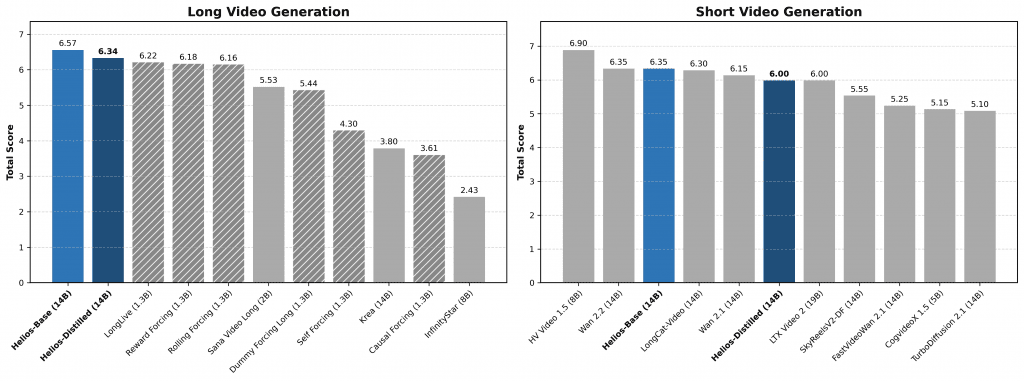
For short videos (81 frames), Helios scored 6.00 overall on HeliosBench, surpassing nearly every distilled model on the market. For minute-long videos, it scored 6.94, dethroning previous leaderboards.
The Physics Constraint: Why Context Still Costs Money
Let me be direct: 19.5 FPS doesn’t mean you’re running this on your MacBook tomorrow.
We have to acknowledge the hard constraints of silicon physics. Achieving 19.5 FPS still requires the massive 80GB memory bandwidth of an enterprise-grade GPU. An H100 costs north of $30,000. So while the software is open source and highly optimized, the hardware required to achieve true real-time interactivity remains firmly in the datacenter.
But what nobody’s asking is what happens when you slice this model up. If a 14B model can run at nearly 20 FPS on datacenter hardware without KV cache destruction, a scaled-down 3B or 7B version deploying similar context compaction could absolutely run interactively on a high-end consumer GPU.
| Feature | Helios 14B (Distilled) | Traditional 14B Video Models |
|---|---|---|
| Generation Speed | 19.5 FPS | < 1 FPS |
| Anti-Drifting | Native Training Simulation | Heuristics / Self-Forcing |
| Memory Management | Context Compression | Expanding KV Cache |
| Unified I/O | Yes (T2V, I2V, V2V) | Usually Task-Specific |
What This Means For You
For product builders, the math just changed.
The barrier to building interactive, AI-generated video applications hasn’t been quality; it’s been latency. If a user has to wait 45 seconds for a 5-second video clip to render, you can’t build a real-time gaming or dynamic UI experience.
With models like Helios breaking the 15 FPS barrier, we’re crossing the critical threshold where video generation stops being an asynchronous batch process and becomes a synchronous API call. Imagine NPC dialogue in a game where the visual facial expressions and scene lighting are generated entirely on the fly by an AI model, matching the exact tone of a dynamically generated script.
The Bottom Line
ByteDance and Peking University just gave the open-source community a masterclass in architectural efficiency. By solving the memory bloat problem of long video generation, Helios proves that you don’t need a supercomputer to render a minute of high-quality AI video—you just need a smarter way to remember the past.
FAQ
Does Helios require an H100 to run at all?
No. While it achieves its 19.5 FPS benchmark on an H100, the model is open weight and can be run on consumer GPUs like the RTX 4090, albeit at significantly lower frame rates.
Why is an autoregressive diffusion model faster?
Helios uses a unified input representation and aggressively compresses historical data. Rather than processing the entire expanded history of a video clip, it summarizes past frames, bypassing the typical computational bottlenecks found in traditional diffusion architectures.
Is Helios fully open source?
The base model, the distilled model, and the implementation code have been released by the PKU-YuanGroup on GitHub and Hugging Face for community use and research.



