When Google Research dropped the TurboQuant paper earlier this month, the implications cascaded through the industry immediately. The algorithm promised to compress the Key-Value (KV) cache—the massive, ever-expanding memory footprint required to maintain state in an LLM conversation—by a staggering 6x.
With zero measurable accuracy loss up to 104k tokens and an 8x inference speedup on NVIDIA H100 hardware, it looked like the elusive silver bullet the cloud infrastructure market was desperate for.
The announcement triggered a brief panic among memory chip manufacturers, echoing the geopolitical and supply chain fragilities we noted when examining the semiconductor physical constraints and the TSMC kill switch. If we can shrink memory requirements mathematically, we become marginally less dependent on the silicon hardware ceiling.
But if you look past the headlines and the corporate PR, the real story of TurboQuant is a tale of two distinct realities: mathematically profound “data-oblivious” compression, entirely overshadowed by one of the most intellectually dishonest benchmarking scandals of the year.
This isn’t just a story about a new algorithm. It is a story about the physics of GPU memory, the mathematical elegance of high-dimensional space rotations, and the ruthless academic politics of the corporate AI arms race.
The Physics of the Constraint: Why Your GPU is Starving

Before we can appreciate what TurboQuant actually does, we need to examine the macroeconomic and physical forces driving the necessity of this algorithm. The modern Large Language Model is not constrained by its ability to “think” (compute); it is constrained by its ability to “remember” (memory bandwidth).
When you send a prompt to an LLM, the attention mechanism must calculate the relationships between every single token you just submitted and every token it is about to generate. To do this efficiently without recalculating the entire history from scratch for every new word, the model stores the mathematical representations of past tokens in a repository called the Key-Value (KV) cache.
In a world of 1M-token context clashes like Gemini 3.1 Pro vs Claude Opus 4.6, the KV cache becomes a structural nightmare. Every single token requires memory allocation. As the conversation grows, the cache expands linearly.
On a standard 70B parameter model, a massive context window can easily balloon the KV cache to over 100GB of VRAM—meaning you need multiple $30,000 NVIDIA H100 GPUs exclusively dedicated to holding memory, not even executing forward passes.
This is the “Memory Wall.” Compute speeds are scaling exponentially, but memory capacity and bandwidth (HBM3e) are scaling linearly due to the physical limits of semiconductor packaging. TSMC cannot weave copper interconnects much closer together without thermal breakdown.
Therefore, if the hardware cannot scale fast enough, the software must shrink the payload. That is exactly what Google attempted to solve.
The Vacuum Seal vs. The Foam Insert
To understand why TurboQuant is mathematically profound, we have to look at the industry standard it seeks to replace: Product Quantization (PQ).
For years, compressing high-dimensional vectors (like those in the KV cache) relied heavily on Product Quantization. Think of PQ like cutting bespoke foam inserts for a pelican camera case. You have to measure the specific equipment first (analyzing the AI’s training data), learn its contours (using k-means clustering), and precisely cut the foam (generating the codebook).
The fundamental flaw with PQ is that it is highly data-dependent. If the data distribution shifts—like an LLM suddenly switching from generating Python code to writing Arabic poetry—the bespoke foam insert no longer fits tightly around the new data structures. The compression falters, and the accuracy degrades.
Worse, traditional quantization frameworks require the model to store “scaling constants” for every single block of data. These scaling constants act as the instructions for how to unpack the compressed data back to its original size. Storing these instructions creates a persistent “memory overhead” that aggressively eats into the theoretical compression gains. You think you are getting 4-bit compression, but the actual VRAM footprint reads closer to 6 bits because of the overhead.
Google’s TurboQuant throws away the foam insert and uses a vacuum seal.
It is entirely data-oblivious. The algorithm does not need to analyze or look at the data beforehand, entirely eliminating the need for calibration datasets, k-means clustering, or pre-training analysis. This makes it a plug-and-play solution that can be injected into an active inference pipeline dynamically.
How does it achieve this? Through a two-stage mathematical process that is as elegant as it is unconventional.
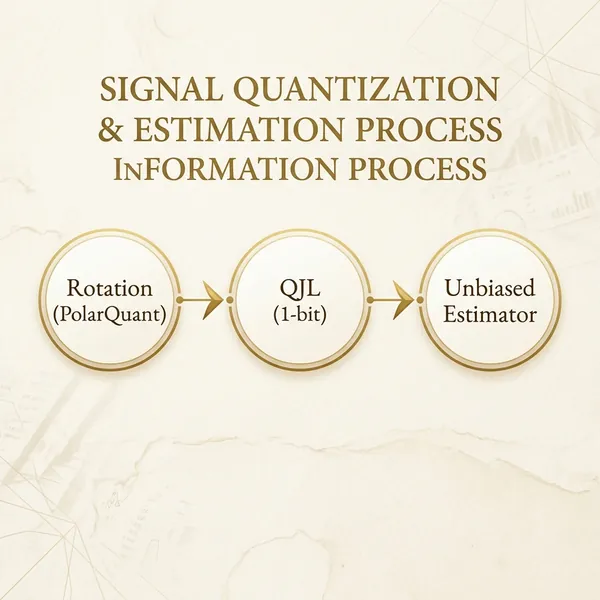
The Math: PolarQuant and The Hadamard Rotation
The first stage of TurboQuant’s pipeline is an algorithm dubbed PolarQuant.
The greatest enemy of any quantization (compression) algorithm is the “outlier.” In modern LLMs (especially the prominent Llama 3 architectures), neural network activations are not smooth. They suffer from massive, unpredictable spikes—outlier tokens that contain extreme numerical values. If you try to compress a sequence of numbers containing extreme spikes down to 3 bits (numbers between 0 and 7), those massive spikes destroy the resolution of the smaller, normal numbers. They blow out the scale.
PolarQuant solves the outlier problem not by clamping them down, but by rotating the entire mathematical space. It applies a random, high-dimensional mathematical rotation to the incoming activation vectors.
Imagine you have a sandbox with several massive, jagged peaks of sand (the outliers). PolarQuant is the mathematical equivalent of violently shaking the sandbox until the peaks collapse and the sand levels out into a perfectly uniform, flat surface. By randomly rotating the vector space (often utilizing structures similar to Hadamard matrices), the extreme values are distributed evenly across all dimensions. The space becomes a predictable, Gaussian-like distribution.
Because the distribution is now uniformly predictable across every single dimension, taking the exact same shape regardless of what the LLM is talking about, TurboQuant no longer needs to store those bloated, block-specific scaling constants. The memory overhead is eradicated in an instant.
1-Bit QJL: The Residual Unbiased Estimator
However, no compression algorithm is perfect. When you map complex floating-point numbers down to coarse integers, you inevitably introduce rounding errors. In traditional models, these microscopic rounding errors compound during the attention mechanism’s massive multiplications, eventually causing the LLM to hallucinate or lose structural coherence.
This is where the second stage of Google’s pipeline comes in. The algorithm applies a 1-bit Quantized Johnson-Lindenstrauss (QJL) transform specifically to the residual error left over from the first stage.
The QJL transform does not attempt to “fix” the error perfectly. Instead, it acts as an unbiased mathematical estimator.
In statistical mathematics, an unbiased estimator guarantees that while individual data points might be slightly wrong (noisy), the expected average value across a large sample size will always hit the exact true target. When the LLM’s attention mechanism calculates the “inner product” (the mathematical operation that determines how much one token should pay attention to another), it sums up thousands of these values.
The genius of using 1-bit QJL is that the rounding errors mathematically cancel each other out during the summation process. The final attention score is practically identical to what it would have been uncompressed. It is a stunning, training-free way to squeeze 32-bit keys into effectively 3 bits.
According to Google’s testing on Needle-In-A-Haystack benchmarks, the model retrieves facts buried deep inside a 104k token context window with zero measurable degradation in logic or accuracy.
The CPU vs. A100 Benchmarking Scandal
If the math is this elegant, and the physical constraints of the industry so desperately require a paradigm shift, why is the open-source community radiating venom at the TurboQuant paper?
The controversy revolves entirely around how Google chose to benchmark TurboQuant against its primary open-source competitor: a widely-respected KV compression framework known as RaBitQ, developed by researchers including Gao Jianyang.
In the hyper-competitive, fast-paced ecosystem of AI research, claiming “SOTA” (State of the Art) is everything. It drives funding, corporate prestige, and talent acquisition. But the methodology the Google team used to establish that claim is drawing intense, justified fire from across the engineering spectrum.
According to community practitioners, researchers, and prominent figures analyzing the ICLR 2026 paper submission, Google’s team allegedly evaluated the RaBitQ baseline unfairly. To showcase RaBitQ’s “slow” performance, researchers translated the baseline algorithm into unoptimized Python code and executed it on a single-core CPU. Meanwhile, they benchmarked their own TurboQuant algorithm on highly optimized, bare-metal NVIDIA A100 and H100 GPU clusters running custom CUDA kernels.
“They benchmarked RaBitQ in Python on a single CPU core while running their own code on an A100. That’s not science, it’s marketing,” a prominent open-source practitioner noted on a viral Reddit thread analyzing the paper’s methodology.
The AI community is intensely critical of the paper’s intellectual honesty. This is not perceived as accidental or sloppy methodology. Open-source developers are accusing the Google team of deliberately misrepresenting RaBitQ’s theoretical framework as “suboptimal latency” by forcing it to run on hardware incapable of matrix multiplications at scale.
Furthermore, critics argue the paper brazenly ignores highly relevant prior work in data-oblivious quantization, such as the DRIVE framework, choosing instead to present PolarQuant as an entirely novel invention born in a vacuum.
This specific kind of academic maneuvering feels deeply familiar. It closely mirrors the PR theatrics we saw during the recent Anthropic vs DeepSeek distillation accusations, where valid technical realities were buried underneath aggressive, narrative-driven corporate marketing designed to protect enterprise margins.
RaBitQ’s Defense: The Open Source Reality
To understand the depth of the frustration, we must look at what RaBitQ actually is. RaBitQ is not some obscure, poorly coded thesis project. It is a highly optimized, community-vetted mathematical framework designed specifically to perform integer quantization on local hardware without incurring massive perplexity loss (hallucinations).
When run fairly on similar GPU architectures, community benchmarks indicate that RaBitQ holds its own remarkably well. While TurboQuant’s PolarQuant rotation is indeed a novel mathematical shortcut for eliminating activation outliers, RaBitQ’s scaling algorithms have already proven effective in massive, sustained inference workloads on consumer hardware.
The open-source community’s anger stems from a broader pattern of corporate extraction. Mega-cap tech entities frequently parse Discord servers, arXiv pre-prints, and GitHub repositories for brilliant structural optimizations engineered by independent researchers. These corporations then repackage the math, wrap it in millions of dollars of compute testing, patent the specific deployment mechanism, and publish a splashy paper claiming total supremacy while simultaneously diminishing the foundational work that enabled the leap in the first place.
The mathematics behind TurboQuant are practically undeniable. The 6x compression is real. The 8x speedup on H100s is real. But the PR damage resulting from an attempt to bury an open-source competitor beneath an asymmetrical, bad-faith hardware test leaves a permanent asterisk next to the paper’s legacy.
What This Means For You: The Local AI Supercycle
Setting aside the academic drama, what does TurboQuant actually mean for the deployment of agentic models on a structural level?
For enterprise cloud providers and hyperscalers (AWS, Azure, Google Cloud), the algorithm represents a massive financial and physical reset. When you are managing the server infrastructure required to support millions of concurrent API calls, the KV cache is precisely where your profit margins go to die. Every gigabyte of HBM VRAM costs premium lease rates. Reducing that memory footprint structurally by 6x means you can pack significantly more concurrent enterprise users onto a single H100 server node without expanding the physical hardware footprint of the data center. This will inevitably drive down API costs for developers over the next several quarters.
But frankly, the far more exciting implication of this mathematics is for local deployment and independent engineering.
The KV cache is the primary reason your localized agentic workflows crash with CUDA Out-Of-Memory (OOM) errors during long, autonomous reasoning loops. If open-source implementations of TurboQuant—or mathematically equivalent implementations of RaBitQ refined by the community—become integrated natively into consumer inference engines like vLLM or llama.cpp, the ceiling for local, standalone AI changes overnight.
Consider the reality of echoing the pain points of running massive 70B models on heavily constrained 4GB GPUs with AirLLM. If a developer can compress the context window by a factor of 6 natively via runtime rotation, the constraints open dramatically. We are looking at a near-future parameter explosion where independent software engineers can sustain massive, hyper-logical, multi-turn code generation context windows for models like Qwen3.5-122B or deep reasoning agents entirely on standard, consumer grade 24GB GPUs (like the RTX 3090, 4090, or upcoming 5090 ecosystems).
This strips the monopoly of infinite context windows away from the hyperscalers and hands it directly to the independent ecosystem.
The Bottom Line
TurboQuant decisively proves that the era of memory-heavy, data-dependent Product Quantization is rapidly concluding. We are transitioning permanently toward the dynamic, data-oblivious mathematical folding of data that occurs natively precisely at runtime. This represents one of the most mechanically significant leaps forward we have documented in overcoming the imposing GPU memory wall.
It clears the path for infinite-context models to operate uninhibited by thermal hardware limits.
It is just an immense shame that an algorithmic breakthrough this elegant and foundational was unnecessarily wrapped in a benchmarking methodology designed intentionally to obscure the truth rather than illuminate it.
FAQ
What exactly is the KV Cache in AI Models?
The KV (Key-Value) cache is the short-term working memory of a Large Language Model architecture. It stores the complex mathematical representations of the tokens it has already observed or generated so it doesn’t have to redundantly re-calculate the entire history of the conversation every single time it predicts a new word.
Why is TurboQuant structurally better than Product Quantization (PQ)?
Traditional Product Quantization requires deep statistical analysis of a dataset beforehand to build custom metric “codebooks” (which introduces massive latency) and demands auxiliary memory strictly to store scaling vectors. TurboQuant applies a random, data-independent mathematical rotation (PolarQuant) that flattens outliers instantly, making the compression highly memory efficient and deployable without any pre-training data access.
Does compressing the model by 6x degrade the AI’s actual intelligence?
According to empirical benchmarking on rigorous Needle-In-A-Haystack extraction tests up to 104,000 tokens, the 3-bit quantization achieves effectively zero measurable accuracy loss. This indicates the AI model recalls hyper-specific details buried deeply in massive context windows just as effectively as the entirely uncompressed base model.
Why does a CPU vs A100 test matter in AI Benchmarking?
Benchmarking a highly parallelized mathematical algorithm designed for matrix multiplications on a single-core CPU is akin to testing a Formula 1 car’s top speed while driving it through three feet of mud, and then comparing that time to a competitor driving on a freshly paved track. It physically starves the algorithm of the architecture it was built to utilize, guaranteeing a catastrophic outcome.