The race just got weird. On February 11, 2026, China’s Zhipu AI dropped GLM-5—a 744-billion-parameter open-source monster trained entirely on Huawei Ascend chips—with API pricing 80% cheaper than Claude Opus 4.6. Six days earlier, Anthropic unleashed Opus 4.6 with a 1-million-token context window and a 144 Elo lead on knowledge work.
One costs a dollar per million tokens. The other costs five dollars. Both claim to be the best agentic coding model on the market.
So which one actually wins? I’ve spent the last 48 hours comparing benchmarks, burning through API quotas, and reading Reddit developers losing their minds over quota consumption. Here’s what everyone’s getting wrong.
The Real Story: It’s Not About Speed, It’s About Money
Let’s cut through the marketing. GLM-5 isn’t faster than Opus 4.6. It’s not smarter. It doesn’t have a bigger context window (200K vs 1M tokens). But it’s 5x cheaper and fully open-source under the MIT License.
That’s not a feature. That’s a business model assault.
Anthropic’s Opus 4.6 burns tokens like a Lambo burns premium gas. Developers on r/ClaudeAI reported their 5-hour coding sessions shrinking to 30 minutes with Agent Teams enabled.
One user typed ls in Claude Code, canceled within seconds, and watched 16% of their quota vanish. The verbosity is real—Opus 4.6 runs automatic repo exploration, builds workspace understanding, and reads files “to be safe” before answering simple prompts.
GLM-5? It’s the Honda Civic of AI. Gets the job done. Doesn’t ask your bank account for permission first.
The Benchmark War: Where They Actually Compete
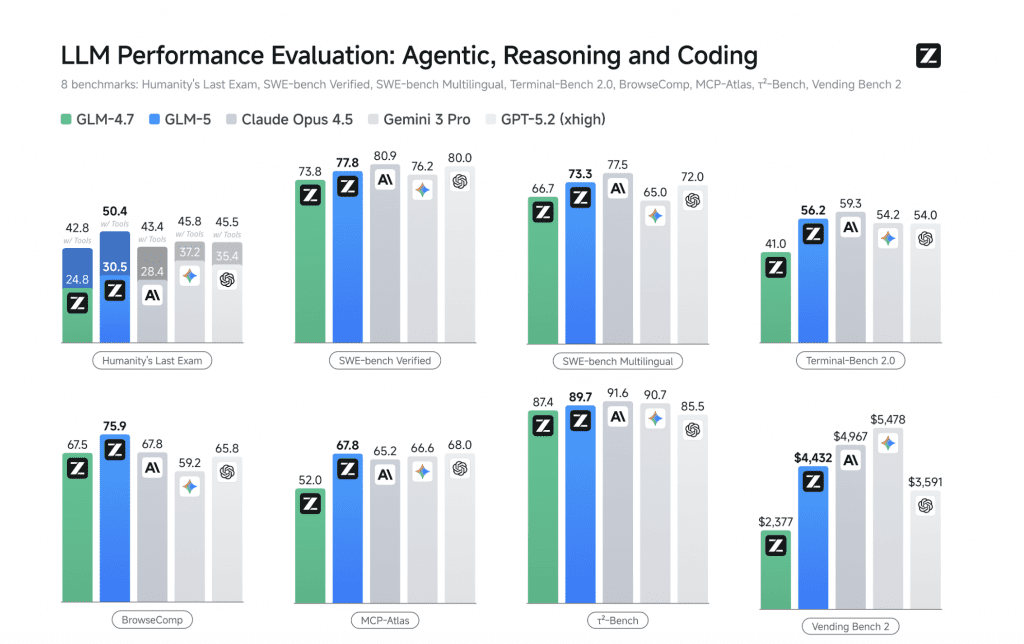
Here’s where it gets interesting. Both models are top-tier on SWE-Bench Verified, the gold standard for real-world coding:
| Benchmark | GLM-5 | Opus 4.6 | Winner |
|---|---|---|---|
| SWE-Bench Verified | 77.8% | 80.8% | Opus 4.6 (+3%) |
| Terminal-Bench 2.0 (Agentic Coding) | 56.2% | 65.4% | Opus 4.6 (+9.2%) |
| GDPval-AA (Knowledge Work) | N/A | 144 Elo lead vs GPT-5.2 | Opus 4.6 |
| ARC AGI 2 (Novel Problem-Solving) | N/A | 68.8% | Opus 4.6 |
| Price (Input / Output per 1M tokens) | $1 / $3.20 | $5 / $25 | GLM-5 (80% cheaper) |
The 3% gap on SWE-Bench is negligible. What stands out: Terminal-Bench 2.0, where Opus 4.6 pulls a 9.2-point lead. This benchmark simulates shell-based workflows—planning, executing bash commands, debugging across files. It’s the closest proxy to how agentic coding actually works in production.
Opus 4.6’s win here isn’t luck. It’s adaptive thinking, a feature that lets the model adjust reasoning depth based on task complexity. GLM-5 doesn’t have this—it’s a one-speed machine.
But here’s the twist: GLM-5’s performance on agentic tasks like BrowseComp, MCP-Atlas, and τ²-Bench is open-source state-of-the-art (SOTA). It’s beating every other freely available model on the leaderboard, including MiniMax M2.1 and GLM 4.7.
The Real Differentiator: Context Window (And Why It Matters)
Opus 4.6’s 1-million-token context window is the headline feature. That’s roughly 750,000 words—the entire Harry Potter series in a single prompt. GLM-5’s 200K context window? About 150,000 words. Not bad, but not revolutionary.
Why does this matter? Knowledge work. If you’re analyzing a massive codebase, reviewing patent portfolios, or processing legal documents, Opus 4.6’s 76% MRCR v2 score means it actually remembers what it read 700,000 tokens ago. GLM-5 can’t touch that.
But for most developers? 200K tokens is enough. That’s 50,000 lines of code. Unless you’re debugging the Linux kernel (which, ironically, Anthropic researchers did for $20,000 in API costs), you’re not hitting that ceiling.
The Open-Source Gambit: China’s Real Play
GLM-5 was trained entirely on Huawei Ascend chips—not a single NVIDIA GPU. Zhipu AI open-sourced the weights under the MIT License on Hugging Face, making it the most powerful openly accessible model for agentic coding.
This is Beijing’s chess move. While Anthropic locks Opus 4.6 behind premium tiers and quota walls, China is flooding the market with production-ready alternatives that developers can run locally. The message: “You don’t need Silicon Valley’s permission to build intelligent agents.”
And it’s working. Reddit’s r/LocalLLaMA is split—some are praising GLM-5’s SWE-Bench performance, others are frustrated that 744 billion parameters (with 44 billion active) makes local deployment impossible without 256GB+ RAM. One user with a Mac M3 Ultra gave up entirely, saying they can’t even run GLM 4.7 reliably.
The irony? GLM-5 is “open-source” in name, but inaccessible in practice for 99% of developers. You need enterprise-grade hardware or you’re using the API anyway—which brings us back to the pricing war.
The Quota Consumption Crisis: Opus 4.6’s Achilles’ Heel
This is where Opus 4.6 stumbles. Developers are reporting 5x higher token consumption compared to Opus 4.5, despite identical pricing per token. The culprit: Agent Teams, a new feature that spawns parallel sub-agents for complex tasks.
One Reddit user put it bluntly: “My $50 credit lasted for a single complex task. With Opus 4.5, that would’ve covered 3-4 days of work.”
Anthropic’s advice? Lower the “effort” setting to Medium or Low, and only use High when truly stuck. That’s a band-aid. The underlying issue is Opus 4.6’s architecture—it’s optimized for quality over efficiency. Every query triggers deep reasoning chains, repo exploration, and safety checks. For enterprise users billing by the seat, that’s fine. For indie developers on tight budgets? It’s a deal-breaker.
GLM-5 doesn’t have this problem. It’s verbose, sure, but not $50-per-task verbose.
What This Means For You
If you’re building production agents:
Choose GLM-5 if you need cost-effective agentic coding at scale. The 77.8% SWE-Bench score is production-grade, and $1/1M input tokens means you can run thousands of agent loops without burning through budgets.
Choose Opus 4.6 if you need bulletproof reliability for knowledge-intensive tasks. The 1M context window and 144 Elo lead on GDPval-AA make it unbeatable for complex enterprise workflows.
If you’re experimenting locally:
GLM-5 is theoretically open-source, but unless you have 256GB+ RAM, you’re using the API anyway. Check Hugging Face for quantized versions or use platforms like Novita AI for GPU access.
Opus 4.6 doesn’t run locally. You’re stuck with claude.ai, the API, or cloud platforms like AWS Bedrock and Google Vertex AI.
If you’re budget-conscious:
– GLM-5 wins by default. At $1/1M input vs $5/1M, you’d need Opus 4.6 to be 5x better to justify the cost. It’s not. It’s roughly 1.2x better on coding benchmarks.
The Bottom Line
Opus 4.6 is the objectively superior model. But GLM-5 is the better deal.
Anthropic built a Lamborghini. Zhipu AI built a Tesla Model 3. Both will get you to the finish line, but only one lets you afford the gas to get there.
The real question isn’t “Which one is smarter?” It’s “How much are you willing to pay for that extra 3% on SWE-Bench?”
Because at current pricing, GLM-5’s value proposition is undeniable. And if China keeps shipping production-ready models at 80% discounts, Anthropic’s monetization strategy is about to face a stress test.
FAQ
Is GLM-5 really open-source?
Yes and no. The model weights are MIT-licensed on Hugging Face, but running 744B parameters locally requires GPU clusters or 256GB+ unified memory. Most developers will use the API, which costs $1/1M input tokens—still 5x cheaper than Opus 4.6.
Does Opus 4.6’s 1M context window actually work?
Yes. Anthropic achieved a 76% score on MRCR v2, a long-context retrieval benchmark. That’s usable context, not just theoretical capacity. GPT-5.2 Pro can’t match this.
Why is Opus 4.6 burning through quotas so fast?
Agent Teams. The feature spawns parallel sub-agents, each burning tokens independently. Developers report 5x higher consumption vs Opus 4.5. Workaround: Lower the effort setting to Medium or stick with Opus 4.5 for routine tasks.
Can I run GLM-5 on a Mac M3 Max?
Not reliably. Reddit users with 128GB M3 Ultra machines report struggling with GLM 4.7 (358B params). GLM-5 at 744B? Forget it. Use the API or cloud inference via vLLM or SGLang.
Is GLM-5 as good as Opus 4.5?
Close. Zhipu AI’s official blog says GLM-5’s “real-world programming experience approaches Claude Opus 4.5.” That’s marketing speak, but the 77.8% SWE-Bench score backs it up. Opus 4.6 is a step above, but Opus 4.5? GLM-5 is competitive.
Which one should I use for coding agents?
If you’re running thousands of agent loops: GLM-5 (price). If you need rock-solid reliability for mission-critical tasks: Opus 4.6 (quality). If you’re experimenting: GLM-5 (lower risk).