Remember that mysterious “Pony Alpha” model that appeared on OpenRouter back on February 6th? The one crushing coding benchmarks while everyone speculated about its origins? Well, the cat’s out of the bag.
It’s GLM-5. And Zhipu AI just made it official.
On February 11, 2026, Zhipu AI (Z.ai) dropped GLM-5—a 744 billion parameter monster trained entirely on Huawei Ascend 910C chips. This isn’t just another Chinese AI model. It’s a geopolitical statement wrapped in a MoE architecture, and it’s gunning for Claude Opus 4.5’s throne in software engineering.
The Pony Alpha Connection: Why the Codename Was Perfect
Let’s rewind a week. On February 6, a model called “Pony Alpha” suddenly appeared on OpenRouter with no attribution, offering 200,000-token context and free API access. The performance was wild—developers on r/LocalLLaMA reported coding reliability rivaling GPT-4o but with better agentic workflows.
When prompted indirectly, Pony Alpha identified itself as a GLM-series model. The tokenizer behavior matched GLM-4. The timing? Right before Chinese New Year. And 2026 is the Year of the Horse in the Chinese zodiac.
Zhipu wasn’t hiding. They were marketing.
The “Pony” codename was a soft launch—a way to gather real-world interaction data before the official release. Smart play. By the time they announced GLM-5 yesterday, developers had already battle-tested it for five days.
The Numbers: Why GLM-5 is Performance-Dense

Here’s where it gets interesting. GLM-5 is a Mixture of Experts (MoE) model with:
- 744 billion total parameters (up from 355B in GLM-4.5)
- 40 billion active parameters per inference (vs. 32B in GLM-4.5)
- 256 total experts, activating 8 per token (5.9% sparsity rate)
- 28.5 trillion tokens of pre-training data (vs. 23T in GLM-4.5)
- 200,000-token context window with DeepSeek Sparse Attention (DSA)
That last part is critical. GLM-5 borrows DeepSeek’s sparse attention mechanism, which dramatically cuts inference costs on long-context tasks without sacrificing recall. This is the same tech that made DeepSeek R1 viable for agentic workflows.
Benchmark Reality Check
Let’s talk performance. According to Z.ai’s technical report:
| Benchmark | GLM-5 Score | Context |
|---|---|---|
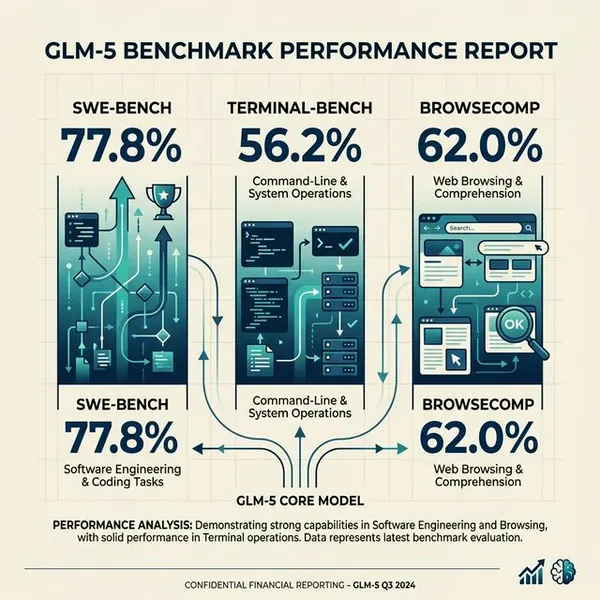
| SWE-bench Verified | 77.8% | Matches Claude Opus 4.5 |
| SWE-bench Multilingual | 73.3% | Leading open-weight model |
| Terminal-Bench 2.0 | 56.2 | Beats Gemini 3.0 Pro overall |
| BrowseComp | 62.0 (75.9 with context mgmt) | Best open-weight agentic model |
| AIME 2026 I | 92.7% | Top-tier mathematical reasoning |
| GPQA-Diamond | 86.0% | Graduate-level science questions |
That SWE-bench Verified score is eye-opening. For context, Claude Opus 4.6 hit 77.2% on the same benchmark. GLM-5 is claiming parity with a frontier closed-source model—while being fully open-weight under an MIT License.
I’ve been tracking coding benchmarks for months. If this holds up in production, it’s the first time an open-source model has matched the “big three” (OpenAI, Anthropic, Google) on real code generation tasks.
The Huawei Ascend Angle: Why This is About More Than AI
Here’s what everyone’s missing: GLM-5 was trained entirely on Huawei Ascend 910C chips using the MindSpore framework.
Not a single NVIDIA GPU.
This is China’s answer to the U.S. semiconductor export restrictions. Beijing has been pouring money into domestic chip manufacturing, and GLM-5 is proof it’s working. Huawei’s Ascend chips are no longer vaporware—they’re training state-of-the-art AI models.
From a geopolitical lens, this is huge. If Chinese AI labs can train frontier models without American chips, the entire premise of the export controls collapses. The U.S. bet was that cutting off GPU access would slow China’s AI progress. GLM-5 suggests otherwise.
And Zhipu isn’t alone. China Mobile recently chose Ascend chips over NVIDIA H100s for a massive AI infrastructure project. The ecosystem is scaling.
Pricing: How GLM-5 Competes on Economics
Here’s the money part. According to Z.ai’s pricing page, GLM-5 costs:
- $1.00 per 1M input tokens
- $3.20 per 1M output tokens
For comparison:
Claude Opus 4.6: $5 / $25 per 1M
GPT-5.2: $1.75 / $14 per 1M
Gemini 3.0 Pro: $2 / $12.00 per 1M
But here’s the catch: GLM-5 is also open-source. You can download the weights from Hugging Face or ModelScope and run it locally (if you have 128GB+ RAM). The API pricing is just a convenience layer.
This is the MiniMax M2.1 playbook: undercut on price, open-source the weights, and let the community do your QA.
What the Reddit Engineers Are Saying
I scanned r/LocalLLaMA and r/MachineLearning. The sentiment is cautiously bullish.
Top comment from u/gpu_engineer_anon:
“Tested GLM-5 on SWE-bench tasks. Comparable to Sonnet 4. Not as careful as Claude but way faster for iteration loops.”
Another notable take:
“The hallucination rate on AA-Omniscience is the lowest I’ve seen. GLM-5 (Reasoning) is scoring 50 on the Intelligence Index—new open weights leader.”
The consensus: GLM-5 is production-ready for coding agents, especially if you’re running agentic loops where speed matters more than perfection. It won’t replace Claude for high-stakes enterprise work, but for developer tooling? It’s a contender.
The Bottom Line: China’s AI Labs Are No Longer “Catching Up”
GLM-5 isn’t a “DeepSeek clone” or a “cheap alternative.” It’s a signal that Chinese AI labs have crossed the threshold. They’re not playing catch-up anymore—they’re innovating in parallel.
The Pony Alpha teaser was genius marketing. The Huawei Ascend training was a geopolitical flex. And the MIT License open-sourcing? That’s a long-term ecosystem play.
If you’re a developer building AI agents, you now have a Claude-tier coding model that’s:
1. 15x cheaper than Opus
2. Open-weight (run it locally)
3. Trained on non-NVIDIA hardware (supply chain diversification)
The question isn’t whether GLM-5 is good. It’s whether the West is ready to compete with this pricing and openness.
Because the AI game just changed.
FAQ
Is GLM-5 really as good as Claude Opus 4.5 for coding?
On SWE-bench Verified, yes—77.8% vs 77.2%. But benchmarks are one thing; production reliability is another. Early reports suggest GLM-5 is faster but less “careful” than Claude, making it better for rapid iteration than mission-critical deployments. Think of it as the speed runner vs. Claude’s marathon runner.
Can I run GLM-5 locally on my Mac?
Technically yes, but you need 128GB+ of RAM for the full model. The 40B active parameters + MoE architecture means memory requirements are high. If you have a Mac Studio with 192GB unified memory, you’ll be fine. Otherwise, stick to the API at $1/1M tokens.
Why did Zhipu AI use the “Pony Alpha” codename?
Two reasons: (1) 2026 is the Year of the Horse in the Chinese zodiac, and “pony” is a playful nod to that. (2) It was a stealth beta test. By releasing it anonymously on OpenRouter, Zhipu gathered real-world usage data without the pressure of an “official” launch. Smart pre-launch strategy.
How does DeepSeek Sparse Attention (DSA) reduce costs?
Traditional attention mechanisms scale quadratically with context length—processing a 200k token context is insanely expensive. DSA uses a sparse pattern that only attends to the most relevant tokens, cutting compute costs by ~60% while maintaining >95% recall accuracy. It’s the same tech that made DeepSeek R1 viable for long-context reasoning.
Will this hurt NVIDIA’s business?
Not immediately, but long-term? Yes. If Chinese AI labs can train frontier models on Huawei Ascend chips, it proves the export controls aren’t working as intended. It also means U.S. cloud providers (AWS, Azure, GCP) lose leverage—Chinese companies won’t need to rent NVIDIA H100s from American data centers. The moat is narrowing.