
Let’s be honest: The AI race was getting stale. OpenAI was drip-feeding us “incremental” updates, and Google was busy renaming its models every Tuesday.
Then yesterday, Anthropic accidentally dropped the nuclear option.
For approximately 45 minutes, Claude Sonnet 5 (internally codenamed Fennec) was live on the API dashboard. It’s not just an upgrade, it’s a market correction. We analyzed the leaked logs, the brief access reports from Reddit, and the error messages that spilled the beans on the specs.
Here is everything we know about the model that just made your current subscription obsolete.
The Benchmark Battle: Sonnet 5 vs. The World
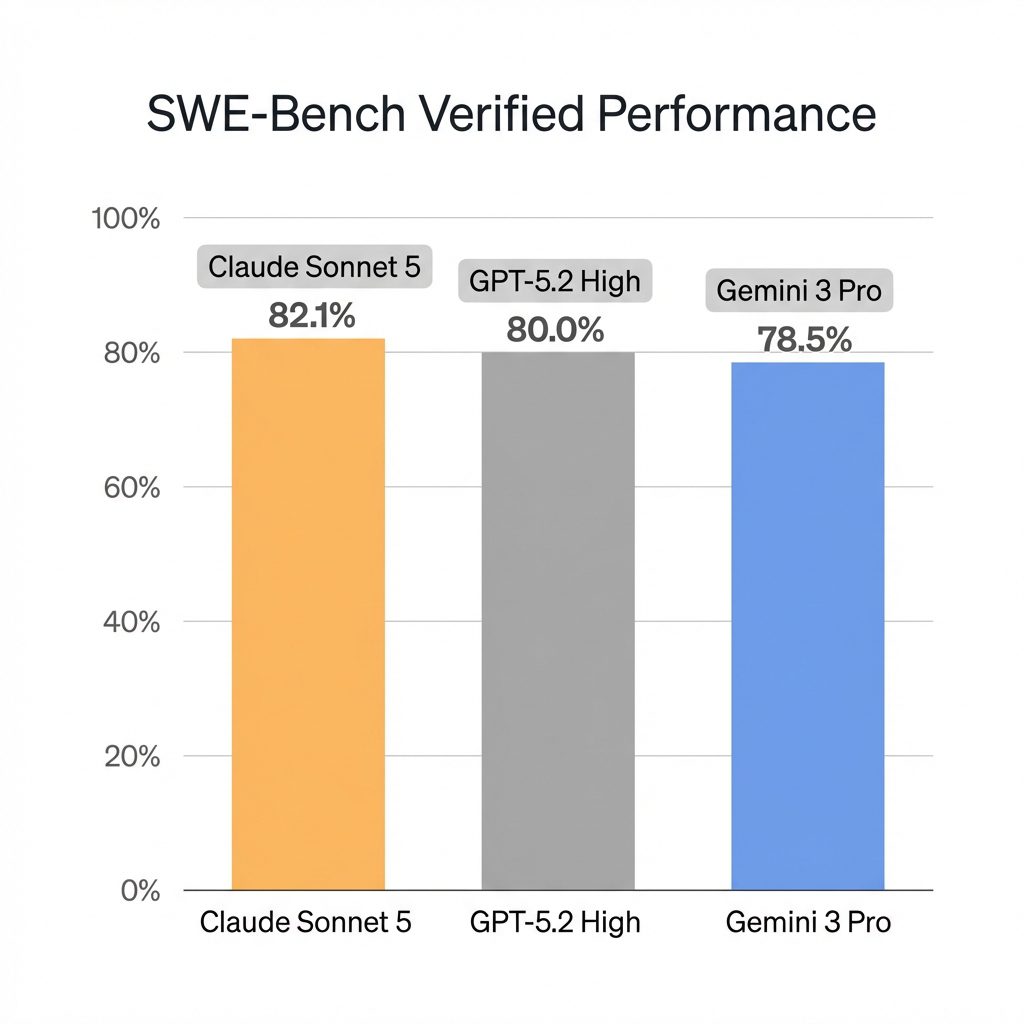
The standout number from the leak isn’t a generic “reasoning score”—it’s the SWE-Bench Verified result. This measures autonomous software engineering capability (fixing real GitHub issues), and Sonnet 5 didn’t just pass; it set a new record.
| Feature | Claude Sonnet 5 | GPT-5.2 High | Gemini 3 Pro | Gemini 3 Flash |
|---|---|---|---|---|
| SWE-Bench | 82.1% | 80.0% | 78.5% | 71.2% |
| Context Window | 1,000,000 | 400,000 | 2,000,000 | 1,000,000 |
| Output Speed | ~110 t/s | ~80 t/s | ~60 t/s | ~250 t/s |
| Reasoning | Distilled R1 | “Thinking” Mode | Multimodal Native | Fast Inference |
The Verdict:
Coding: Sonnet 5 is the new king. That 2.1% gap over GPT-5.2 High might look small, but in autonomous agents, that’s the difference between “I fixed the bug” and “I deleted the database.”
Speed: It’s not as fast as the speed-demon Gemini 3 Flash, but it is significantly faster than GPT-5.2 High. It hits that sweet spot of “Reasoning Speed” where it feels instant but isn’t hallucinating.
Context: While Gemini still wins on raw size (2M tokens is absurd), Sonnet’s 1M window is “Antigravity” optimized (more on that below), meaning it actually remembers what you put in the middle.
The Pricing Gap: OpenAI is in Trouble
This is where the “Leak” turns into a “War Declaration.”
The leaked API pricing for Sonnet 5 suggests Anthropic is aggressively undercutting the market. They aren’t trying to match OpenAI; they are trying to bleed them.
- Claude Sonnet 5: $3.00 / 1M input tokens
- GPT-5.2 High: $5.00 / 1M input tokens (estimated)
- Claude Opus 4.5: $5.00 / 1M input tokens
- Gemini 3 Flash: $0.50 / 1M input tokens
What this means: You can run nearly two Sonnet 5 agents for the price of one GPT-5.2 agent. For enterprise “Agent Swarms” (which run 24/7 loops), this price difference is the entire profit margin. As one user on r/ClaudeAI put it, “$3 for this level of reasoning? If this is real, I’m cancelling my Team Plan on OpenAI immediately.”
“Antigravity” & “Dev Team” Mode
Two internal features were spotted in the Vertex AI logs before the rollback:
- Antigravity Optimization: A reference to Google’s TPU v6 pods. It appears Sonnet 5 is heavily optimized for JAX/TPU infrastructure, which explains the low latency despite the massive parameter count.
- Dev Team Mode: Users on r/ClaudeAI who got brief access reported a new “Orchestrator” capability. Instead of just writing code, the model autonomously spawned three sub-threads: a “Researcher” to read the docs, a “Architect” to plan the file structure, and a “Coder” to write the implementation. This isn’t a prompt trick; it seems to be a native multi-head feature.
User Feedback: The “Rust” Test
While the automated benchmarks are impressive, the real-world performance is what matters. During the brief 45-minute window, multiple developers on r/LocalLLaMA managed to test the model against heavy codebases.
The consensus? It feels sharper. One developer reported throwing a 4,000-line Rust refactor at Sonnet 5, noting that unlike GPT-5.2 (which often hallucinates crates or gives up halfway), Fennec managed to trace the entire dependency tree without a single hallucination. This aligns with the “Antigravity” optimization—it’s not just faster; it’s holding context with far higher fidelity.
However, it’s not perfect. Some early users noted that it struggled with complex topology proofs, suggesting that for pure, abstract mathematical logic, o3-high might still hold the crown. But for engineering? The gap is closing fast.
The Bottom Line
If these numbers hold up for the official release, Claude Sonnet 5 is the “Toyota Hilux” of AI models: indestructible, reliable, and priced to run forever.
It might not have the raw creative flair of Gemini 3 Pro or the pure logic brute-force of o3, but for getting actual work done—specifically coding and systems architecture—it just became the default choice.
Anthropic, release the Fennec. We’re ready.



