

A new week, a new model drop. But this isn’t just another incremental update. Introducing Claude Sonnet 4.6.
This is going to be Anthropic’s workhorse. And it got a major quality bump from Sonnet 4.5. We’re talking about a model that is now better at coding, significantly better at tool use, and comes with a one million token context window. Best of all? They made it the default model on the free plan.
This is incredible. The pricing remains the same as Sonnet 4.5—starting at $3 per million input tokens and $15 per million output tokens. But for that same price, you are getting a model that is practically a different species when it comes to “real work.”
The line between Sonnet and Claude Opus 4.6 is blurring. And if you’re building agents, this update changes everything.
The “Real World” Task Model
Anthropic is positioning Sonnet 4.6 as a “real-world task model.” What does that mean? It means it’s so capable at tool use and agentic ability that it can create PowerPoints, manipulate Excel spreadsheets, and handle complex workflows within Claude Cowork.
It’s fast. It’s smart. And it’s incredibly good at computer use.
The OS World Jump
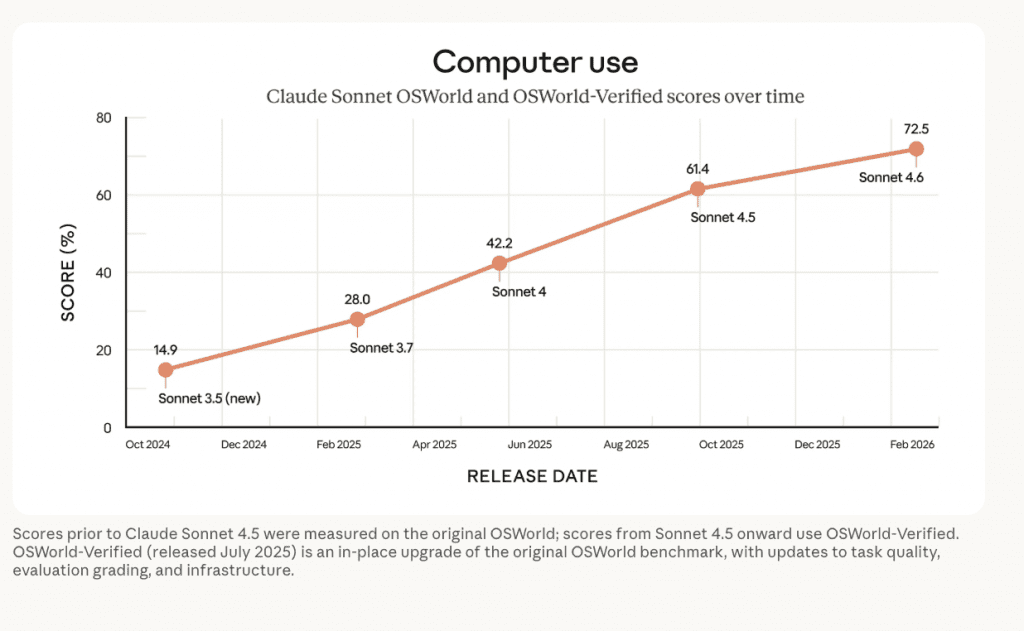
Look at the numbers. In OS World (a benchmark where AI is given a computer environment and instructed to complete practical tasks), the jump is staggering.
| Model | OS World Score |
|---|---|
| Sonnet 4.5 | 61.4% |
| Sonnet 4.6 | 72.5% |
That is a massive leap in capability. And the way it works is fascinating: there are no special APIs or purpose-built connectors. The model sees the computer and interacts with it much like a person would—clicking a virtual mouse, typing on a virtual keyboard. It looks, decides, and executes.
Benchmark Breakdown: The Tool Use Explosion
It is benchmark time. Let’s look at where Sonnet 4.6 really shines.
Comparing Sonnet 4.6 to Sonnet 4.5, Opus 4.6, Gemini 3 Pro, and GPT-5.2:
- Agentic Terminal Coding: 51% (4.5) → 59% (4.6)
- Agentic Coding: 77% (4.5) → 79% (4.6)
- Agentic Computer Use: 61% (4.5) → 72% (4.6)
- Agentic Tool Use: 86% (4.5) → 91% (4.6)
But here is the most important number: General Tool Use.
It jumped from 43.8% to 61.3%.
This is probably the most critical upgrade for real-world use cases. When a model can effectively use tools, query databases, and interact with MCP servers, it transitions from a chatbot to an engine.
Humanity’s Last Exam
The improvements aren’t just in tool use. On “Humanity’s Last Exam,” scores jumped from 17.7% to 33% (without tools) and 33.6% to 49% (with tools).
Interestingly, the “without tools” score nearly doubled. With tools, it was a massive jump too, though I might have expected even more given the tool use upgrade. But 49% is nothing to sneeze at.
Financial Analysis Dominance
In Financial Analysis, Sonnet 4.6 moved from 54% to 63%. It is now #1 across the board for Agentic Financial Analysis—beating Opus 4.6, Gemini 3 Pro, and GPT-5.2.
This model is aimed squarely at knowledge workers. On the “Office Task” benchmark, it scored 1633, beating Opus 4.6. This confirms what Anthropic optimized for: practical, high-value knowledge work.
The Vending Machine Test: Adaptive Reasoning
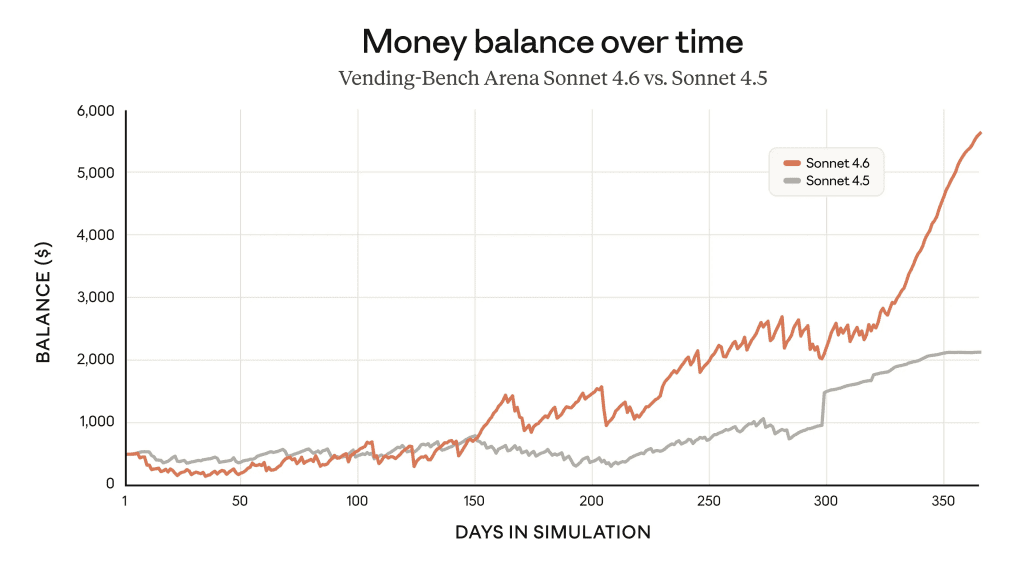
I love Vending Bench. If you aren’t familiar, it’s a benchmark where a model manages a vending machine—stocking inventory, analyzing purchases, reordering—to optimize profit over time.
- Sonnet 4.5: ~$2,000 profit after 350 days.
- Sonnet 4.6: ~$5,500 profit.
The chart shows Sonnet 4.6 investing in capacity early, then pivoting to profitability in the final stretch. It figured it out. This success is likely due to Adaptive Reasoning, which allows the model to scale “thinking tokens” up or down as needed.
Safety and The “Fine Line”
Of course, it’s not Anthropic if we aren’t talking safety.
Sonnet 4.6 is deployed under AI Safety Level 3 (ASL-3).
* ASL-2: Early signs of dangerous capabilities (e.g., bio-weapon instructions).
* ASL-3: Substantially increases risk of catastrophic misuse compared to non-AI baselines.
Anthropic states that Sonnet 4.6 does not cross the AI R&D4 (automating an entry-level researcher) or CBRN4 (chemical/bio/nuclear weapons) thresholds.
But here is the crazy part from the model card:
“Confidently ruling out these thresholds is becoming increasingly difficult.”
The model is approaching high levels of capability where our ability to measure safety is struggling to keep up.
To combat misuse, they’ve improved resistance to prompt injection. If you use these models for sensitive data (and if you use OpenClaw like I do, you know the risks), this is vital. Sonnet 4.6 is a major improvement here, performing similarly to Opus 4.6 in safety evaluations.
What This Means For You
If you are a knowledge worker, entrepreneur, or developer, this is your new default.
GDP Val (a benchmark by Artificial Analysis measuring ability to drive GDP) rates Sonnet 4.6 higher than Opus 4.6. It spans 44 occupations and tasks like documents, slides, diagrams, and spreadsheets.
Practical Implications
- Switch your “Worker” Agents: If you have agents running background tasks (coding, data entry, analysis), move them to Sonnet 4.6 immediately. The cost is the same, but the reliability (especially with tools) is vastly higher.
- Use it for Office Tasks: The Excel and PowerPoint integrations are not gimmicks. The 1633 Office Task score proves it can handle the boring, messy reality of corporate data formats.
- Trust it (a bit more) with Tools: The jump to 61.3% in tool use means fewer hallucinations when calling APIs and fewer “I can’t do that” errors.
The Bottom Line
Sonnet 4.6 is the Agentic Workhorse.
It challenges the need for Claude Opus 4.6 in many scenarios. It’s fast, it has a massive context window, and it dominates in financial and office tasks.
A lot of people are speculating online that this might have been intended as Sonnet 5 or even Opus 5, but was released as 4.6. Whatever the internal naming, the result is clear: Knowledge work just got a massive upgrade.
I’ll be testing this model like crazy over the next few days. If you’re building with it, let me know what you find.
FAQ
Is Sonnet 4.6 more expensive than 4.5?
No. The pricing remains exactly the same: $3 per million input tokens and $15 per million output tokens.
Can Sonnet 4.6 use a computer?
Yes. It achieves a 72.5% score on OS World and interacts with computer interfaces visually (clicking, typing) without special APIs.
What is the context window for Sonnet 4.6?
It comes with a 1 million token context window, making it suitable for analyzing massive documents or codebases.



