

NVIDIA owns 95% of the AI accelerator market. But that doesn’t mean they’re the best at everything.
Two challengers-Cerebras and Groq-are rewriting the rules of AI hardware. Not by making “better GPUs,” but by fundamentally rethinking how compute should work.
The claim: Cerebras is 21x faster than NVIDIA’s Blackwell B200 for LLM inference. Groq delivers 1,600 tokens per second when NVIDIA struggles to hit 100.
But here’s the question: If these chips are so much faster, why isn’t everyone using them?
Let me show you exactly what’s happening under the hood-and why the “fastest chip” rarely wins.
The Bottleneck: It’s Not Compute, It’s Memory
Here’s the dirty secret of AI inference: Your chip is idle 90% of the time.Not because it’s slow. Because it’s waiting for data.
The Memory Wall Problem
LLM inference is memory-bound, not compute-bound. Here’s the workflow for generating a single token:
- Load model weights from memory (175B parameters for GPT-3 = 350GB of data) – this is where transformer architecture comes into play
- Compute matrix multiplication (fast-GPUs excel here)
- Write result back to memory
- Repeat for next token
The bottleneck? Step 1 and 3. Moving data.
NVIDIA H100 specs:
- Compute: 1,979 TFLOPS (FP8)
- Memory bandwidth: 3 TB/s (HBM3)
- Problem: To use that 1,979 TFLOPS, you need to feed it data at 3 TB/s. For large models, that’s the limiting factor.
Think of it like a Formula 1 car (GPU) stuck in city traffic (memory bandwidth). The engine can do 200 mph, but the road only allows 30.
This is the problem Cerebras and Groq are solving-just in completely different ways.
Cerebras: Build the Entire City on a Single Chip
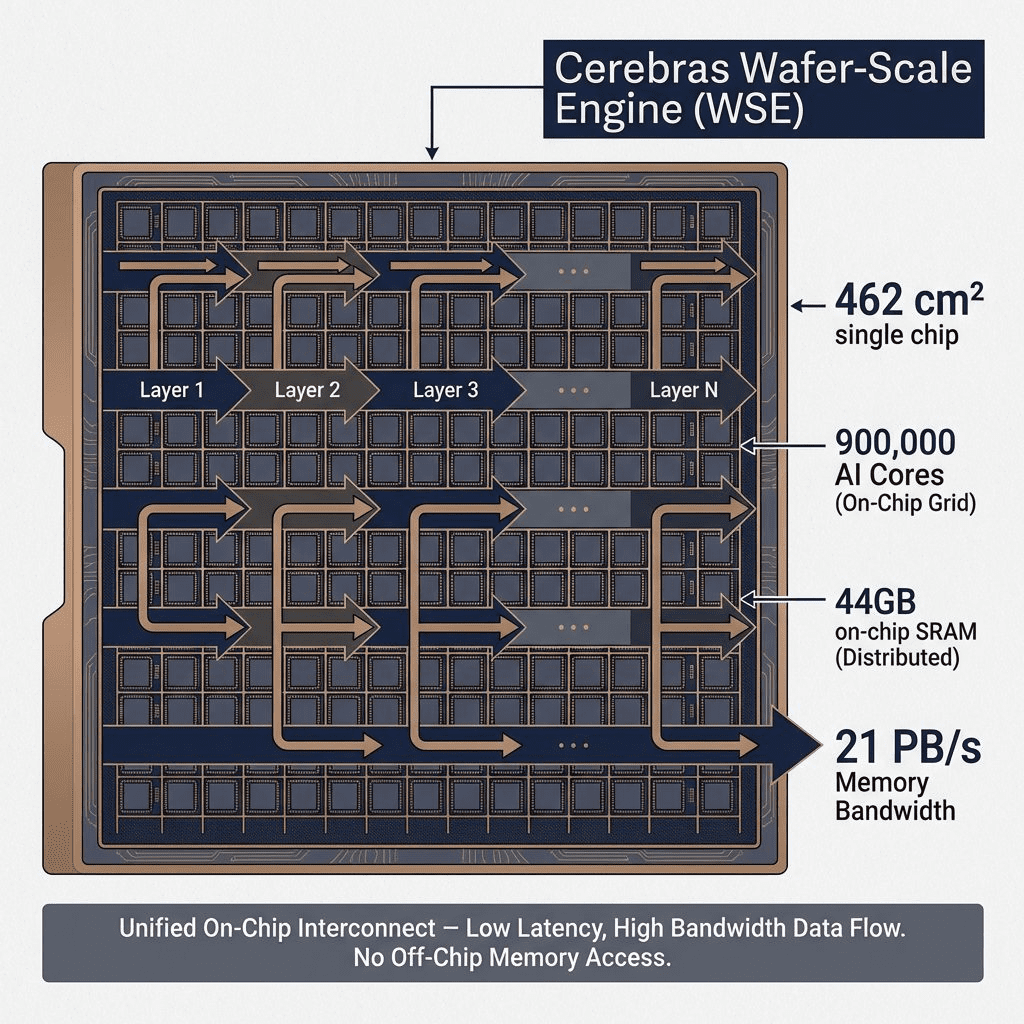
Cerebras’ solution? Don’t move data off-chip at all.
Wafer-Scale Engine Architecture
Traditional chips are built on a ~1cm² silicon die. Cerebras builds on the entire wafer-462 cm²
Cerebras WSE-3 specs:
- 900,000 AI cores (vs. ~16,000 CUDA cores in an H100)
- 44GB of on-chip SRAM (vs. 80GB HBM3 off-chip in H100)
- 21 petabytes/second memory bandwidth (vs. 0.003 PB/s for H100)
That’s 7,000x higher bandwidth.
How It Works: Layer-by-Layer Execution
Instead of loading the entire model into memory, Cerebras dedicates different regions of the wafer to different neural network layers.
Process:
- Input data enters from the left side of the wafer
- Flows through Layer 1 cores → Layer 2 cores → Layer N cores
- Output emerges from the right side
- All data stays on-chip
The key insight: By keeping everything on one massive chip, you eliminate:
- PCIe bus transfers
- GPU-to-GPU communication (NVLink overhead)
- HBM latency
Real-world results:
- Llama 3.1 8B: 1,800 tokens/s (vs. 242 tokens/s on H100)
- Llama 4 Maverick 400B: 2,522 tokens/s (vs. 1,038 tokens/s on Blackwell)
- Time-to-first-token: 240ms (vs. 430ms for Google Vertex AI)
The Catch: Size and Cost
Cerebras systems are massive:
- Single CS-3 server: Refrigerator-sized
- Power consumption: ~23 kW per system
- Cost: $2-3 million per unit (estimated)
You can’t just “buy a Cerebras chip.” You buy an entire Wafer-Scale Cluster with integrated cooling.
Groq: Make Execution Perfectly Predictable
Groq took a different approach: Eliminate variance entirely.
Deterministic Execution Architecture
GPUs are reactive. They have:
- Branch predictors (guess which code path to take)
- Cache hierarchies (unpredictable hit/miss)
- Arbiters (resolve resource conflicts)
- Reordering buffers (optimize on-the-fly)
All of this introduces non-determinism. Sometimes inference takes 50ms. Sometimes 120ms. You can’t predict.
Groq eliminates ALL of this.
How the LPU Works
The Language Processing Unit (LPU) is a compiler-scheduled chip.
Key innovation: A sophisticated compiler calculates, ahead of time, exactly:
- When every instruction will execute (down to the clock cycle)
- Where every piece of data will be
- Which functional unit will process it
No branch prediction. No cache. No arbitration. Just a predetermined assembly line.
Tensor Streaming Architecture
Think of Groq’s chip as a factory assembly line with “data conveyor belts”:
- Data enters the chip
- Compiler has pre-scheduled which functional unit processes it at which nanosecond
- Data streams through SIMD units in perfect synchronization
- Output emerges with deterministic latency
Groq performance:
- 1-2ms latency per token (vs. 8-10ms for NVIDIA)
- 300-1,600 tokens/second depending on model size
- No batch size dependency (NVIDIA needs large batches for efficiency)
Example: Llama 3 70B
- Groq: 300 tokens/s, consistent
- NVIDIA H100: 60-100 tokens/s, varies with batch size
The Catch: Limited Scope
Groq’s deterministic architecture only works well for:
- Inference (not training)
- Sequential models (LLMs, not diffusion models)
- Small-to-medium batch sizes
For training a 100B model from scratch? NVIDIA still wins because their architecture handles dynamic, unpredictable workloads better.
NPUs: The Third Category
While Cerebras and Groq chase inference speed, NPUs (Neural Processing Units) target efficiency.
What Makes NPUs Different
NPUs are specialized for:
- Low-power AI inference (smartphones, laptops)
- On-device model execution
- Privacy (no cloud round-trip)
They sacrifice raw performance for energy efficiency.
Apple M4 Neural Engine
- 38 TOPS (trillion operations per second)
- 16 cores dedicated to ML
- 2x faster than M3’s Neural Engine
Built on TSMC’s 3nm process, the M4 can run:
- Image recognition and computer vision
- Real-time video effects
- On-device LLM inference (up to ~7B parameters)
Use case: Running Llama 3.1 8B locally for Siri-like experiences without cloud latency. Learn more about Apple’s Neural Engine specifications.
Qualcomm Snapdragon Hexagon NPU
- 45 TOPS (Snapdragon X Elite)
- 4nm process
- Powers “Copilot+ PC” features
Trade-off: 45 TOPS sounds impressive, but real-world LLM inference shows Apple M4 often outperforms (48 tokens/s vs. 24 tokens/s on some benchmarks) due to better memory architecture.
NPU vs. GPU
| Metric | NPU | GPU |
|---|---|---|
| Power | 5-15W | 300-700W |
| Use case | On-device inference | Training + heavy inference |
| Latency | 10-50ms | 1-10ms (with batching) |
| Flexibility | Limited (optimized for specific ops) | High (programmable) |
Bottom line: NPUs are for local AI on edge devices. Not for training Claude or serving ChatGPT.
The Real Comparison: Memory Bandwidth is King
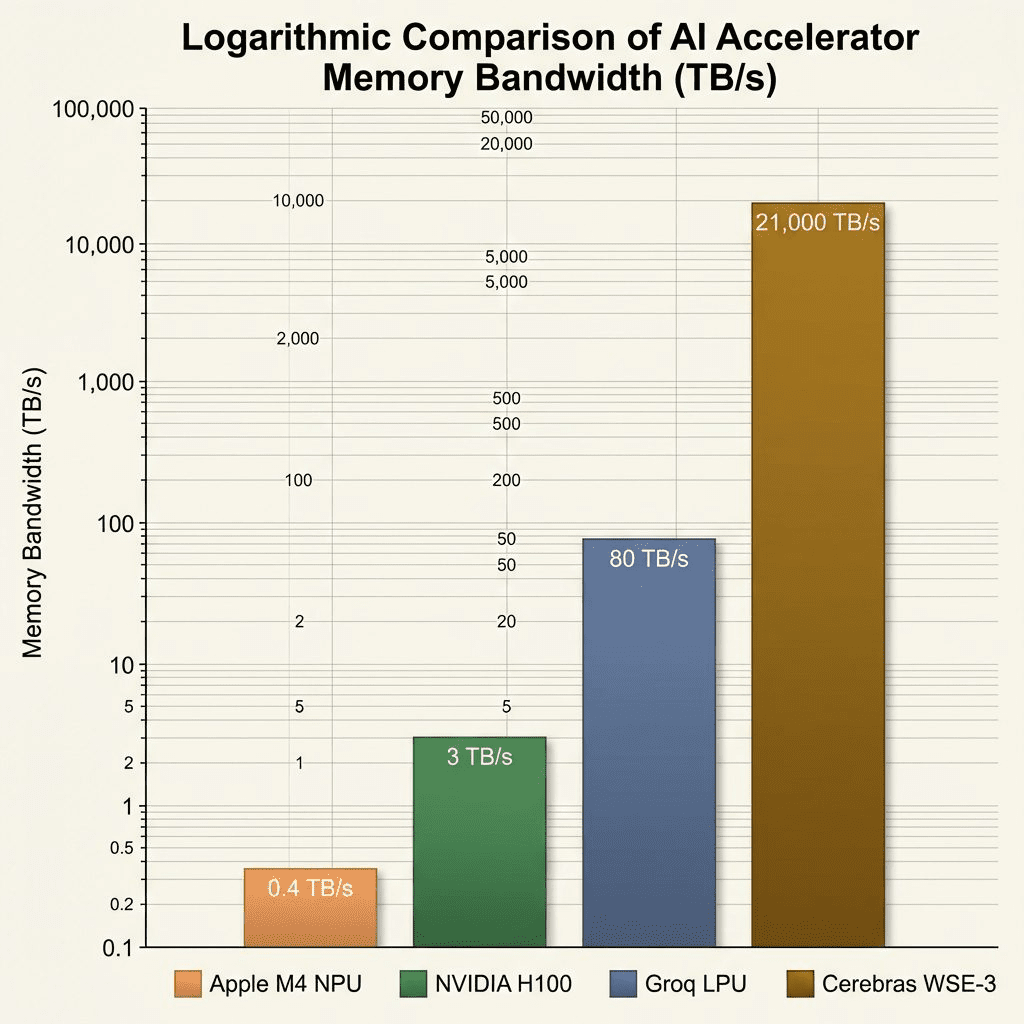
Here’s the hierarchy that matters for LLM inference:
Memory Bandwidth Showdown
| System | Memory Bandwidth | Inference Speed (Llama 3 70B) |
|---|---|---|
| Cerebras WSE-3 | 21,000 TB/s | 1,800+ tokens/s |
| Groq LPU | ~80 TB/s (on-chip SRAM) | 300-500 tokens/s |
| NVIDIA H100 | 3 TB/s | 60-100 tokens/s |
| Apple M4 | 0.4 TB/s | ~15 tokens/s (8B model) |
The correlation is obvious: Higher bandwidth = faster inference.
But bandwidth isn’t free.
Why NVIDIA Still Dominates
If Cerebras is 21x faster, why does NVIDIA own 95% of the market?
1. Software Ecosystem
- CUDA: 15 years of developer investment
- TensorRT-LLM: Optimized inference library
- Triton Inference Server: Production-grade serving
Cerebras and Groq are catching up, but most ML frameworks assume CUDA by default.
2. Versatility
- NVIDIA GPUs handle: training, inference, rendering, scientific computing
- Cerebras: Only AI inference
- Groq: Only LLM inference
If you’re a research lab, you need GPUs for multiple workflows.
3. Cost-Per-Token Economics
Cerebras: Fast, but $2-3M upfront + high power costs. Best for hyperscalers with massive inference traffic.
Groq: Cheaper per-token than NVIDIA at scale, but limited availability and newer platform = risk.
NVIDIA: Expensive per-token, but everywhere. Every cloud provider offers H100 instances. Battle-tested.
4. Training vs. Deployment: Different Games Entirely
Here’s a critical distinction most people miss: Training and deployment are fundamentally different workloads.
Why Training Needs NVIDIA
Training characteristics:
- Backpropagation: Must compute gradients flowing backward through the network (dynamic, unpredictable memory access patterns)
- Gradient synchronization: In distributed training (8x H100 DGX), gradients from all GPUs must be averaged after each batch
- Hyperparameter experimentation: You’re constantly tweaking learning rates, batch sizes, architectures – need flexibility
- Data parallelism: Different GPUs process different batches simultaneously, requiring high-bandwidth interconnects (NVLink)
Why NVIDIA wins here:
- NVLink 4: 900 GB/s per GPU lets 8 H100s share 640GB unified memory (NVIDIA H100 specs)
- CUDA flexibility: Can handle any neural network architecture (CNNs, Transformers, diffusion models)
- Mixed precision training: FP8/FP16 modes optimized for training stability
- Mature tools: PyTorch and JAX assume NVIDIA by default
Cerebras limitation: Layer-by-layer execution doesn’t work for backpropagation. Gradients need to flow backward through all layers simultaneously, not sequentially. Read more about Cerebras WSE-3 architecture.
Groq limitation: Deterministic scheduling breaks when training introduces stochastic gradient descent, dropout, and dynamic batch sizes. See Groq LPU technical details.
Why Deployment Favors Cerebras/Groq
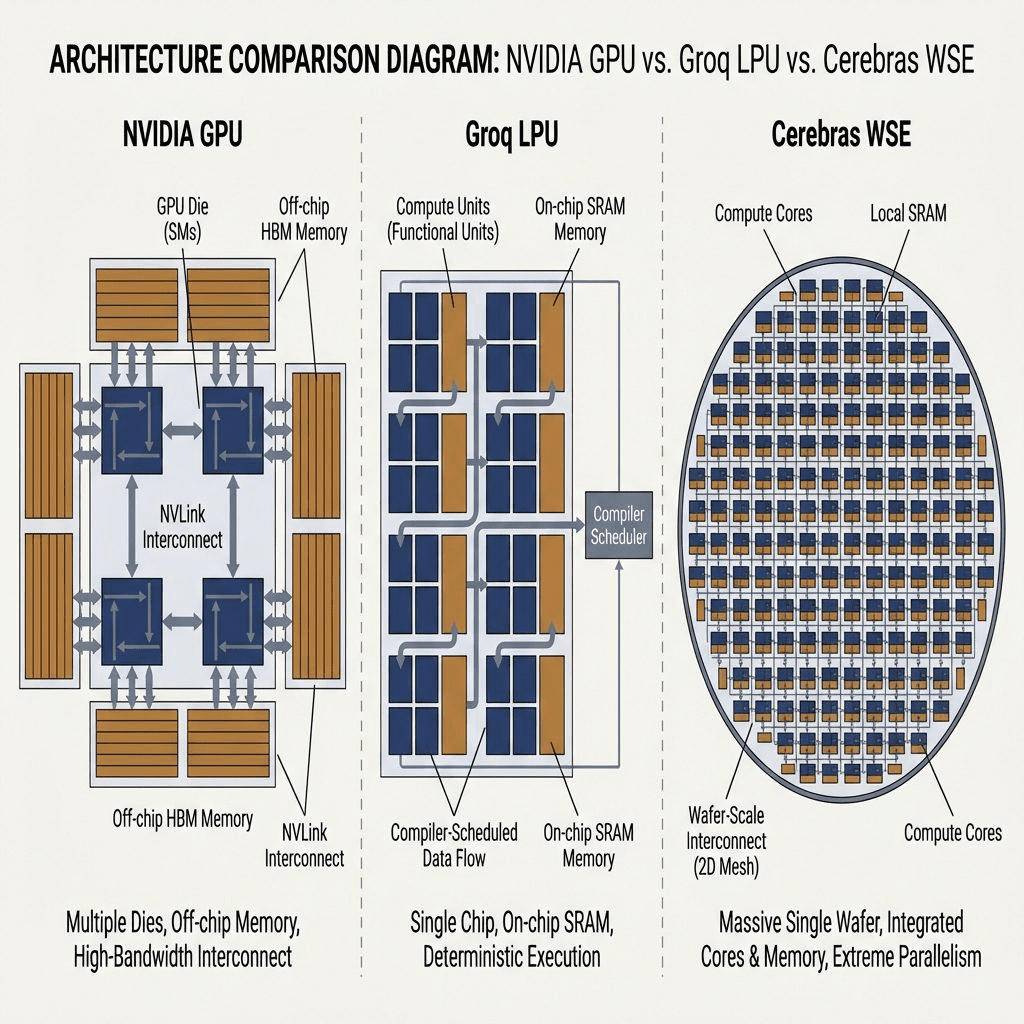
Deployment characteristics:
- Forward pass only: No backpropagation – just input → output
- Fixed architecture: Model is frozen; you’re not experimenting
- Predictable patterns: Same computation graph every time (perfect for Groq’s compiler)
- Latency-critical: Users expect sub-second responses
Why Cerebras/Groq win here:
- Cerebras: 21 PB/s bandwidth eliminates the memory bottleneck during forward passes
- Groq: Deterministic latency (1-2ms per token) beats NVIDIA’s variable 8-10ms
- Cost per token: At scale, specialized inference chips are cheaper than training GPUs
Real-world split:
- OpenAI: Trains GPT models on NVIDIA DGX clusters (H100/A100)
- OpenAI: Serves ChatGPT on… also NVIDIA (because ecosystem lock-in), but could use Groq/Cerebras
- Groq Cloud: Serves Llama models 5x faster than NVIDIA-based alternatives
The Future: Specialized Accelerators Win
Here’s the prediction: No single chip will dominate everything.
The New Hierarchy
Training: NVIDIA GPUs (or Google TPUs)
- Why: Dynamic workloads, need flexibility, CUDA ecosystem
High-volume inference (chatbots): Groq LPUs or Cerebras
- Why: Latency-sensitive, predictable workloads, cost-per-token matters
Edge AI (phones, laptops): NPUs
- Why: Power efficiency, privacy, local execution
Scientific computing / multimodal AI: NVIDIA GPUs
- Why: Versatility, mature software
What’s Coming Next
1. Hybrid architectures: NVIDIA’s next-gen Rubin (2026) will integrate NPU-like blocks into GPUs for inference acceleration.
2. Software-defined chips: Groq’s compiler-first approach may inspire NVIDIA to adopt more deterministic execution modes.
3. Wafer-scale goes mainstream: If Cerebras proves ROI at scale, we’ll see competitors (Samsung, TSMC) enter the wafer-scale market.
4. Open ecosystems: AMD is investing in ROCm (CUDA alternative). If software portability improves, hardware diversity increases.
The Bottom Line
- Cerebras is faster-if you have $3M and need to serve billions of tokens/month.
- Groq is lower-latency-if your workload is purely LLM inference.
- NVIDIA is safer-if you need versatility, ecosystem support, and proven scale.
- NPUs are smarter-if you want AI running locally on your device.
The winner depends on your workload.
But one thing is clear: The era of “GPUs for everything AI” is ending. We’re entering an age of specialization-where the right chip for the job depends on whether you’re training, inferring, or serving edge devices.
And that fragmentation? That’s healthy. Competition breeds innovation.
NVIDIA’s dominance forced Cerebras to build a wafer-scale monster. Groq had to rethink execution from scratch. Apple and Qualcomm are making on-device AI a reality.
The best part? We’re still in the first inning.
FAQ
Is Cerebras actually 21x faster than NVIDIA?
Yes-for specific LLM inference workloads (e.g., Llama 3 70B). The 21x speedup accounts for end-to-end latency (time-to-first-token + token generation). However, this advantage only applies to large models where memory bandwidth is the bottleneck. For training or smaller models, the gap narrows significantly.
Why doesn’t everyone use Groq if it’s so much faster?
Three reasons:
(1) Limited availability – Groq is still scaling production capacity.
(2) Software maturity – CUDA has 15 years of ecosystem investment, Groq’s toolchain is newer.
(3) Workload specificity – Groq only excels at LLM inference. If you also need training, computer vision, or scientific computing, NVIDIA is more versatile.
Can you train models on Cerebras or Groq?
Cerebras: Yes, but not efficiently for all model types. Their layer-by-layer architecture struggles with backpropagation parallelism. Works better for inference.
Groq: No. The deterministic architecture is designed for inference only. Training requires dynamic, unpredictable operations that Groq’s compiler-scheduled approach can’t handle.
Are NPUs just slower GPUs?
No. NPUs are specialized for AI inference at low power. They sacrifice raw TFLOPS for efficiency. A Qualcomm NPU at 45 TOPS uses 5-10W. An NVIDIA H100 at 1,979 TFLOPS uses 700W. Different design goals: edge devices vs. data centers.
Will NVIDIA lose its dominance?
Unlikely in the short term (3-5 years). NVIDIA’s CUDA ecosystem, software tools (TensorRT, Triton), and versatility create massive lock-in. However, long-term (10+ years), specialized accelerators (like Cerebras for inference, Groq for latency-critical apps) will capture specific niches, fragmenting the market. NVIDIA will remain dominant but shrink from 95% to maybe 60-70% market share.



