

KittenTTS is an open-source, 15-million parameter text-to-speech model under 25MB that runs locally on CPUs. Here is why the race to the edge matters more than cloudy heavyweights.
KittenTTS is an open-source, 15-million parameter text-to-speech model under 25MB that runs locally on CPUs. Here is why the race to the edge matters more than cloudy heavyweights.
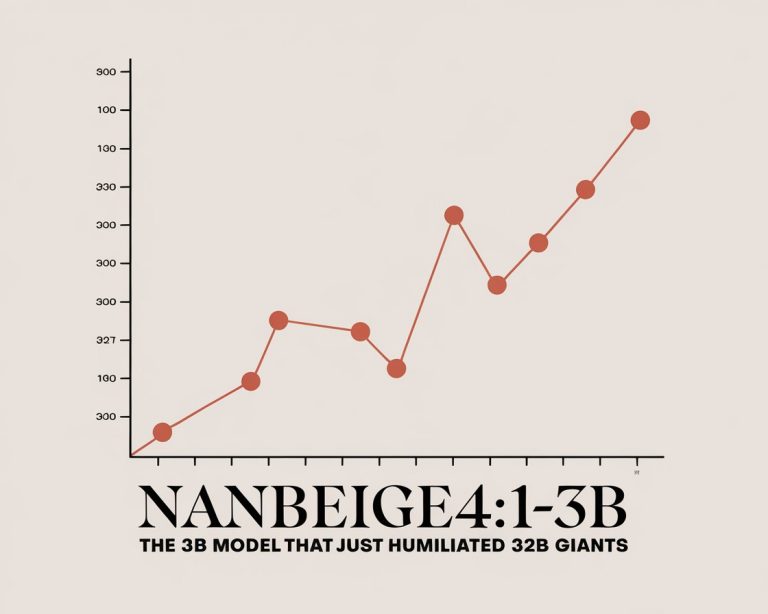
Nanbeige4.1-3B outperforms Qwen3-32B on alignment, tool use, and reasoning benchmarks. Here’s why this 3B model from China matters.

Leaks reveal DeepSeek V4 Lite generating perfect SVGs in 54 lines without thinking tokens. Why this spatial intelligence signals a massive shift in AI.

Google just dropped Gemini 3.1 Pro with a 1M token context window and 77.1% on ARC-AGI-2. But the real story is how it handles agentic coding and browser tasks.

GPT-5.3-Codex is now generally available for GitHub Copilot Pro, Business, and Enterprise users. 25% faster, half the tokens, 57% on SWE-Bench Pro. Here’s everything that changed.

Apple’s Foundation Models framework gives developers direct access to a 3B-parameter on-device LLM via Core ML and Metal 4. Here’s what it means for iOS and macOS app development.

Anthropic’s programmatic tool calling in Claude Sonnet 4.6 cuts token costs by up to 37% and boosts benchmark accuracy by 13%. Here’s why this changes how agents work forever.

Claude Sonnet 4.6 hits 79.6% SWE-bench with a 1M context window. GLM-5 scores 77.8% for $1/1M tokens open-source. Which agentic coding model wins in February 2026?

Claude Opus 4.6 vs Sonnet 4.6 – a deep benchmark breakdown. Discover which model wins on coding, agentic tasks, pricing, and real-world performance. The answer might surprise you.

Inclusion AI’s Ming-Omni-TTS unifies speech, music, and sound in one model. Here’s what it can do, where it falls short, and why it matters for 2026.