Chain-of-Thought has a dirty secret: it can’t fix its own mistakes.
Think about it. Every time GPT-5 or Gemini 2.5 Pro reasons through a problem, they’re writing in permanent ink. Each token is etched into the sequence, immutable. If the model makes a wrong assumption on step 3 of a 20-step geometry proof?
It has two choices: either append a verbose correction (“Actually, I was wrong earlier, let me reconsider…”) that eats context window and invites hallucination snowballing, or regenerate the entire sequence from scratch. Neither is great. And I’ve been watching this problem compound across every reasoning benchmark for months.
A new paper from Peking University and the Chinese Academy of Sciences just proposed something fundamentally different. Canvas-of-Thought (Canvas-CoT) doesn’t just extend CoT – it replaces the entire paradigm. Instead of chaining thoughts in an append-only text stream, it gives the model a mutable HTML canvas as an external reasoning substrate. The model can insert, modify, replace, and delete specific reasoning artifacts via DOM operations. It’s reasoning with a whiteboard, not a typewriter.
And the results? On RBench-V, Canvas-CoT with GPT-5 scored 32.4 overall – crushing Tree-of-Thought at 20.2 and Program-of-Thought at 23.5. That’s not an incremental improvement. That’s a paradigm shift.
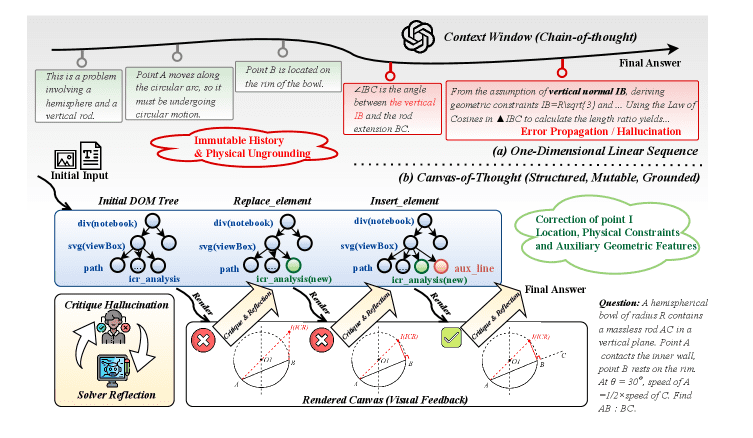
Figure 1: The paradigm shift – Linear CoT treats reasoning as immutable text. Canvas-CoT externalizes state into a structured, mutable DOM. Source: Sun et al., 2026
The Core Problem: CoT Is Writing With Permanent Ink
Here’s the hard constraint that nobody talks about enough. Autoregressive language models generate tokens left-to-right, one at a time. Once a token is committed, it becomes part of the context. This makes Chain-of-Thought fundamentally append-only. The reasoning history is immutable.
Why does this matter? Consider a spatial reasoning task – say, plotting geometric points on a coordinate plane. The model places point C at coordinates (5, 3). Three steps later, it realizes C should be at (3, 5).
In standard CoT, the model can’t go back and fix step 3. It has to generate new text saying “Wait, I made an error earlier…” and then re-describe the entire spatial configuration downstream. Every subsequent step that depended on C’s position needs correction too.
This creates three cascading failures the paper identifies:
- Hallucination snowballing: One error propagates through the entire chain, with each “correction” introducing new opportunities for inconsistency
- The overthinking effect: Accuracy actually declines with reasoning length, because longer chains accumulate more noise
- Visual neglect: Text-only reasoning can’t adequately represent spatial relationships, leading to “plausible-sounding but geometrically impossible configurations”
The paper’s framing is precise: “correcting a local error necessitates either generating verbose downstream corrections or regenerating the entire context.” That’s O(N) cost for every single correction in standard CoT, where N is the remaining sequence length. And this is exactly the kind of bottleneck that Chain-of-Thought’s 30x energy overhead makes even more painful.
How Canvas-CoT Actually Works
Canvas-CoT introduces a decoupled architecture that separates reasoning logic from state persistence. Instead of the model being a “narrator” that describes state changes in text, it becomes a “Stateful Controller” that manipulates an external DOM tree.
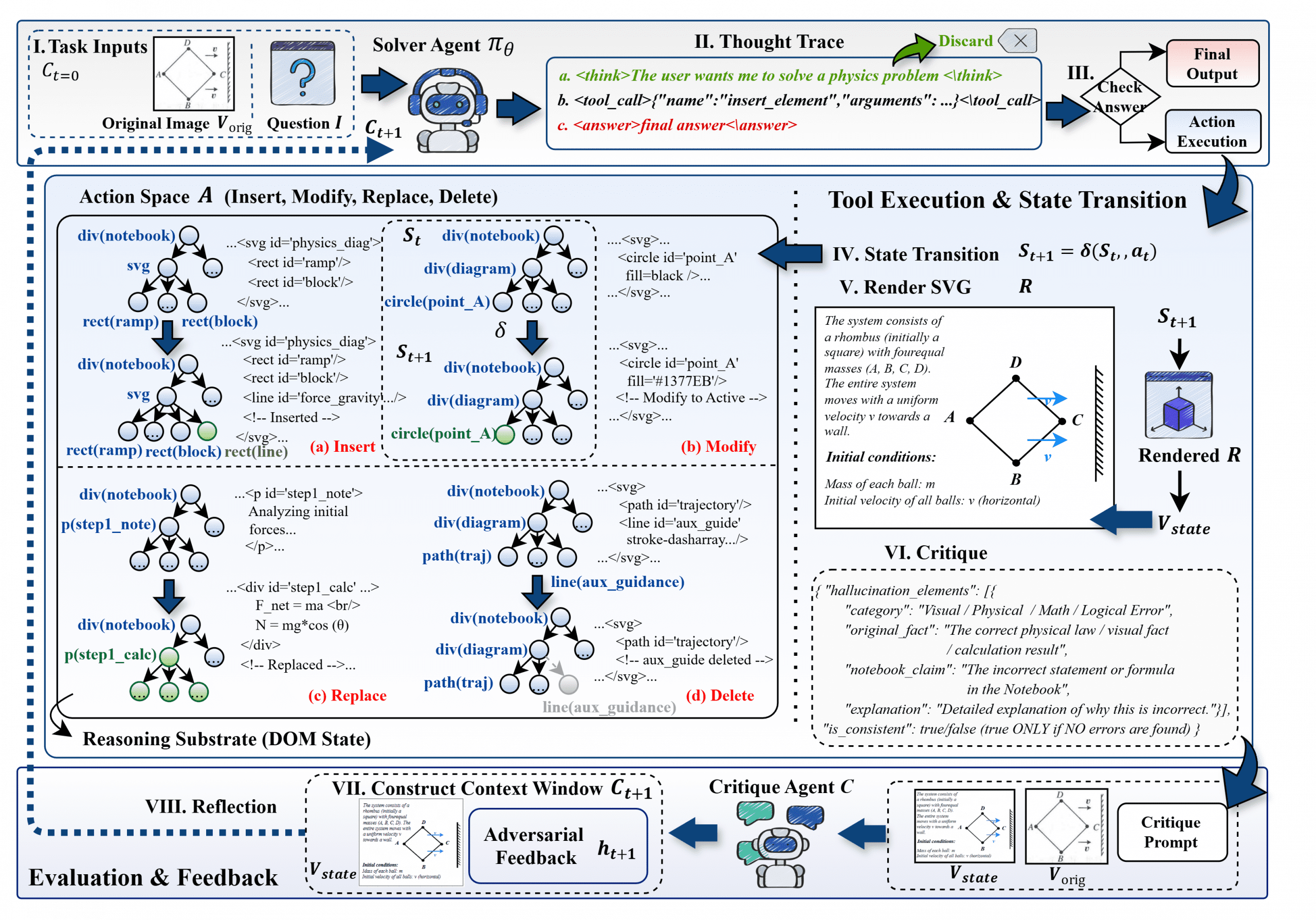
The Canvas-CoT Pipeline. The model initializes an HTML canvas, performs CRUD operations via tool calls, and gets visual feedback through a rendering-critique loop. Source: Sun et al., 2026
The DOM as a Reasoning Substrate
The paper defines reasoning artifacts as a DOM tree S = (V, E, P) where:
- V = A set of reasoning artifacts (geometric points, circuit components, logic nodes) represented as HTML elements with unique IDs
- E = Hierarchical relationships (parent-child nodes) and topological links
- P = Attributes bound to each node (coordinates, labels, constraints)
Each element gets an ID (like <rect id="obj_1">), enabling O(1) random access to any reasoning artifact via a hash-based address map. No more scanning through the entire reasoning history to find what you need to update.
The CRUD Operations
The model interacts with this substrate through four atomic operations:
| Operation | What It Does | Error Correction Cost |
|---|---|---|
| Insert | Adds new reasoning artifacts to the DOM tree | O(1) – just append the node |
| Modify | In-place attribute updates on specific nodes | O(1) – target by ID |
| Replace | Atomic swap of node references (preserves position) | O(1) – swap in new node |
| Delete | Prunes invalid reasoning paths recursively | O(1) – remove subtree |
Compare this to CoT’s error correction cost of O(N) for every fix. That’s the core efficiency argument. When GPT-5 realizes it placed point C wrong, it just calls modify_element("point_C", {x: 3, y: 5}). Done. No verbose correction text, no context window bloat, no cascading errors.
The Rendering-Critique Loop
Here’s where it gets really interesting. Canvas-CoT doesn’t just give the model a mutable state – it gives it visual feedback.
After each state transition, a headless browser renders the DOM tree into a raster image. A secondary Critique Agent compares this rendered image against the ground truth to identify discrepancies. The paper categorizes these into:
- Attribute Errors (wrong color, size, position)
- False Existences (hallucinated elements)
- Spatial Conflicts (overlapping objects that shouldn’t overlap)
The critique feedback functions as what the authors call a “visual gradient” – explicit information about the mismatch between the model’s internal world model and reality. This is the closest thing we have to backpropagation for reasoning: the model sees exactly where it went wrong and can make targeted corrections.
This dual-loop (DOM manipulation + visual critique) creates what the paper calls a “Markovian-like property” – the decision at step t+1 depends primarily on the current structured state and immediate feedback, not the potentially flawed textual history of previous steps.
The Benchmarks Don’t Lie
The paper evaluates Canvas-CoT across three benchmarks, comparing it against four baselines: Standard CoT, Tree-of-Thought, Program-of-Thought, and Iterative Reflection.
VCode: Visual Coding (SVG Generation)
Canvas-CoT dominates SVG generation tasks because it treats SVG elements as discrete, ID-addressable objects rather than a monolithic text stream. Standard MLLMs suffer from “structural collapse” during long-sequence generation – the SVG code degrades syntactically as the sequence gets longer. Canvas-CoT eliminates this entirely.
RBench-V: Physical and Spatial Reasoning
| Method | Overall | Counting | Map | Physics | Math | Game | Spatial |
|---|---|---|---|---|---|---|---|
| CoT (GPT-5) | 22.2 | 26.1 | 20.9 | 21.1 | 15.5 | 32.2 | 17.3 |
| ToT (GPT-5) | 20.2 | 20.5 | 27.0 | 17.2 | 17.4 | 22.4 | 16.4 |
| PoT (GPT-5) | 23.5 | 24.5 | 29.3 | 24.6 | 16.8 | 21.9 | 24.3 |
| Iterative (GPT-5) | 24.9 | 27.5 | 13.1 | 26.1 | 24.8 | 31.2 | 26.9 |
| Canvas-CoT (GPT-5) | 32.4 | 37.2 | 18.7 | 35.3 | 30.1 | 36.0 | 37.3 |
That’s a 30% improvement over the next best baseline on the Overall score. The biggest gains are in Physics (+9.2 over Iterative Reflection) and Spatial (+10.4 over Iterative Reflection) – exactly the domains where mutable state tracking matters most.
MathVista: Mathematical Reasoning
On MathVista, Canvas-CoT with Gemini-2.5-Pro achieved competitive results across algebraic reasoning, geometry, visual QA, and textbook problems. The geometry subtask showed particularly strong improvements, which makes sense – geometry is inherently spatial, and Canvas-CoT’s visual grounding catches coordinate errors that text-only reasoning misses.
Token Efficiency: Less Is More
One of the most practical implications of Canvas-CoT is token efficiency. And this matters when we’re talking about models like Claude Opus 4.6 that burn through context windows fast.
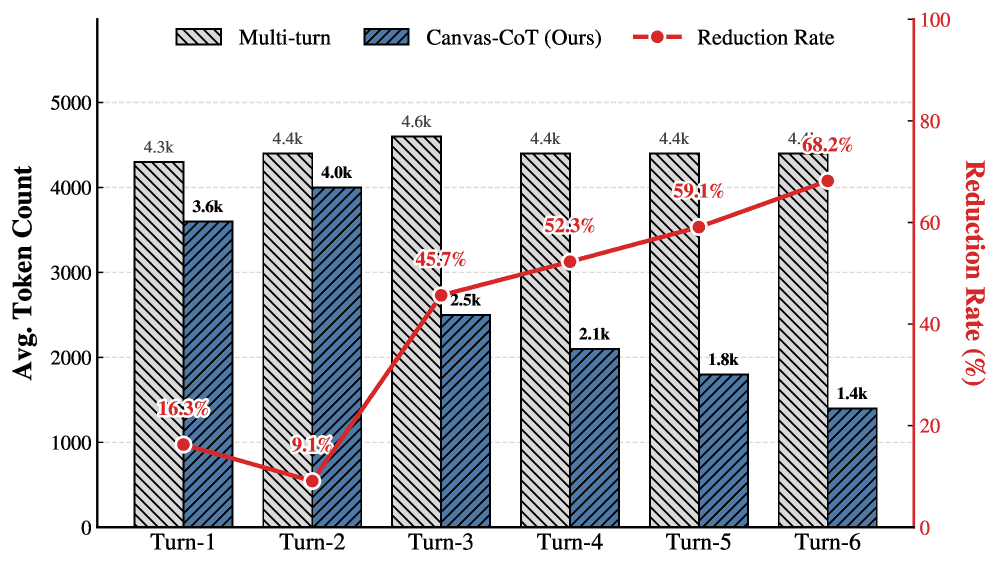
Token consumption on VCode benchmark. Canvas-CoT’s atomic updates converge quickly, while Iterative Reflection regenerates the full SVG each round. Source: Sun et al., 2026
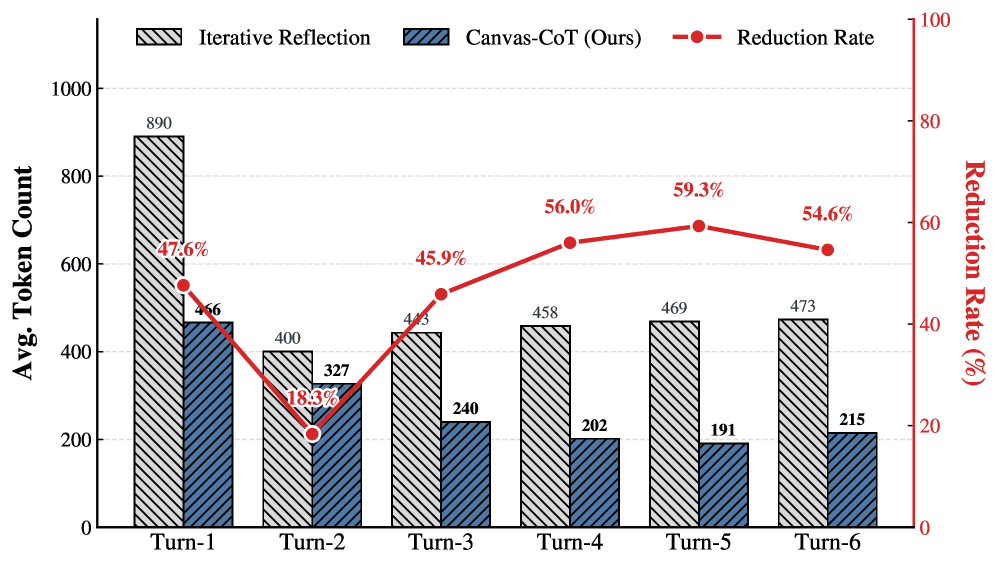
Token cost on RBench-V. Even for tasks with concise final answers, Iterative Reflection wastes tokens describing spatial configurations in text. Canvas-CoT’s surgical updates stay lean. Source: Sun et al., 2026
The pattern is clear: standard Iterative Reflection increases token consumption with each round because every reflection regenerates the entire output. Canvas-CoT’s token usage decreases as reasoning converges, because later updates are smaller surgical modifications.
The rendering loop adds a constant visual encoding overhead, but it’s dwarfed by the savings from not re-serializing the full state every round.
The Ablation: Where the Magic Really Comes From
The paper’s ablation study dissects the contribution of each component:
| Configuration | VCode (GPT-5) | VCode (Gemini-2.5-Pro) | RBench-V (GPT-5) |
|---|---|---|---|
| Iterative Reflection (baseline) | Baseline | Baseline | 24.9 |
| + DOM Canvas (no critique) | ↑ Notable | ↑ Notable | ↑ Improved |
| + Critique Loop (full Canvas-CoT) | ↑↑ Significant | ↑↑ Significant | 32.4 |
Two takeaways here. First, the DOM Canvas alone provides notable improvements over the baseline – just having a structured, mutable state helps, even without visual feedback. Second, adding the Critique Loop triggers a “second performance surge.” The visual grounding isn’t optional. It’s what closes the gap between “sometimes better” and “consistently better.”
This connects to a broader pattern I’ve been tracking: the most impactful improvements in AI reasoning aren’t coming from bigger models or more training data – they’re coming from better reasoning architectures.
Google’s Sequential Attention showed that smarter pruning beats brute force. Canvas-CoT shows that mutable state beats immutable chains. The theme is the same: structure matters more than scale.
Qualitative Evidence: Three Failure Modes Canvas-CoT Fixes
The paper includes detailed case studies showing three specific scenarios where Canvas-CoT outperforms linear reasoning:

Three capabilities in action – (a) Precise editing of complex SVG via ID-addressable nodes, (b) Spatial reasoning via atomic state mutations, (c) Error correction via visual-physical grounding. Source: Sun et al., 2026
Precision in SVG Generation: When refining a complex architectural SVG, Canvas-CoT assigns unique IDs to semantic components (like <g id="rightHall"> and <g id="gatehouse">). To fix a gatehouse, the model executes a targeted replace_element on just that node. CoT would need to regenerate the entire SVG code block, risking cascading errors.
Spatial Logic: In a cube net folding problem, as the agent identifies face pairs, it updates their visual attributes directly (modify_element with fill="blue"). These O(1) atomic updates offload cognitive burden onto the canvas. The canvas becomes dynamic external working memory.
Error Correction: In a geometry problem, the agent initially plots points C and D in swapped positions. A text-only model might hallucinate a solution from the wrong topology. But Canvas-CoT’s critique loop catches the misalignment by comparing the rendered diagram against the original, immediately triggering a corrective modify_element to swap the coordinates.
What This Means for the Reasoning Arms Race
Let me be direct about what Canvas-CoT implies for the broader AI landscape.
For model developers: This paper suggests that the next frontier in reasoning isn’t just training better CoT models – it’s giving models better external tools for reasoning. The DOM substrate is essentially an external working memory with random access.
That’s a fundamentally different compute paradigm than “generate more thinking tokens.” For context, this aligns with what DeepSeek R2 and GPT-5 have been hinting at: the future of reasoning involves tool use, not just longer chains.
For developers using LLM APIs: Canvas-CoT currently requires a multi-turn agentic setup with a headless browser for rendering. It’s not something you can drop into a single API call. But the core insight – mutable structured state – could be adapted to lighter substrates. Imagine a JSON-based state object that the model can CRUD-operate on, with validation logic instead of visual rendering. That’s already feasible today.
For benchmarks: This paper highlights how badly text-centric benchmarks underrepresent spatial reasoning. If your evaluation only measures text-in-text-out performance, you’re missing the domains where Canvas-CoT shines brightest. RBench-V and VCode are better proxies for real-world complexity than standard math benchmarks that frontier models are already saturating.
The hard constraint: Canvas-CoT requires rendering infrastructure (a headless browser) and a secondary critique model. That adds latency and cost. For real-time applications, the rendering loop is a bottleneck. The paper doesn’t address this trade-off deeply, and in production settings, the additional inference calls for the critique agent aren’t free – especially at current API pricing tiers.
The Bottom Line
Canvas-of-Thought isn’t just another prompting trick. It’s an architectural argument that the way we’ve been doing reasoning – linear, append-only, immutable – is fundamentally mismatched to how complex reasoning actually works.
The evidence is pretty compelling. Structured mutable reasoning beats linear CoT on spatial tasks. The visual grounding loop catches errors that text-only self-reflection misses. And the token efficiency gains suggest that mutable state isn’t just more accurate – it’s cheaper per correct answer.
But let’s temper the enthusiasm with realism. Canvas-CoT currently excels at tasks with clear visual/spatial structure (SVG generation, geometry, physics simulation). Whether this paradigm extends to abstract reasoning domains (legal analysis, philosophical argumentation, strategic planning) remains an open question. And the infrastructure requirements – headless browser, dual-model critique – make it heavyweight compared to a simple CoT prompt.
Still, the core insight will survive even if the specific implementation evolves: reasoning should be mutable, not append-only. That’s a principle that’s going to reshape how we build reasoning systems for the next generation of AI.
FAQ
What is Canvas-of-Thought (Canvas-CoT)?
Canvas-CoT is a reasoning framework that gives LLMs a mutable HTML canvas as an external reasoning substrate. Instead of generating linear text chains, the model performs CRUD operations (Insert, Modify, Replace, Delete) on DOM elements, enabling in-place corrections without regenerating the full context. It also includes a rendering-based critique loop for visual feedback.
How does Canvas-CoT differ from Tree-of-Thought and Graph-of-Thought?
Tree-of-Thought (ToT) and Graph-of-Thought (GoT) expand the search topology of reasoning but still use immutable text as the underlying substrate. Canvas-CoT changes the substrate itself – from immutable text to a mutable DOM tree with visual rendering. ToT explores multiple reasoning paths; Canvas-CoT allows in-place editing of a single evolving state.
What models does Canvas-CoT work with?
The paper evaluated Canvas-CoT with GPT-5 and Gemini-2.5-Pro as the primary solver models, using the same models as critique agents. The framework is model-agnostic – any MLLM capable of generating structured HTML/SVG tool calls could serve as the controller.
Is Canvas-CoT slower than standard CoT?
It adds latency from the rendering loop (headless browser rendering + critique agent inference). But it uses fewer total tokens because it avoids regenerating full context each iteration. Whether the net latency is higher depends on task complexity – for simple tasks, CoT is faster; for complex multi-step spatial reasoning, Canvas-CoT’s surgical updates can be net faster.
Can I use Canvas-CoT today?
The paper’s code hasn’t been publicly released yet (the authors indicate it will be released soon). But the architectural pattern – mutable structured state + validation loop – can be implemented independently using any LLM with tool-use capabilities, a headless browser (Puppeteer/Playwright), and a critique prompt.