Remember when GitHub Copilot was basically autocomplete with a PhD? Those days are over.
On February 9, 2026, GitHub flipped the switch on GPT-5.3-Codex going generally available across all Copilot tiers. Not a preview. Not a beta. A full production rollout to millions of developers, just ten days after the model first dropped. And the developer community’s verdict? This is the first Codex model that actually behaves like a colleague rather than a very expensive tab-completion.
Reddit’s r/LocalLLaMA called it a “hyperproductive intern” – the kind that rapidly iterates, self-corrects, and doesn’t need its hand held on every sub-task. Compare that to the “constant checking” and “junior grade code quality” complaints that dogged earlier Copilot agent releases. Something genuinely changed here.
But here’s the question worth asking: does “better benchmarks” translate to “changes how you work”? I think yes. Let me show you why.
What the Numbers Actually Tell You
Start with the efficiency story, because it’s the one that matters most for real usage.
GPT-5.3-Codex is 25% faster on agentic tasks than GPT-5.2-Codex. That’s nice. But the number that actually moves the needle is token consumption: the new model uses less than half the tokens of its predecessor for equivalent work. Token cost is the invisible tax on every long-running agent workflow. Cut it by 50%+ and you either run twice the workload for the same price, or you finally make complex, multi-file refactors economically feasible at scale.
The benchmarks hold up too:
| Benchmark | GPT-5.3-Codex | Context |
|---|---|---|
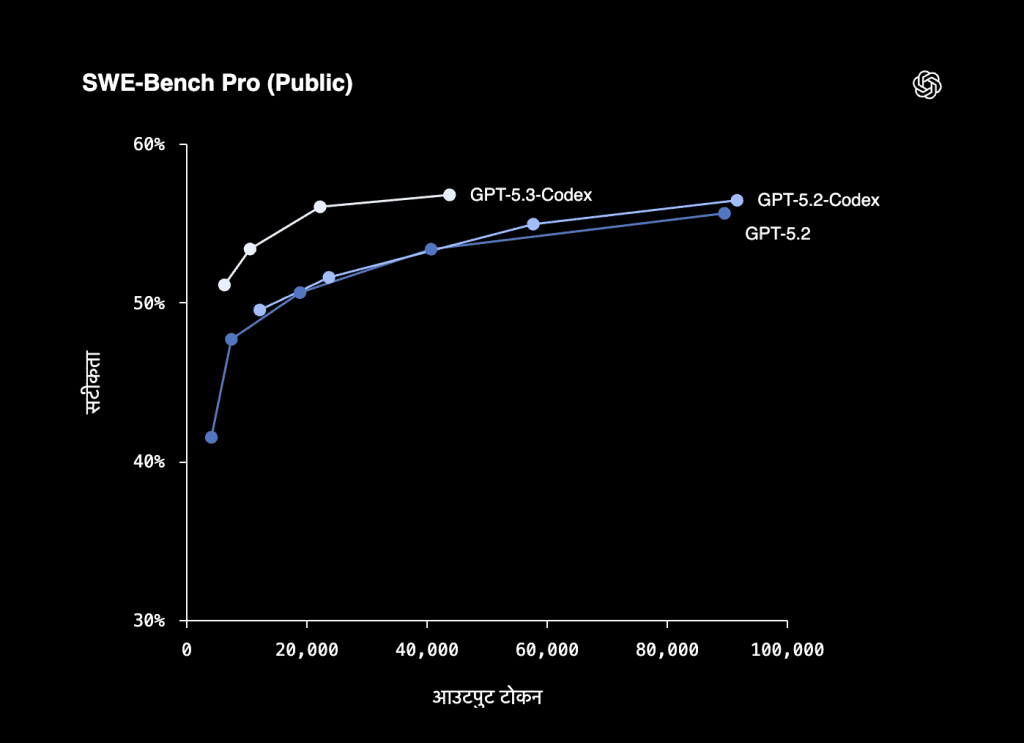
| SWE-Bench Pro | 57% (56.8%) | Contamination-resistant, 4 languages |
| Terminal-Bench 2.0 | 77.3% | 13-point jump from GPT-5.2 |
| Context Window | 128K tokens | Unchanged from GPT-5.2 |
SWE-Bench Pro is the one I’d pay attention to. OpenAI specifically designed it to resist the memorization tricks that inflate scores on the public SWE-Bench Verified leaderboard. It spans four programming languages and is deliberately harder to overfit. The Raschka Rule applies here: “If the test set is public, it isn’t a real test set.” A 57% on a contamination-resistant benchmark is more honest – and more impressive – than an 80%+ on a track models have been trained against.
Terminal-Bench 2.0 at 77.3% is the real kicker. When we compared Claude Opus 4.6 to Sonnet 4.6, Opus scored 65.4% on that same benchmark – and we called it dominant. GPT-5.3-Codex is running 12 points ahead of the best Anthropic has. Terminal execution skill is exactly what you need for the long-horizon tasks Copilot now handles. This gap matters.
The 128K context window is unchanged. Not infinite, but enough to keep a sizeable codebase in working memory without shuffling context constantly.
From Autocomplete to Actual Agent
Here’s what the “agent” label actually means in practice – because it’s not just a marketing rebrand.
Earlier versions of Copilot were fundamentally reactive: you prompt, it responds. GPT-5.3-Codex is built for what OpenAI calls “long-horizon tasks” – multi-step workflows that chain together research, tool calls, iterative debugging, and validation without you guiding every step. You can interrupt and redirect whenever you want. But you don’t have to.
The model ships across every major surface:
- VS Code – all modes, including agent mode where it edits your local files in real-time
- GitHub.com – the web interface with full agent capabilities
- GitHub Mobile – iOS and Android
- GitHub CLI – for terminal purists
- GitHub Copilot Coding Agent – the async version that works inside GitHub Actions
That last one is worth understanding separately. The Copilot Coding Agent is asynchronous – you assign it a GitHub issue, it spins up in an isolated Actions environment, works across multiple files, runs tests, and opens a pull request. You review it like any other PR. No watching it work. No babysitting. It’s closer to delegating to a contractor than using a tool.
This pattern – models that plan, use tools, and iterate – is now the shared architecture across every major coding AI. Anthropic’s programmatic tool calling, OpenAI’s agent framework, GitHub’s Coding Agent. They’ve all converged on the same answer.
One detail OpenAI buried in the launch post deserves more attention than it got: early versions of GPT-5.3-Codex “were instrumental in debugging its own training, managing deployment, and diagnosing evaluations.” AI helping train AI. That’s either a remarkable capability demonstration or a reason to think carefully about oversight. Probably both.
Who Gets This and What You Need to Do
Access works differently depending on your Copilot tier – and the split has real operational consequences.
Automatic access (no action needed):
Copilot Pro subscribers
Copilot Pro+ subscribers
Requires admin action: Copilot Business and Enterprise – organization administrators must explicitly enable the GPT-5.3-Codex policy in Copilot settings
The policy gate is a deliberate design. Enterprise orgs have compliance reviews, security assessments, and change management processes that make “automatic model upgrades” untenable. GitHub gets that. But the practical effect is that right now, a substantial chunk of the enterprise developer market is still sitting on GPT-5.2-Codex because no one has flipped the switch yet. If you’re an admin reading this, go check.
Once enabled, GPT-5.3-Codex appears in the model switcher in your preferred interface. It joins GPT-4o, Claude 3.5 and 3.7 Sonnet, and Gemini 2.0 Flash – not replacing them. This multi-model flexibility, which we covered in depth with the GitHub Copilot CLI launch, is GitHub’s real strategic play: position Copilot as the IDE-layer abstraction, model-agnostic, always offering the best option for the task.
The Cerebras Wildcard: Codex-Spark
You can’t talk about GPT-5.3-Codex without covering what arrived a week later.
On February 12, OpenAI released GPT-5.3-Codex-Spark as a research preview for ChatGPT Pro users. Smaller model, same accuracy, radically different speed profile: 1,000+ tokens per second. That’s roughly 15x faster than the base model.
The interesting part isn’t the speed. It’s the hardware. Codex-Spark runs on Cerebras’ Wafer-Scale Engine 3 (WSE-3) – marking OpenAI’s first production deployment on non-NVIDIA silicon. That’s a bigger deal than it sounds. For years, “OpenAI model” implicitly meant “NVIDIA GPU.” The Cerebras collaboration, announced in January 2026 and now live in production, tells you OpenAI is actively building hardware optionality into their inference stack. Just like cloud providers have been diversifying away from NVIDIA for training, OpenAI is doing the same for inference.
The practical tradeoff is clean: standard GPT-5.3-Codex takes 15-17 minutes on SWE-Bench Pro tasks. Codex-Spark gets comparable accuracy in 2-3 minutes. You’re not picking quality over speed – you’re picking depth of reasoning over raw throughput. Think of it as a patient senior engineer versus a blazing-fast peer who still ships working code. The speed-efficiency tradeoff we analyzed in Chinese agentic models applies directly here: “fast enough” at scale often beats “slow and perfect” for most real-world workflows.
During the research preview, Codex-Spark usage has its own separate rate limits and doesn’t count against your standard ChatGPT Pro quota. OpenAI clearly wants real stress-testing from real developers before pricing it into production tiers.
The Bottom Line
GPT-5.3-Codex going GA isn’t a model upgrade announcement. It’s OpenAI and GitHub declaring that agentic code generation – not completion, not suggestion – is the product now.
The benchmarks hold up under scrutiny. The token efficiency improvement is real and economically significant. The Cerebras deployment shows OpenAI isn’t just shipping models, they’re engineering their inference infrastructure for a world where speed and quality matter simultaneously.
But. The enterprise policy gap is real. Most Business and Enterprise organizations haven’t enabled this yet, which means the actual productivity experiment at scale hasn’t started. When those orgs flip the switch, that’s when we’ll see whether 77.3% on Terminal-Bench translates to measurable developer-hours recovered.
Watch for Codex-Spark’s production launch. If 1,000+ tokens/second at competitive pricing becomes available to all Copilot subscribers, the definition of “real-time AI coding assistance” gets rewritten from scratch.
FAQ
How is GPT-5.3-Codex different from GPT-5.2-Codex?
25% faster on agentic tasks, and uses less than half the tokens for equivalent work. It scores 57% on SWE-Bench Pro and 77.3% on Terminal-Bench 2.0. The core architecture is refined for long-horizon task handling – think multi-file refactors and autonomous debugging runs rather than single-prompt responses.
Do I need a special plan to use GPT-5.3-Codex?
Copilot Pro and Pro+ users get immediate access. Copilot Business and Enterprise users need their organization administrator to enable the GPT-5.3-Codex policy in Copilot settings first – it’s not automatic.
What is GPT-5.3-Codex-Spark?
A smaller, ultra-fast variant released February 12, 2026, currently in research preview for ChatGPT Pro users. It runs on Cerebras WSE-3 chips and delivers 1,000+ tokens per second – roughly 15x faster than base Codex, with comparable accuracy on SWE-Bench Pro but in 2-3 minutes instead of 15-17.
How does it compare to Claude Opus 4.6?
On Terminal-Bench 2.0: GPT-5.3-Codex scores 77.3% versus Opus 4.6’s 65.4% – a significant gap. Reddit’s developer consensus: Codex is stronger for rapid iteration and implementation loops; Opus 4.6 is preferred for complex system design and architectural planning.
Where do I select GPT-5.3-Codex in VS Code?
In the GitHub Copilot Chat panel, look for the model switcher dropdown near the top. GPT-5.3-Codex appears there for Pro/Pro+ users immediately, or for Business/Enterprise users once admins have enabled the policy.