

The race for local AI dominance just got a new speed demon. While the world was busy watching deepseek and llama battles, Zhipu AI quietly dropped a bombshell – actually, two of them. Meet GLM-4.7-Flash and GLM-4.6V-Flash, a pair of models that aren’t just incremental updates; they are fundamental shifts in what we expect from “lightweight” models.
If you’re running AI on consumer hardware – think RTX 3090s or Apple Silicon – stop what you’re doing. Your local stack is about to get a massive upgrade.
The “Real” Story: Speed Meets Intelligence
Let’s be real: usually, when a model has “Flash” in the name, it means “dumb but fast.” You trade reasoning for tokens-per-second. Zhipu AI just threw that tradeoff out the window.
GLM-4.7-Flash isn’t just fast; it’s a coding beast. We’re talking about a 30B parameter Mixture-of-Experts (MoE) architecture that only activates 3 billion parameters per token. For context, that’s lighter than a Llama-3-8B run but with the knowledge capacity of a much larger dense model.
The result? It hits 59.2% on SWE-bench Verified. That beats Qwen2.5-Coder-32B (verified) and is nipping at the heels of GPT-4 versions from just a few months ago. And it does this while churning out tokens at 4,398 tokens/second on an H200, or a very respectable 82 tokens/second on your M4 Max MacBook Pro.
Benchmarks: The Numbers Don’t Lie
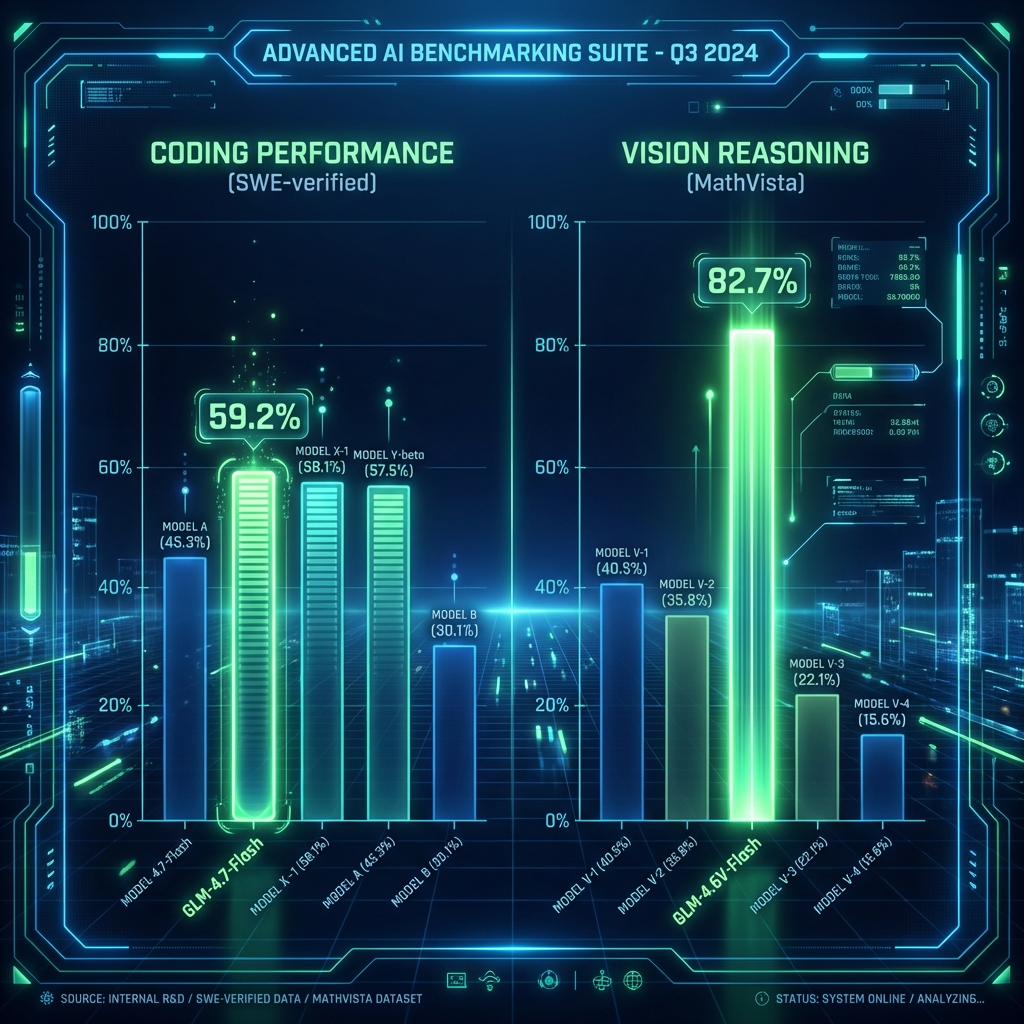
We dug into the numbers, and the “Flash” moniker isn’t marketing fluff. It’s engineering precision.
Coding: GLM-4.7-Flash vs. The World
In the 30B weight class, GLM-4.7-Flash is punching way above its weight:
- SWE-bench Verified: 59.2% – This is the metric that matters for real-world coding agents. It practically matches specialized coding models while being significantly lighter to run.
- τ²-Bench (Tool Use): 79.5% – This reveals why it feels so “smart.” It handles multi-step tool invocations better than almost any local model we’ve tested.
- speed: 4,000+ tok/s on server-grade hardware means near-instant latency.
Vision: GLM-4.6V-Flash vs. Qwen
The 9B Vision-Language model is equally impressive, trading blows with the excellent Qwen-VL series:
- MathVista: 82.7% – Significantly outperforming Qwen3-VL-Thinking (78.5%). If you need a model to read charts or solve visual math problems, this is your new daily driver.
- MMMU: 71.1% – Competitive with Qwen3-VL (73.5%), proving it can handle massive multidisciplinary understanding tasks.
- OCRBench: 84.7% – It reads text from images with near-perfect accuracy.
The Real Cost of Local Intelligence
Here is what you actually need to run these beasts. Forget cloud APIs; this is about owning the stack.
GLM-4.7-Flash (30B MoE)
This is the big one. While a full 30B dense model typically eats 60GB+ of VRAM, the MoE architecture and 4-bit quantization work magic.
- Minimum Specs: NVIDIA RTX 3090 / 4090 (24GB VRAM) or Mac M2/M3 Max (32GB+ Unified Memory).
- Actual Usage: Running a
Q4_K_Mquantized version consumes ~16GB VRAM to load, leaving just enough room for the 128k context on a 24GB card. - Hardware Cost: You are looking at a ~$800 used RTX 3090 or a MacBook Pro.
- Electric Bill: At ~300W load during inference, running this 24/7 costs roughly $0.90 per day (avg US rates). Compare that to your $20/mo OpenAI subscription; if you use it heavily, local wins.
GLM-4.6V-Flash (9B VLM)
The entry barrier here is incredibly low.
- Minimum Specs: RTX 3060 / 4060 (8GB/12GB VRAM) or standard Mac M1/M2/M3 (16GB+ Memory).
- Actual Usage: A
Q4_Kquantization sits comfortably at ~6.5GB VRAM, making it viable on almost any modern gaming laptop. - Offline Capability: This is fully air-gapped capable. You can run document analysis on sensitive financial PDFs without a single byte leaving your machine.
GLM-4.7-Flash: The Coding Specialist

Why does this matter? Because for the first time, we have a model that can genuinely handle complex, agentic coding workflows locally without taking a coffee break between responses.
- Context Window: 128,000 tokens. You can shove entire codebases into it.
- Architecture: 30B MoE (3B Active). This is the “Goldilocks” zone for local inference – high capacity, low latency.
- τ²-Bench Score: 79.5%. This measures tool use and agentic capabilities. It means this model doesn’t just write code; it knows how to use tools to execute it.
This is the model you want powering your VS Code extension or your local Devin-clone. It’s smart enough to fix bugs and fast enough to autocomplete your thoughts.
GLM-4.6V-Flash: The Multimodal Maestra

Then there’s the GLM-4.6V-Flash. If 4.7 is the brain, 4.6V is the eyes.
It’s a 9B parameter vision-language model (VLM) that brings native function calling to visual tasks. Most small VLMs struggle to count objects or read charts accurately. GLM-4.6V-Flash was built for this. It also sports the 128k context window, meaning it isn’t just looking at a single image; it can analyze video frames or multi-page PDFs with visual elements.
The killer feature? Native Function Calling. You can show it a screenshot of a UI and ask it to write the Selenium script to test it, or show it a chart and ask it to query a database for the underlying data. It bridges the gap between seeing and doing.
The Bottom Line
Zhipu AI is proving that the future of AI isn’t just about TRILLION parameter god-models in the cloud. It’s about highly optimized, specialized models that live on your machine.
With GLM-4.7-Flash, you get a coding assistant that rivals GPT-4 Turbo for free (API) or cheap local inference. With GLM-4.6V-Flash, you get a multimodal agent that fits in your GPU memory.
The era of “good enough” local AI is over. We’re entering the era of “better, faster, and local.” Download the weights, spin up llama.cpp or vllm, and see for yourself.
What do you think? Is 30B MoE the future of local coding? Let us know in the comments.



