

AI is cheap. Suspiciously cheap. You can get state-of-the-art inference for less than $5 per million input tokens. You can get a “pro” subscription to Cursor, Gemini Advanced, or ChatGPT Pro for anywhere between $20 and $200 a month. That feels “decent.”
But there is a nagging voice in the back of every engineer’s head: What if I just owned the iron?
Maybe you want privacy. Maybe you want to escape the rate limits. Maybe you just want to feel the warmth of a 700W GPU heating your apartment in winter. Today, we are going to look at the Total Cost of Ownership (TCO) to see if the math actually works in our favor.
We saw Nvidia’s recent announcement of the Vera Rubin chip, promising efficiency gains that make us drool. But does that change the equation? When does it actually make sense to run SOTA models on your own mecha?
Let’s break it down.

The Napkin Math: $200 vs $30,000
Let’s start with the baseline variables.
The Subscription:
If you max out a premium AI subscription — let’s say the new “Ultra” tiers from Google or OpenAI — you are paying around $200 a month.
Over a 6-year hardware lifecycle (generous for GPUs, but let’s play along), that tallies up:
$200/mo * 72 months = $14,400
The Hardware:
Now, let’s look at a datacenter-grade card like the Nvidia H100. Even in 2026, with the Rubin announcement, a PCIe H100 still retails for around $30,000.
Verdict:
Right up front, the math hates you. You are paying double the cost just to acquire the card, before you’ve even plugged it in.
- Subscription: $14,400
- Hardware (Capex Only): $30,000
But wait. What if we rent?
NeoClouds currently hover around $2.20 per hour for an H100 spot instance.
8 hours/day 6 years (weekends included) = $38,544
8 hours/day 6 years (weekdays only) = $27,456
It’s getting closer, but owning still looks like a bad bet. Unless… you have friends.
The “Cluster of Friends” Strategy
Since one person’s subscription cost is $14,400, maybe we can pool our money.
If you find 4 friends, your combined subscription budget is:
$14,400 * 4 = $57,600
Suddenly, the $30,000 price tag of an H100 looks delicious. You buy the card, save $27k, and high-five each other.
STOP.
You forgot the hidden killers: Electricity and Cooling.
The Hidden Killers
Let’s assume you have a desktop rig ready to host this beast.
- Power Draw: An H100 PCIe skews around 350W (0.35 kW).
- Uptime: We are running this 24/7 for 6 years (it’s a server now, remember?).
- Rate: Average electricity cost (e.g., Michigan) is around $0.20/kWh.
Electricity Cost:
0.35 kW 24 hours 365 days 6 years $0.20 = $3,679
Cooling Cost:
You can’t just run a space heater in a closet. You need active cooling. Even with a conservative PUE (Power Usage Effectiveness) of 1.5, you are matching the electricity cost for cooling.
Cooling: ~$3,700
The Real TCO for 4 Friends:
- Card: $30,000
- Electricity: $3,700
- Cooling: $3,700
- Total: $37,400
You are still under the $57,600 subscription budget! You are winning!
…Until you try to run a model.
The Model Bottleneck: The “Kim K2” Benchmark

Here is the tragedy of local AI. The hardware fits the budget, but the model does not fit the hardware.
Let’s look at a standard SOTA benchmark for 2026: the Kim K2 Thinking Model.
- Parameters: 1 Trillion
- Architecture: Mixture of Experts (MoE)
- Active Parameters: 32 Billion per token
- Experts: 384
This sparsity is great for inference speed, but VRAM does not care about sparsity. You need to load the experts into memory.
The Reality Check:
To fit a full-precision (FP16) Kim K2 model, you need 14 H100s.
Even if you quantize it down to 4-bit or the new 1.58-bit frontier, you need 3 to 8 H100s.
Your single shared H100 has 80GB of VRAM. It chokes.
Scaling to Despair (The DGX Trap)
To actually run this model, you need a DGX H100 (8x GPUs).
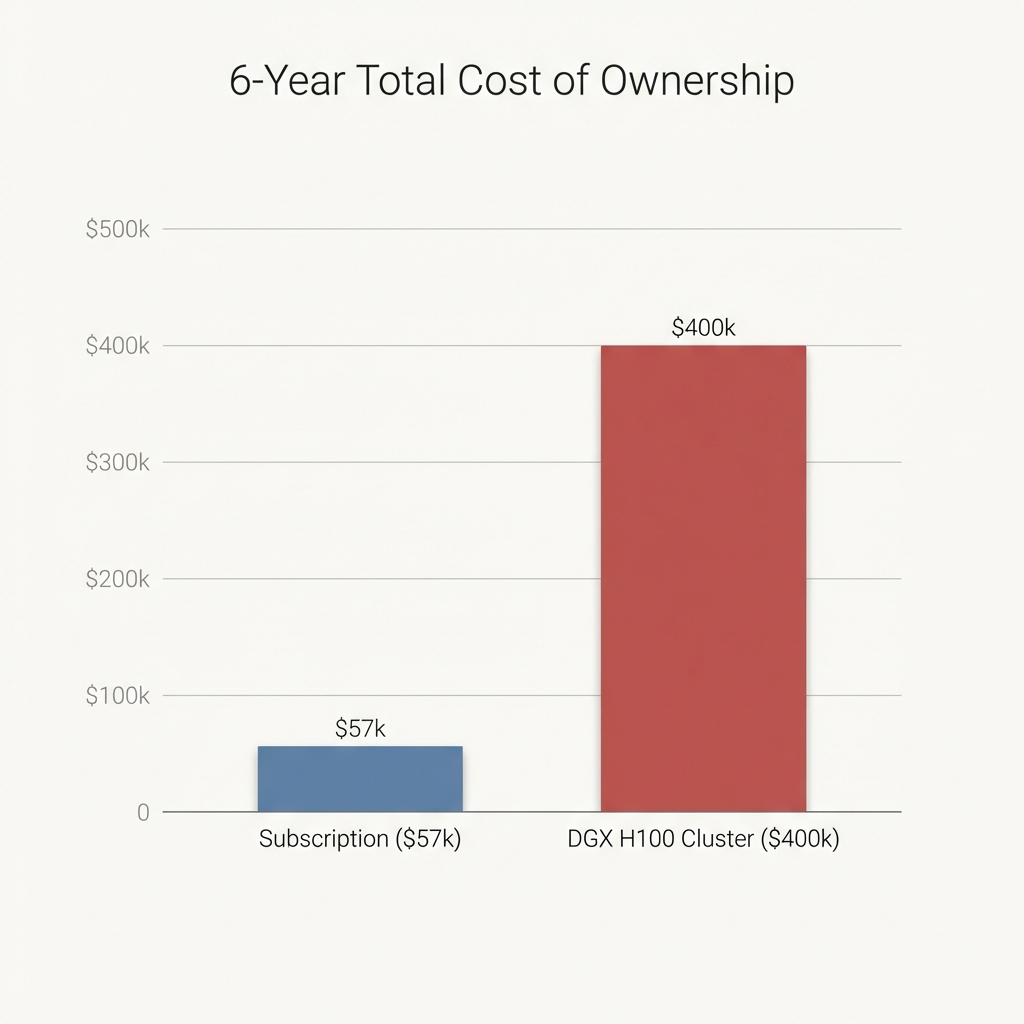
- Cost: ~$285,000 – $300,000
- Ops Cost (Power/Cooling): ~$100,000
- Total TCO: ~$400,000
To break even against the subscription model, you now need a distinct group of 28 friends to chip in.
$14,400 * 28 = $403,200
Okay, you found 28 people. You bought the DGX. Now, what is the user experience?
The VRAM Slice:
- Total VRAM: 640GB (8x 80GB)
- Model Weights: ~500GB (just to load the model!)
- Remaining VRAM: 140GB
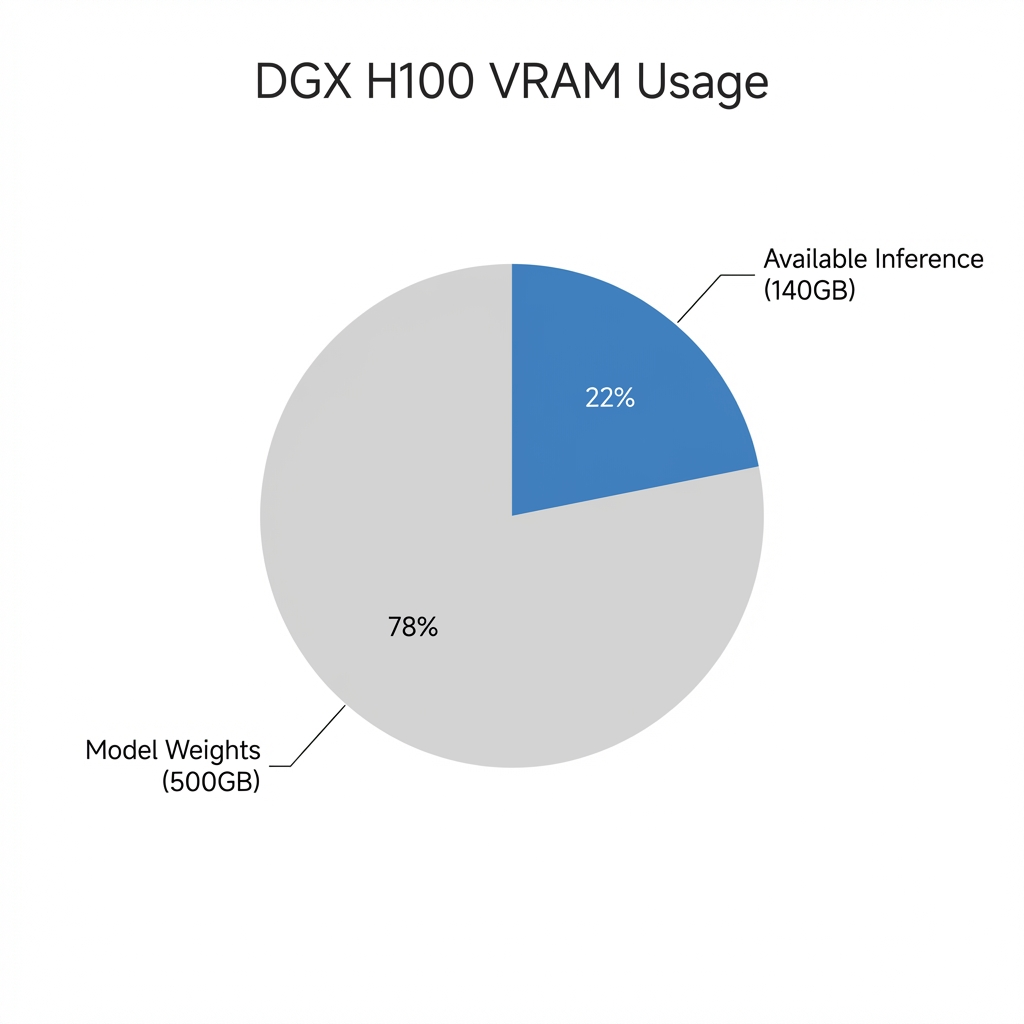
You have 140GB of “scratchpad” memory (KV Cache) to share between 28 people.
140GB / 28 users = 5GB per user
Based on the Kim K2 architecture (approx 1.7MB per token for KV cache at this scale due to expert routing overhead), 5GB gets you…
2,850 tokens of context.
That is barely enough for a “Hello World” function and a system prompt. You spent $400,000 to build a chatbot that gets amnesia after 3 paragraphs.
Conclusion: The Era of Subsidized Intelligence
When you run the math, the conclusion is inescapable: Frontier Labs are subsidizing your existence.
Companies like Google and OpenAI run on margins that would bankrupt an individual. They are offering you 2-million-token context windows (Gemini 3 Pro) and massive MoE reasoning models (o3/Kim K2) for a price that barely covers the electricity to cool the rack.
Why? Because they aren’t selling you compute. They are buying your loyalty to their ecosystem. API pricing might be break-even, but subscriptions are about lock-in.
Final Verdict:
Buy H100s if: You are training custom models, need 24/7 localized finetuning on small datasets, or hate money.
Buy Subscriptions if: You want to run SOTA models today without needing a degree in thermodynamics or a syndicate of 28 investors.
The math doesn’t lie. For now, let the giants burn their cash. We’ll just enjoy the heat.



