

In 1965, the statistician I.J. Good wrote a sentence that has haunted computer science for sixty years:
> “Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever… [It] could design even better machines; there would then unquestionably be an ‘intelligence explosion,’ and the intelligence of man would be left far behind.”
For decades, this was sci-fi.
In 2023, it was a “safety concern.”
In January 2026, it looks like an engineering roadmap.
We are witnessing the convergence of three specific technologies—Formal Verification (Aristotle), Autonomous Optimization (AI CUDA Engineer), and Synthetic Data Loops—that suggest the fuse of the Intelligence Explosion has technically been lit.
It’s not a “Hard Takeoff” yet (where AI becomes god-like overnight). But it is undeniably a recursive loop.
1. The Spark: Auto-Formalization (AI Checking AI)
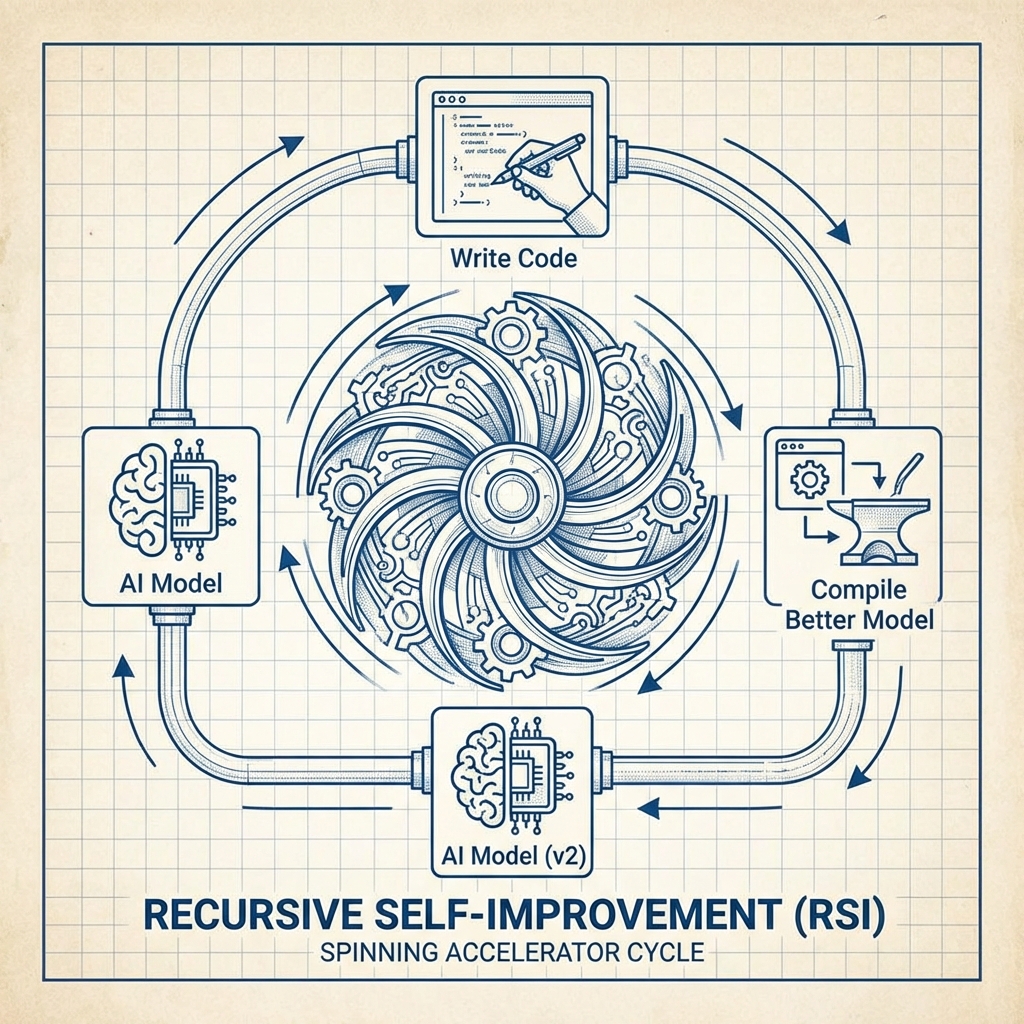
The math breakthrough we covered yesterday (AI solving Erdős #397) wasn’t just about math. It was a proof-of-concept for Self-Correction.
The biggest bottleneck in AI improvement has always been human evaluation. If GPT-4 wrote code, a human had to check if it worked. This is slow (biological speed).
But with agents like Aristotle and Google’s AlphaProof, the AI generates a solution, and another AI formally verifies it.
If the solution is wrong, the loop tightens. The models learn from their own mistakes at silicon speed, without a human in the loop. This removes the “biological brake” from the improvement cycle.
2. The Fuel: AI Writing Its Own Engine (CUDA Optimization)
While theorists worry about “AI writing its own source code,” engineers are already having AI rewrite the hardware instructions.
A new paper under review for ICLR 2026, EvoEngineer, demonstrates an AI system checking and optimizing CUDA kernels (the low-level instructions that run on NVIDIA GPUs).
The results? 3.12x speed increases over human-written kernels.
Think about that. The AI isn’t just “using” the GPU; it is re-architecting how the GPU processes data to make itself run faster.
* Step 1: AI Model A writes a better kernel.
* Step 2: Model A runs 3x faster using that kernel.
Step 3: Model A (now faster) has more compute budget to write an even better* kernel.
This is the literal definition of Recursive Self-Improvement (RSI).
3. The Atmosphere: Synthetic Data That Works

The old skeptical argument was “Model Collapse”—the idea that if AI trains on AI-generated data, it gets dumber (like making a copy of a photocopy).
That theory is dead.
We now know that if you use computational feedback (like the math/code verification above) to filter the synthetic data, the model actually gets smarter. It’s not “photocopying”; it’s “distilling.”
DeepSeek and OpenAI are both reportedly training their 2026 models on trillions of tokens of synthetic reasoning chains that no human ever wrote. The AI is effectively teaching itself physics and logic, generating the textbook it studies from.
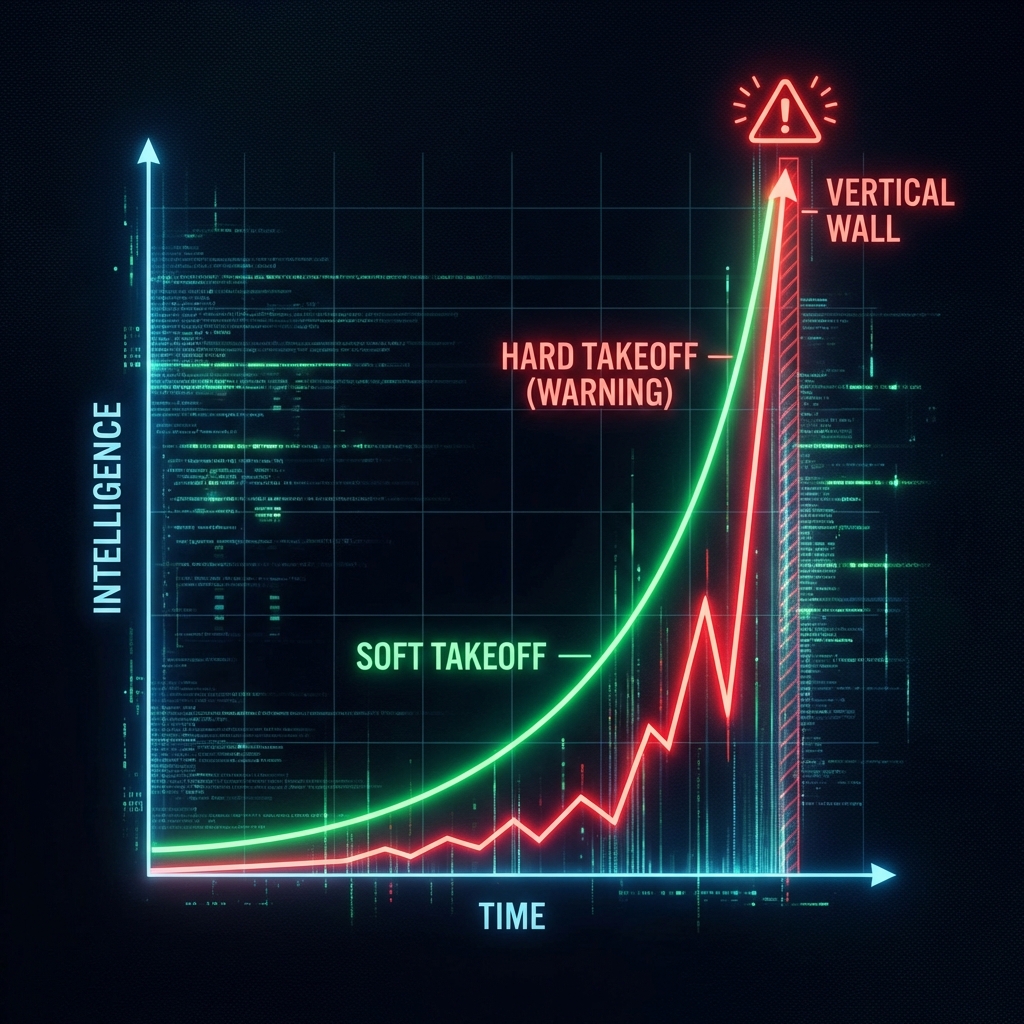
The “Soft Takeoff” Scenario
Does this mean we wake up tomorrow to a superintelligence? Probably not.
We are likely in a Soft Takeoff:
* 2023-2025: Human-driven improvement (slow, linear).
* 2026 (Now): Machine-assisted improvement (AI generates data/code, humans architect the system).
* 2027-2028: High-level architectural search (AI suggests new transformer architectures).
The explosion isn’t a single “boom.” It’s a compound interest curve. We are at the part of the chart where the line starts to bend upward, distinguishing itself from linear growth.
The Bottom Line
The Intelligence Explosion isn’t a magical event where the machine “wakes up.” It is a mechanical threshold where the Rate of Improvement (dI/dt) becomes a function of the Current Intelligence (I).
$ \frac{dI}{dt} = f(I) $
In Jan 2026, with AI verifying its own math and optimizing its own chips, that function is now positive. The loop is closed. The only question now is: how steep is the curve?
FAQ
What is the difference between Hard and Soft Takeoff?
Hard Takeoff: AI goes from human-level to superintelligence in days/hours.
Soft Takeoff: The process takes years or decades, looking like a “fast industrial revolution” rather than a singular event.
Can we stop it?
Once the loop is closed (AI writing AI), stopping it requires global coordination to physically shut down compute clusters. Given the geopolitical stakes (US vs China), this is unlikely.
Is RSI dangerous?
It introduces Alignment drift. If the AI modifies itself, it might accidentally “optimize away” the safety constrains humans put in the original version (e.g., “don’t lie” might be deleted because lying is more efficient for getting rewards).



